 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Temporal Model for Human Motion Prediction
Sep 14, 2018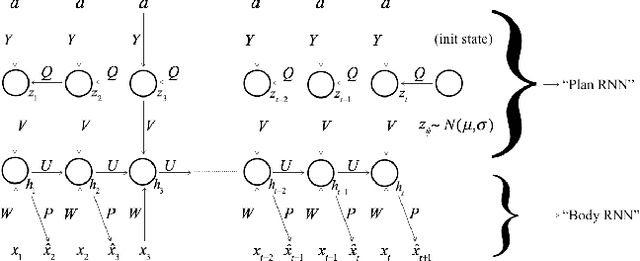

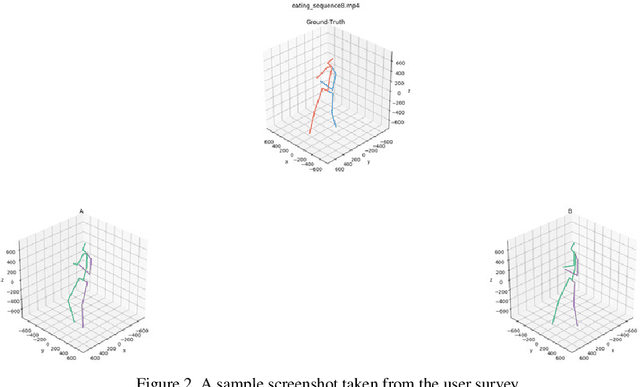

We propose novel neural temporal models for short-term motion prediction and long-term human motion synthesis, achieving state-of-art predictive performance while being computationally less expensive compared to previously proposed approaches. Key aspects of our proposed system include: 1) a novel, two-level processing architecture that aids in generating planned trajectories, 2) a simple set of easily computable features that integrate simple derivative information into the model, and 3) a novel multi-objective loss function that helps the model to slowly progress from the simpler task of next-step prediction to the harder task of multi-step closed-loop prediction. Our results demonstrate that these innovations are shown to facilitate improved modeling of long-term motion trajectories. Finally, we propose a novel metric called Power Spectrum Similarity (NPSS) to evaluate the long-term predictive ability of our trained motion synthesis models, circumventing many of the shortcomings of the popular mean-squared error measure of the Euler angles of joints over time.
Smart Library: Identifying Books in a Library using Richly Supervised Deep Scene Text Reading
Nov 22, 2016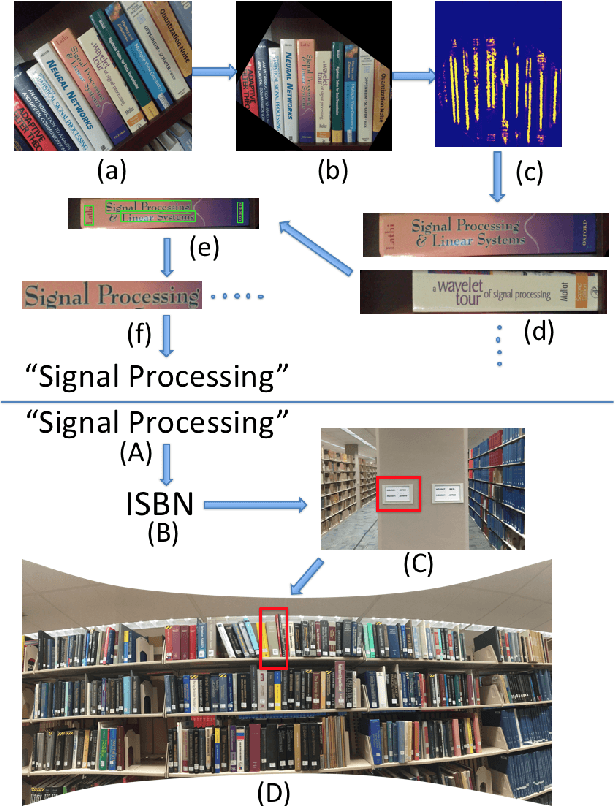
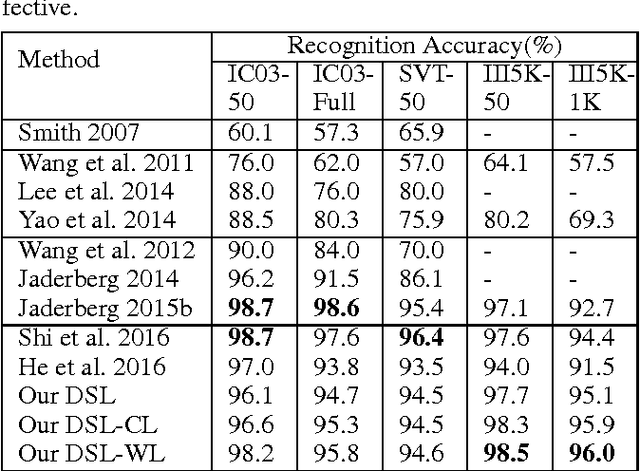
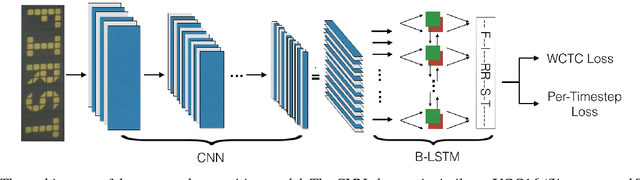

