 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing JEPAs with Spatial Conditioning: Robust and Efficient Representation Learning
Oct 14, 2024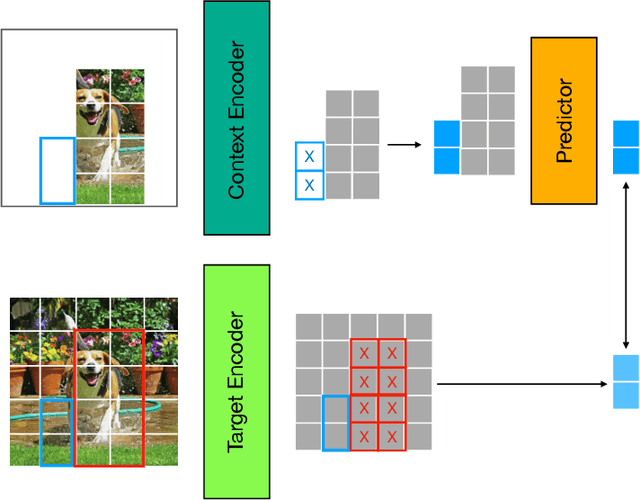
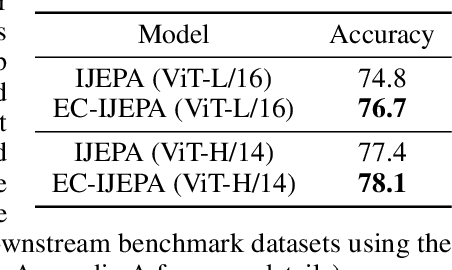
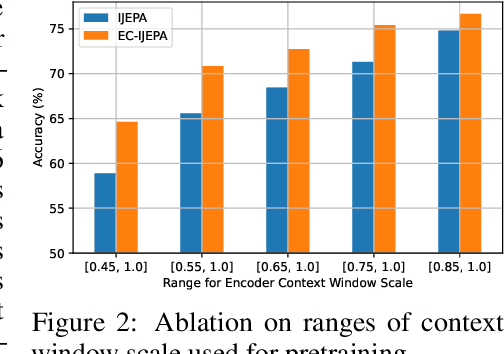
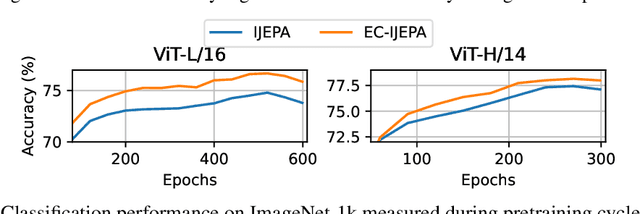
Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework. IJEPA drives representations to capture useful semantic information by predicting in latent rather than input space. However, IJEPA relies on carefully designed context and target windows to avoid representational collapse. The encoder modules in IJEPA cannot adaptively modulate the type of predicted and/or target features based on the feasibility of the masked prediction task as they are not given sufficient information of both context and targets. Based on the intuition that in natural images, information has a strong spatial bias with spatially local regions being highly predictive of one another compared to distant ones. We condition the target encoder and context encoder modules in IJEPA with positions of context and target windows respectively. Our "conditional" encoders show performance gains on several image classification benchmark datasets, improved robustness to context window size and sample-efficiency during pretraining.
Recurrent Complex-Weighted Autoencoders for Unsupervised Object Discovery
May 28, 2024


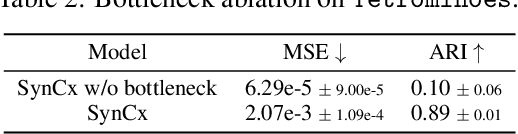
Current state-of-the-art synchrony-based models encode object bindings with complex-valued activations and compute with real-valued weights in feedforward architectures. We argue for the computational advantages of a recurrent architecture with complex-valued weights. We propose a fully convolutional autoencoder, SynCx, that performs iterative constraint satisfaction: at each iteration, a hidden layer bottleneck encodes statistically regular configurations of features in particular phase relationships; over iterations, local constraints propagate and the model converges to a globally consistent configuration of phase assignments. Binding is achieved simply by the matrix-vector product operation between complex-valued weights and activations, without the need for additional mechanisms that have been incorporated into current synchrony-based models. SynCx outperforms or is strongly competitive with current models for unsupervised object discovery. SynCx also avoids certain systematic grouping errors of current models, such as the inability to separate similarly colored objects without additional supervision.
Unsupervised Musical Object Discovery from Audio
Nov 14, 2023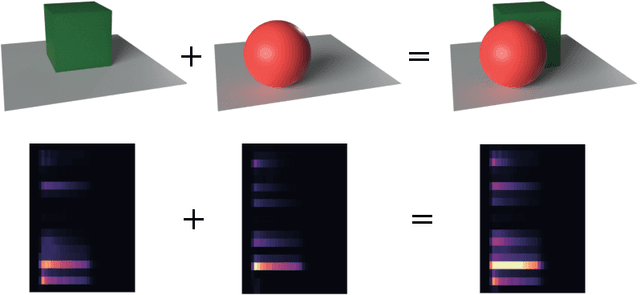

