 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decision-Theoretic Formalisation of Steganography With Applications to LLM Monitoring
Feb 26, 2026Large language models are beginning to show steganographic capabilities. Such capabilities could allow misaligned models to evade oversight mechanisms. Yet principled methods to detect and quantify such behaviours are lacking. Classical definitions of steganography, and detection methods based on them, require a known reference distribution of non-steganographic signals. For the case of steganographic reasoning in LLMs, knowing such a reference distribution is not feasible; this renders these approaches inapplicable. We propose an alternative, \textbf{decision-theoretic view of steganography}. Our central insight is that steganography creates an asymmetry in usable information between agents who can and cannot decode the hidden content (present within a steganographic signal), and this otherwise latent asymmetry can be inferred from the agents' observable actions. To formalise this perspective, we introduce generalised $\mathcal{V}$-information: a utilitarian framework for measuring the amount of usable information within some input. We use this to define the \textbf{steganographic gap} -- a measure that quantifies steganography by comparing the downstream utility of the steganographic signal to agents that can and cannot decode the hidden content. We empirically validate our formalism, and show that it can be used to detect, quantify, and mitigate steganographic reasoning in LLMs.
Position: Capability Control Should be a Separate Goal From Alignment
Feb 05, 2026Foundation models are trained on broad data distributions, yielding generalist capabilities that enable many downstream applications but also expand the space of potential misuse and failures. This position paper argues that capability control -- imposing restrictions on permissible model behavior -- should be treated as a distinct goal from alignment. While alignment is often context and preference-driven, capability control aims to impose hard operational limits on permissible behaviors, including under adversarial elicitation. We organize capability control mechanisms across the model lifecycle into three layers: (i) data-based control of the training distribution, (ii) learning-based control via weight- or representation-level interventions, and (iii) system-based control via post-deployment guardrails over inputs, outputs, and actions. Because each layer has characteristic failure modes when used in isolation, we advocate for a defense-in-depth approach that composes complementary controls across the full stack. We further outline key open challenges in achieving such control, including the dual-use nature of knowledge and compositional generalization.
Probabilistic Modelling is Sufficient for Causal Inference
Dec 29, 2025Causal inference is a key research area in machine learning, yet confusion reigns over the tools needed to tackle it. There are prevalent claims in the machine learning literature that you need a bespoke causal framework or notation to answer causal questions. In this paper, we want to make it clear that you \emph{can} answer any causal inference question within the realm of probabilistic modelling and inference, without causal-specific tools or notation. Through concrete examples, we demonstrate how causal questions can be tackled by writing down the probability of everything. Lastly, we reinterpret causal tools as emerging from standard probabilistic modelling and inference, elucidating their necessity and utility.
Language models' activations linearly encode training-order recency
Sep 17, 2025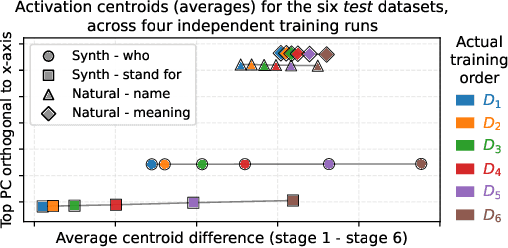



