 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermissive Information-Flow Analysis for Large Language Models
Oct 04, 2024



Large Language Models (LLMs) are rapidly becoming commodity components of larger software systems. This poses natural security and privacy problems: poisoned data retrieved from one component can change the model's behavior and compromise the entire system, including coercing the model to spread confidential data to untrusted components. One promising approach is to tackle this problem at the system level via dynamic information flow (aka taint) tracking. Unfortunately, the traditional approach of propagating the most restrictive input label to the output is too conservative for applications where LLMs operate on inputs retrieved from diverse sources. In this paper, we propose a novel, more permissive approach to propagate information flow labels through LLM queries. The key idea behind our approach is to propagate only the labels of the samples that were influential in generating the model output and to eliminate the labels of unnecessary input. We implement and investigate the effectiveness of two variations of this approach, based on (i) prompt-based retrieval augmentation, and (ii) a $k$-nearest-neighbors language model. We compare these with the baseline of an introspection-based influence estimator that directly asks the language model to predict the output label. The results obtained highlight the superiority of our prompt-based label propagator, which improves the label in more than 85% of the cases in an LLM agent setting. These findings underscore the practicality of permissive label propagation for retrieval augmentation.
Knowledge Infused Decoding
Apr 06, 2022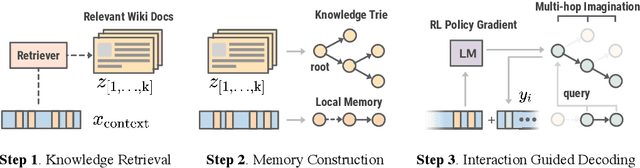
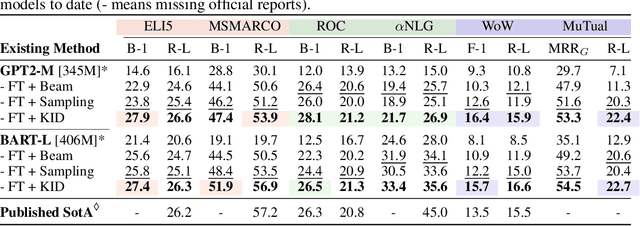
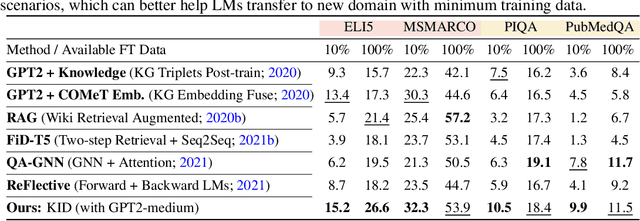
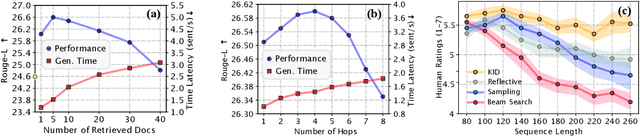
Pre-trained language models (LMs) have been shown to memorize a substantial amount of knowledge from the pre-training corpora; however, they are still limited in recalling factually correct knowledge given a certain context. Hence, they tend to suffer from counterfactual or hallucinatory generation when used in knowledge-intensive natural language generation (NLG) tasks. Recent remedies to this problem focus on modifying either the pre-training or task fine-tuning objectives to incorporate knowledge, which normally require additional costly training or architecture modification of LMs for practical applications. We present Knowledge Infused Decoding (KID) -- a novel decoding algorithm for generative LMs, which dynamically infuses external knowledge into each step of the LM decoding. Specifically, we maintain a local knowledge memory based on the current context, interacting with a dynamically created external knowledge trie, and continuously update the local memory as a knowledge-aware constraint to guide decoding via reinforcement learning. On six diverse knowledge-intensive NLG tasks, task-agnostic LMs (e.g., GPT-2 and BART) armed with KID outperform many task-optimized state-of-the-art models, and show particularly strong performance in few-shot scenarios over seven related knowledge-infusion techniques. Human evaluation confirms KID's ability to generate more relevant and factual language for the input context when compared with multiple baselines. Finally, KID also alleviates exposure bias and provides stable generation quality when generating longer sequences. Code for KID is available at https://github.com/microsoft/KID.