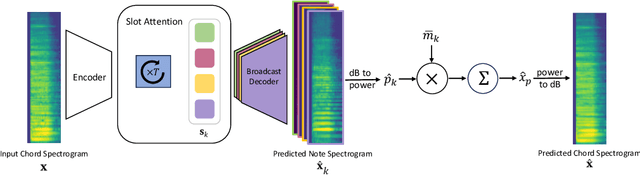
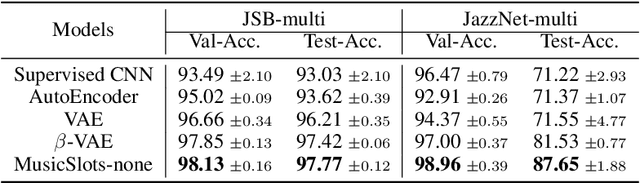
Current object-centric learning models such as the popular SlotAttention architecture allow for unsupervised visual scene decomposition. Our novel MusicSlots method adapts SlotAttention to the audio domain, to achieve unsupervised music decomposition. Since concepts of opacity and occlusion in vision have no auditory analogues, the softmax normalization of alpha masks in the decoders of visual object-centric models is not well-suited for decomposing audio objects. MusicSlots overcomes this problem. We introduce a spectrogram-based multi-object music dataset tailored to evaluate object-centric learning on western tonal music. MusicSlots achieves good performance on unsupervised note discovery and outperforms several established baselines on supervised note property prediction tasks.
Exploring the Promise and Limits of Real-Time Recurrent Learning
May 30, 2023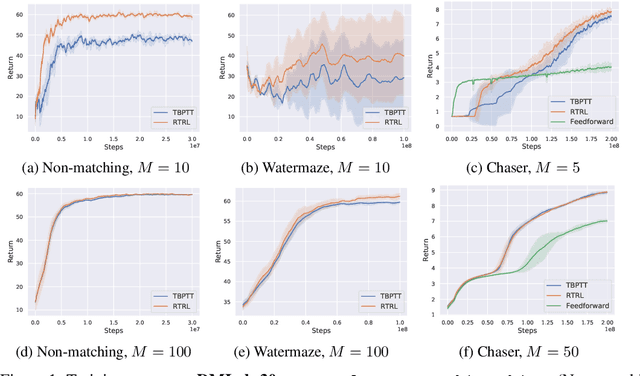

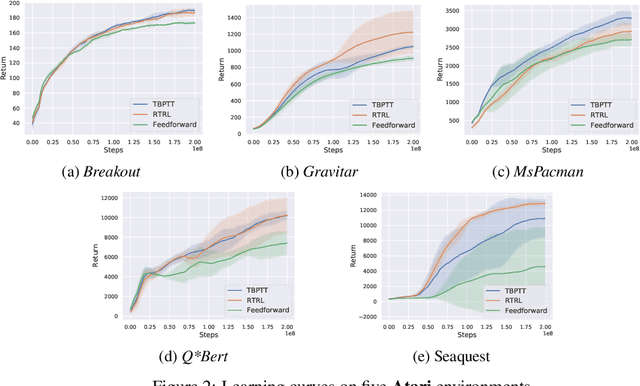

Real-time recurrent learning (RTRL) for sequence-processing recurrent neural networks (RNNs) offers certain conceptual advantages over backpropagation through time (BPTT). RTRL requires neither caching past activations nor truncating context, and enables online learning. However, RTRL's time and space complexity make it impractical. To overcome this problem, most recent work on RTRL focuses on approximation theories, while experiments are often limited to diagnostic settings. Here we explore the practical promise of RTRL in more realistic settings. We study actor-critic methods that combine RTRL and policy gradients, and test them in several subsets of DMLab-30, ProcGen, and Atari-2600 environments. On DMLab memory tasks, our system trained on fewer than 1.2 B environmental frames is competitive with or outperforms well-known IMPALA and R2D2 baselines trained on 10 B frames. To scale to such challenging tasks, we focus on certain well-known neural architectures with element-wise recurrence, allowing for tractable RTRL without approximation. We also discuss rarely addressed limitations of RTRL in real-world applications, such as its complexity in the multi-layer case.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 25, 2023



Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
Unsupervised Learning of Temporal Abstractions with Slot-based Transformers
Mar 25, 2022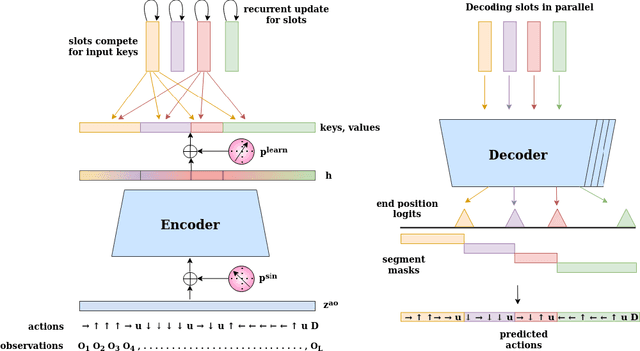