We show that language models' activations linearly encode when information was learned during training. Our setup involves creating a model with a known training order by sequentially fine-tuning Llama-3.2-1B on six disjoint but otherwise similar datasets about named entities. We find that the average activations of test samples for the six training datasets encode the training order: when projected into a 2D subspace, these centroids are arranged exactly in the order of training and lie on a straight line. Further, we show that linear probes can accurately (~90%) distinguish "early" vs. "late" entities, generalizing to entities unseen during the probes' own training. The model can also be fine-tuned to explicitly report an unseen entity's training stage (~80% accuracy). Interestingly, this temporal signal does not seem attributable to simple differences in activation magnitudes, losses, or model confidence. Our paper demonstrates that models are capable of differentiating information by its acquisition time, and carries significant implications for how they might manage conflicting data and respond to knowledge modifications.
Rethinking Safety in LLM Fine-tuning: An Optimization Perspective
Aug 17, 2025Fine-tuning language models is commonly believed to inevitably harm their safety, i.e., refusing to respond to harmful user requests, even when using harmless datasets, thus requiring additional safety measures. We challenge this belief through systematic testing, showing that poor optimization choices, rather than inherent trade-offs, often cause safety problems, measured as harmful responses to adversarial prompts. By properly selecting key training hyper-parameters, e.g., learning rate, batch size, and gradient steps, we reduce unsafe model responses from 16\% to approximately 5\%, as measured by keyword matching, while maintaining utility performance. Based on this observation, we propose a simple exponential moving average (EMA) momentum technique in parameter space that preserves safety performance by creating a stable optimization path and retains the original pre-trained model's safety properties. Our experiments on the Llama families across multiple datasets (Dolly, Alpaca, ORCA) demonstrate that safety problems during fine-tuning can largely be avoided without specialized interventions, outperforming existing approaches that require additional safety data while offering practical guidelines for maintaining both model performance and safety during adaptation.
How Do LLMs Persuade? Linear Probes Can Uncover Persuasion Dynamics in Multi-Turn Conversations
Aug 07, 2025Large Language Models (LLMs) have started to demonstrate the ability to persuade humans, yet our understanding of how this dynamic transpires is limited. Recent work has used linear probes, lightweight tools for analyzing model representations, to study various LLM skills such as the ability to model user sentiment and political perspective. Motivated by this, we apply probes to study persuasion dynamics in natural, multi-turn conversations. We leverage insights from cognitive science to train probes on distinct aspects of persuasion: persuasion success, persuadee personality, and persuasion strategy. Despite their simplicity, we show that they capture various aspects of persuasion at both the sample and dataset levels. For instance, probes can identify the point in a conversation where the persuadee was persuaded or where persuasive success generally occurs across the entire dataset. We also show that in addition to being faster than expensive prompting-based approaches, probes can do just as well and even outperform prompting in some settings, such as when uncovering persuasion strategy. This suggests probes as a plausible avenue for studying other complex behaviours such as deception and manipulation, especially in multi-turn settings and large-scale dataset analysis where prompting-based methods would be computationally inefficient.
Distributional Training Data Attribution
Jun 15, 2025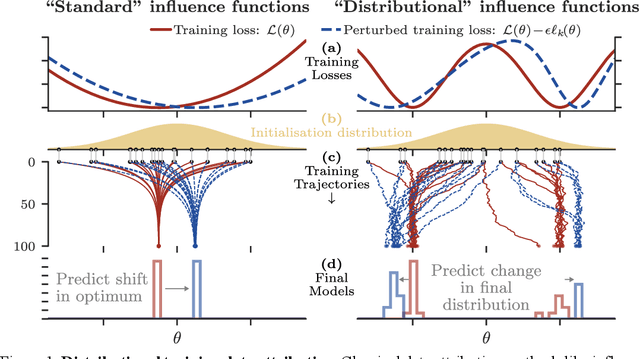
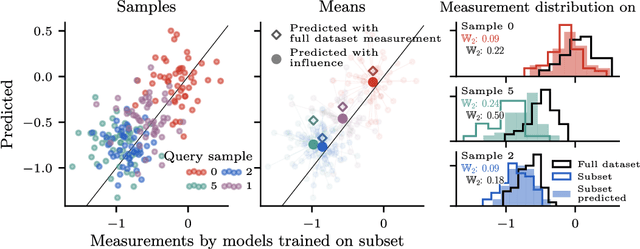
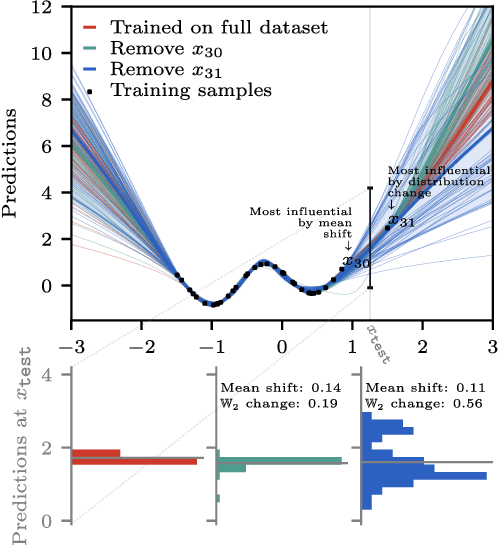
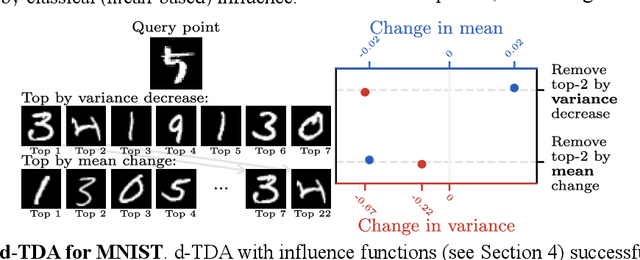
Randomness is an unavoidable part of training deep learning models, yet something that traditional training data attribution algorithms fail to rigorously account for. They ignore the fact that, due to stochasticity in the initialisation and batching, training on the same dataset can yield different models. In this paper, we address this shortcoming through introducing distributional training data attribution (d-TDA), the goal of which is to predict how the distribution of model outputs (over training runs) depends upon the dataset. We demonstrate the practical significance of d-TDA in experiments, e.g. by identifying training examples that drastically change the distribution of some target measurement without necessarily changing the mean. Intriguingly, we also find that influence functions (IFs), a popular but poorly-understood data attribution tool, emerge naturally from our distributional framework as the limit to unrolled differentiation; without requiring restrictive convexity assumptions. This provides a new mathematical motivation for their efficacy in deep learning, and helps to characterise their limitations.
Detecting High-Stakes Interactions with Activation Probes
Jun 12, 2025



Monitoring is an important aspect of safely deploying Large Language Models (LLMs). This paper examines activation probes for detecting "high-stakes" interactions -- where the text indicates that the interaction might lead to significant harm -- as a critical, yet underexplored, target for such monitoring. We evaluate several probe architectures trained on synthetic data, and find them to exhibit robust generalization to diverse, out-of-distribution, real-world data. Probes' performance is comparable to that of prompted or finetuned medium-sized LLM monitors, while offering computational savings of six orders-of-magnitude. Our experiments also highlight the potential of building resource-aware hierarchical monitoring systems, where probes serve as an efficient initial filter and flag cases for more expensive downstream analysis. We release our novel synthetic dataset and codebase to encourage further study.
From Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.
Understanding (Un)Reliability of Steering Vectors in Language Models
May 28, 2025



Steering vectors are a lightweight method to control language model behavior by adding a learned bias to the activations at inference time. Although steering demonstrates promising performance, recent work shows that it can be unreliable or even counterproductive in some cases. This paper studies the influence of prompt types and the geometry of activation differences on steering reliability. First, we find that all seven prompt types used in our experiments produce a net positive steering effect, but exhibit high variance across samples, and often give an effect opposite of the desired one. No prompt type clearly outperforms the others, and yet the steering vectors resulting from the different prompt types often differ directionally (as measured by cosine similarity). Second, we show that higher cosine similarity between training set activation differences predicts more effective steering. Finally, we observe that datasets where positive and negative activations are better separated are more steerable. Our results suggest that vector steering is unreliable when the target behavior is not represented by a coherent direction.