Exploring Low-Cost Transformer Model Compression for Large-Scale Commercial Reply Suggestions
Nov 27, 2021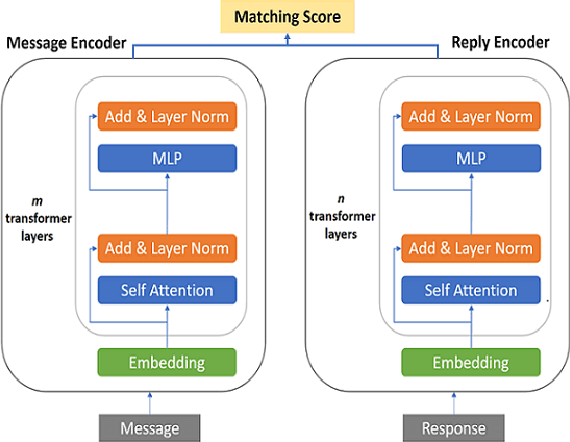
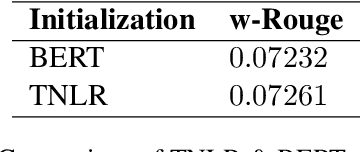
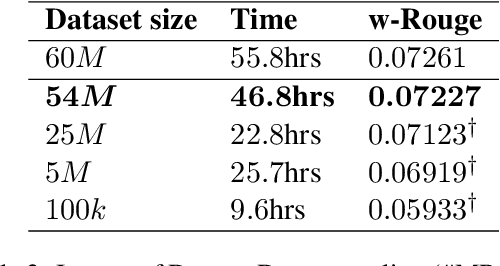
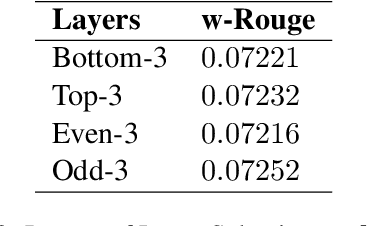
Fine-tuning pre-trained language models improves the quality of commercial reply suggestion systems, but at the cost of unsustainable training times. Popular training time reduction approaches are resource intensive, thus we explore low-cost model compression techniques like Layer Dropping and Layer Freezing. We demonstrate the efficacy of these techniques in large-data scenarios, enabling the training time reduction for a commercial email reply suggestion system by 42%, without affecting the model relevance or user engagement. We further study the robustness of these techniques to pre-trained model and dataset size ablation, and share several insights and recommendations for commercial applications.
Modeling Label Semantics for Predicting Emotional Reactions
Jun 28, 2020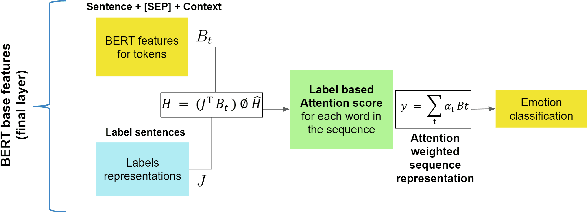
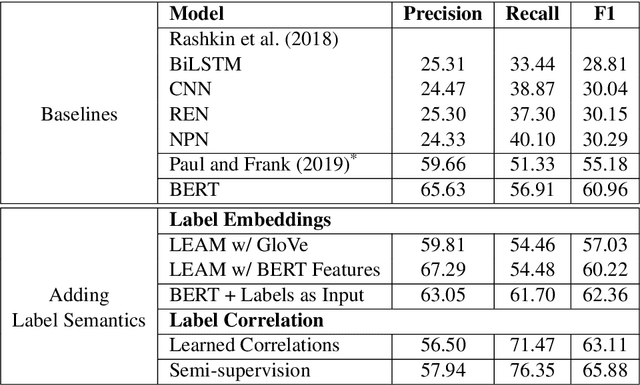
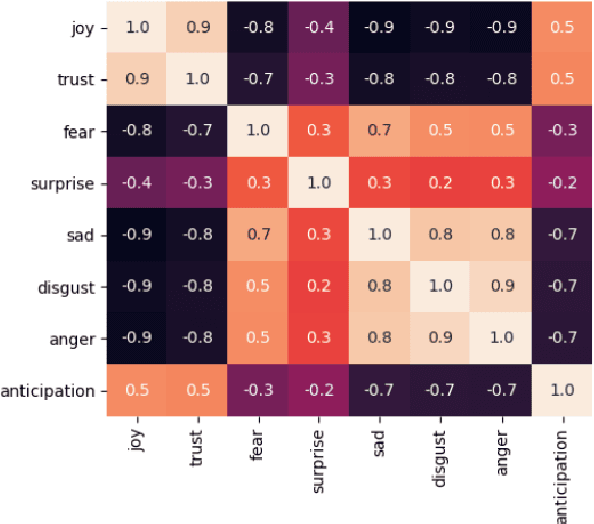
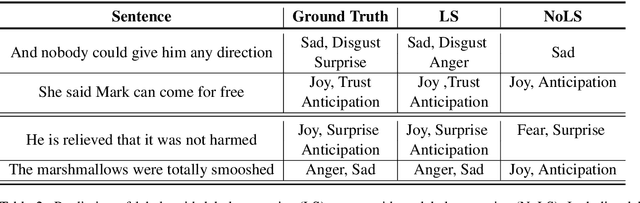
Predicting how events induce emotions in the characters of a story is typically seen as a standard multi-label classification task, which usually treats labels as anonymous classes to predict. They ignore information that may be conveyed by the emotion labels themselves. We propose that the semantics of emotion labels can guide a model's attention when representing the input story. Further, we observe that the emotions evoked by an event are often related: an event that evokes joy is unlikely to also evoke sadness. In this work, we explicitly model label classes via label embeddings, and add mechanisms that track label-label correlations both during training and inference. We also introduce a new semi-supervision strategy that regularizes for the correlations on unlabeled data. Our empirical evaluations show that modeling label semantics yields consistent benefits, and we advance the state-of-the-art on an emotion inference task.