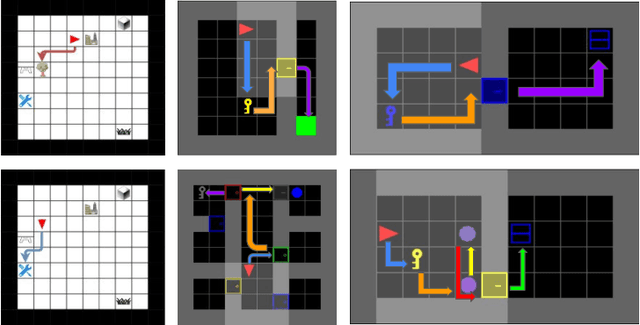
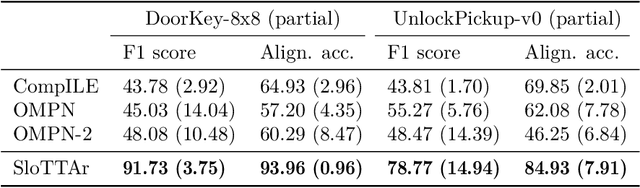
The discovery of reusable sub-routines simplifies decision-making and planning in complex reinforcement learning problems. Previous approaches propose to learn such temporal abstractions in a purely unsupervised fashion through observing state-action trajectories gathered from executing a policy. However, a current limitation is that they process each trajectory in an entirely sequential manner, which prevents them from revising earlier decisions about sub-routine boundary points in light of new incoming information. In this work we propose SloTTAr, a fully parallel approach that integrates sequence processing Transformers with a Slot Attention module and adaptive computation for learning about the number of such sub-routines in an unsupervised fashion. We demonstrate how SloTTAr is capable of outperforming strong baselines in terms of boundary point discovery, even for sequences containing variable amounts of sub-routines, while being up to 7x faster to train on existing benchmarks.
Unsupervised Object Keypoint Learning using Local Spatial Predictability
Nov 25, 2020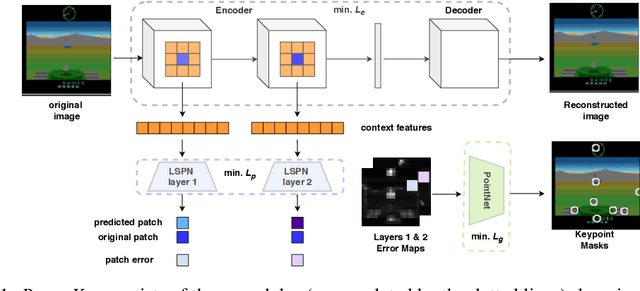
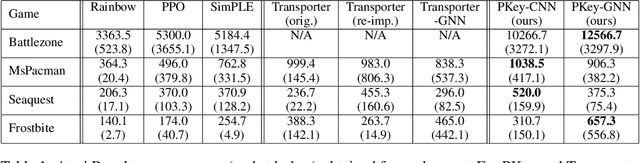


We propose PermaKey, a novel approach to representation learning based on object keypoints. It leverages the predictability of local image regions from spatial neighborhoods to identify salient regions that correspond to object parts, which are then converted to keypoints. Unlike prior approaches, it utilizes predictability to discover object keypoints, an intrinsic property of objects. This ensures that it does not overly bias keypoints to focus on characteristics that are not unique to objects, such as movement, shape, colour etc. We demonstrate the efficacy of PermaKey on Atari where it learns keypoints corresponding to the most salient object parts and is robust to certain visual distractors. Further, on downstream RL tasks in the Atari domain we demonstrate how agents equipped with our keypoints outperform those using competing alternatives, even on challenging environments with moving backgrounds or distractor objects.
A Neural Temporal Model for Human Motion Prediction
Sep 14, 2018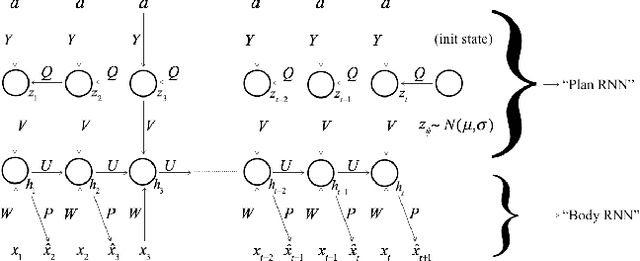


We propose novel neural temporal models for short-term motion prediction and long-term human motion synthesis, achieving state-of-art predictive performance while being computationally less expensive compared to previously proposed approaches. Key aspects of our proposed system include: 1) a novel, two-level processing architecture that aids in generating planned trajectories, 2) a simple set of easily computable features that integrate simple derivative information into the model, and 3) a novel multi-objective loss function that helps the model to slowly progress from the simpler task of next-step prediction to the harder task of multi-step closed-loop prediction. Our results demonstrate that these innovations are shown to facilitate improved modeling of long-term motion trajectories. Finally, we propose a novel metric called Power Spectrum Similarity (NPSS) to evaluate the long-term predictive ability of our trained motion synthesis models, circumventing many of the shortcomings of the popular mean-squared error measure of the Euler angles of joints over time.