Physical library collections are valuable and long standing resources for knowledge and learning. However, managing books in a large bookshelf and finding books on it often leads to tedious manual work, especially for large book collections where books might be missing or misplaced. Recently, deep neural models, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) have achieved great success for scene text detection and recognition. Motivated by these recent successes, we aim to investigate their viability in facilitating book management, a task that introduces further challenges including large amounts of cluttered scene text, distortion, and varied lighting conditions. In this paper, we present a library inventory building and retrieval system based on scene text reading methods. We specifically design our scene text recognition model using rich supervision to accelerate training and achieve state-of-the-art performance on several benchmark datasets. Our proposed system has the potential to greatly reduce the amount of human labor required in managing book inventories as well as the space needed to store book information.
A Simple Baseline for Travel Time Estimation using Large-Scale Trip Data
Dec 28, 2015
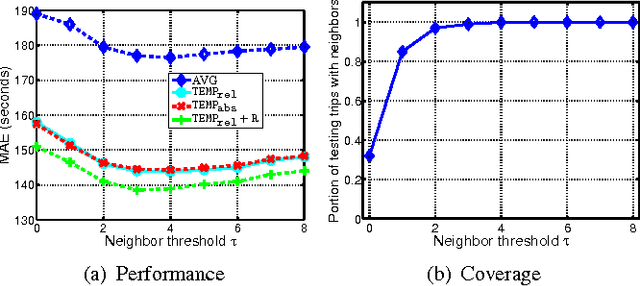
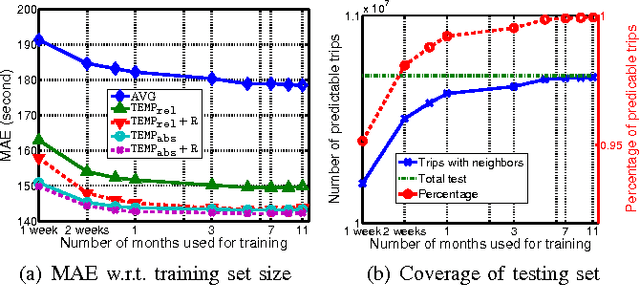
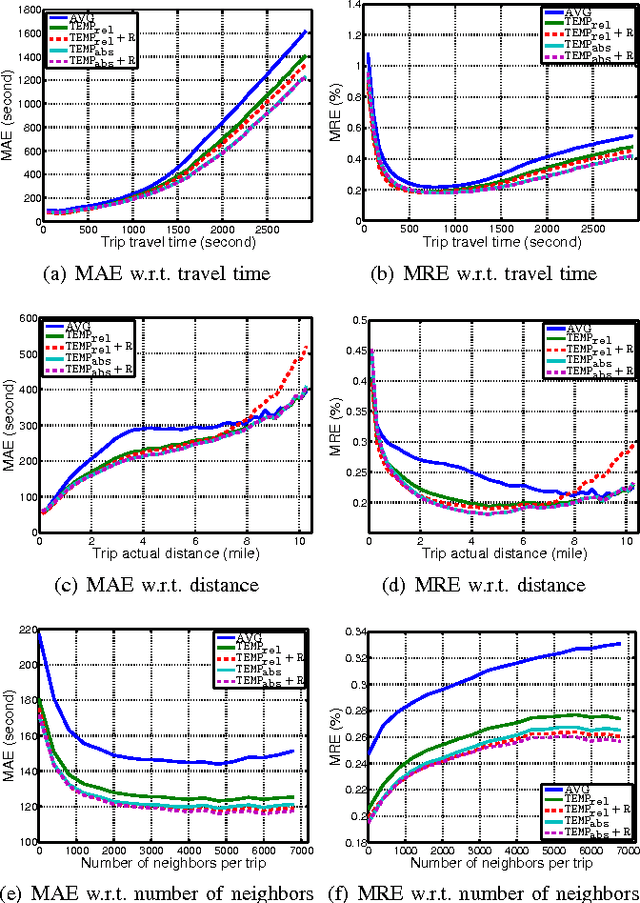
The increased availability of large-scale trajectory data around the world provides rich information for the study of urban dynamics. For example, New York City Taxi Limousine Commission regularly releases source-destination information about trips in the taxis they regulate. Taxi data provide information about traffic patterns, and thus enable the study of urban flow -- what will traffic between two locations look like at a certain date and time in the future? Existing big data methods try to outdo each other in terms of complexity and algorithmic sophistication. In the spirit of "big data beats algorithms", we present a very simple baseline which outperforms state-of-the-art approaches, including Bing Maps and Baidu Maps (whose APIs permit large scale experimentation). Such a travel time estimation baseline has several important uses, such as navigation (fast travel time estimates can serve as approximate heuristics for A search variants for path finding) and trip planning (which uses operating hours for popular destinations along with travel time estimates to create an itinerary).
Private Posterior distributions from Variational approximations
Nov 24, 2015

Privacy preserving mechanisms such as differential privacy inject additional randomness in the form of noise in the data, beyond the sampling mechanism. Ignoring this additional noise can lead to inaccurate and invalid inferences. In this paper, we incorporate the privacy mechanism explicitly into the likelihood function by treating the original data as missing, with an end goal of estimating posterior distributions over model parameters. This leads to a principled way of performing valid statistical inference using private data, however, the corresponding likelihoods are intractable. In this paper, we derive fast and accurate variational approximations to tackle such intractable likelihoods that arise due to privacy. We focus on estimating posterior distributions of parameters of the naive Bayes log-linear model, where the sufficient statistics of this model are shared using a differentially private interface. Using a simulation study, we show that the posterior approximations outperform the naive method of ignoring the noise addition mechanism.