 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.
Redirection for Erasing Memory (REM): Towards a universal unlearning method for corrupted data
May 23, 2025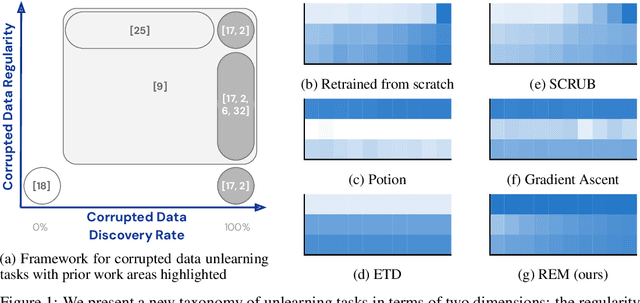
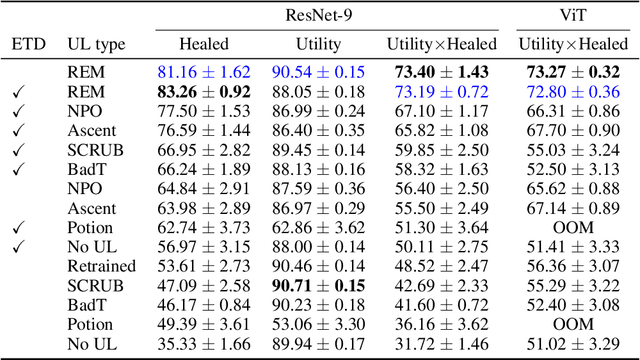
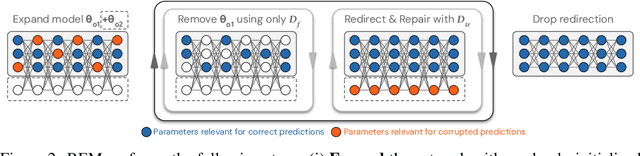

Machine unlearning is studied for a multitude of tasks, but specialization of unlearning methods to particular tasks has made their systematic comparison challenging. To address this issue, we propose a conceptual space to characterize diverse corrupted data unlearning tasks in vision classifiers. This space is described by two dimensions, the discovery rate (the fraction of the corrupted data that are known at unlearning time) and the statistical regularity of the corrupted data (from random exemplars to shared concepts). Methods proposed previously have been targeted at portions of this space and-we show-fail predictably outside these regions. We propose a novel method, Redirection for Erasing Memory (REM), whose key feature is that corrupted data are redirected to dedicated neurons introduced at unlearning time and then discarded or deactivated to suppress the influence of corrupted data. REM performs strongly across the space of tasks, in contrast to prior SOTA methods that fail outside the regions for which they were designed.
Improving Discrete Optimisation Via Decoupled Straight-Through Gumbel-Softmax
Oct 17, 2024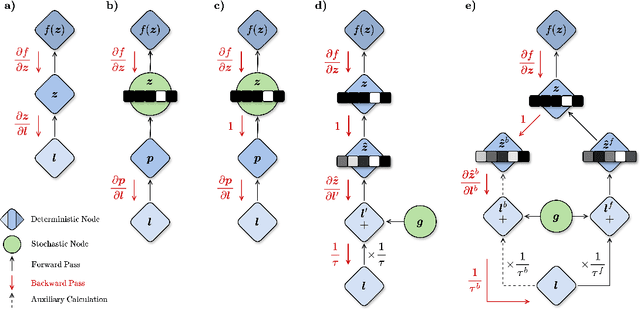

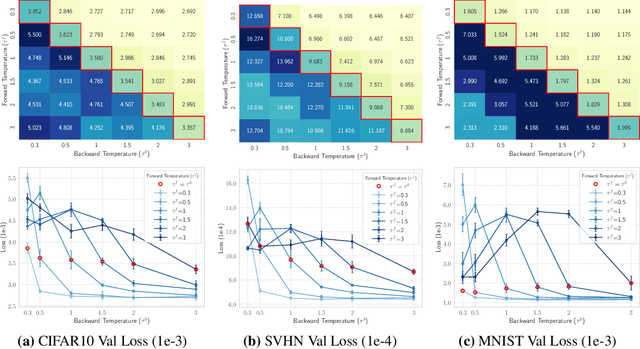
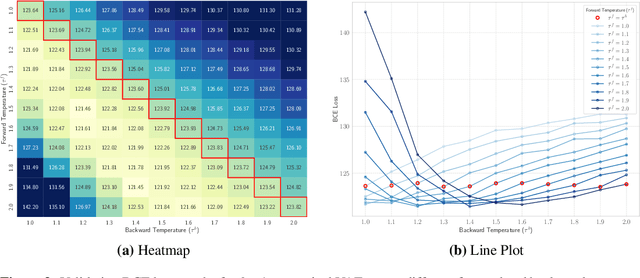
Discrete representations play a crucial role in many deep learning architectures, yet their non-differentiable nature poses significant challenges for gradient-based optimization. To address this issue, various gradient estimators have been developed, including the Straight-Through Gumbel-Softmax (ST-GS) estimator, which combines the Straight-Through Estimator (STE) and the Gumbel-based reparameterization trick. However, the performance of ST-GS is highly sensitive to temperature, with its selection often compromising gradient fidelity. In this work, we propose a simple yet effective extension to ST-GS by employing decoupled temperatures for forward and backward passes, which we refer to as "Decoupled ST-GS". We show that our approach significantly enhances the original ST-GS through extensive experiments across multiple tasks and datasets. We further investigate the impact of our method on gradient fidelity from multiple perspectives, including the gradient gap and the bias-variance trade-off of estimated gradients. Our findings contribute to the ongoing effort to improve discrete optimization in deep learning, offering a practical solution that balances simplicity and effectiveness.
Recurrent Complex-Weighted Autoencoders for Unsupervised Object Discovery
May 28, 2024


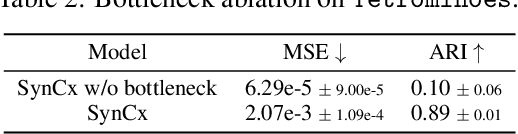
Current state-of-the-art synchrony-based models encode object bindings with complex-valued activations and compute with real-valued weights in feedforward architectures. We argue for the computational advantages of a recurrent architecture with complex-valued weights. We propose a fully convolutional autoencoder, SynCx, that performs iterative constraint satisfaction: at each iteration, a hidden layer bottleneck encodes statistically regular configurations of features in particular phase relationships; over iterations, local constraints propagate and the model converges to a globally consistent configuration of phase assignments. Binding is achieved simply by the matrix-vector product operation between complex-valued weights and activations, without the need for additional mechanisms that have been incorporated into current synchrony-based models. SynCx outperforms or is strongly competitive with current models for unsupervised object discovery. SynCx also avoids certain systematic grouping errors of current models, such as the inability to separate similarly colored objects without additional supervision.
Discrete-Valued Neural Communication
Jul 10, 2021

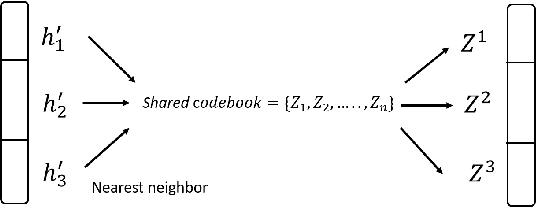
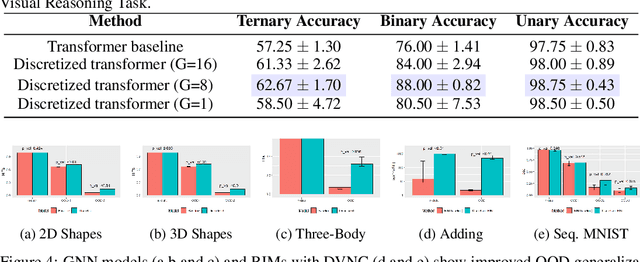
Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.