 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide to Tuning Spiking Neuronal Dynamics
Jun 09, 2025



In this work, we examine fundamental elements of spiking neural networks (SNNs) as well as how to tune them. Concretely, we focus on two different foundational neuronal units utilized in SNNs -- the leaky integrate-and-fire (LIF) and the resonate-and-fire (RAF) neuron. We explore key equations and how hyperparameter values affect behavior. Beyond hyperparameters, we discuss other important design elements of SNNs -- the choice of input encoding and the setup for excitatory-inhibitory populations -- and how these impact LIF and RAF dynamics.
Predicted Embedding Power Regression for Large-Scale Out-of-Distribution Detection
Mar 14, 2023



Out-of-distribution (OOD) inputs can compromise the performance and safety of real world machine learning systems. While many methods exist for OOD detection and work well on small scale datasets with lower resolution and few classes, few methods have been developed for large-scale OOD detection. Existing large-scale methods generally depend on maximum classification probability, such as the state-of-the-art grouped softmax method. In this work, we develop a novel approach that calculates the probability of the predicted class label based on label distributions learned during the training process. Our method performs better than current state-of-the-art methods with only a negligible increase in compute cost. We evaluate our method against contemporary methods across $14$ datasets and achieve a statistically significant improvement with respect to AUROC (84.2 vs 82.4) and AUPR (96.2 vs 93.7).
A Robust Backpropagation-Free Framework for Images
Jun 03, 2022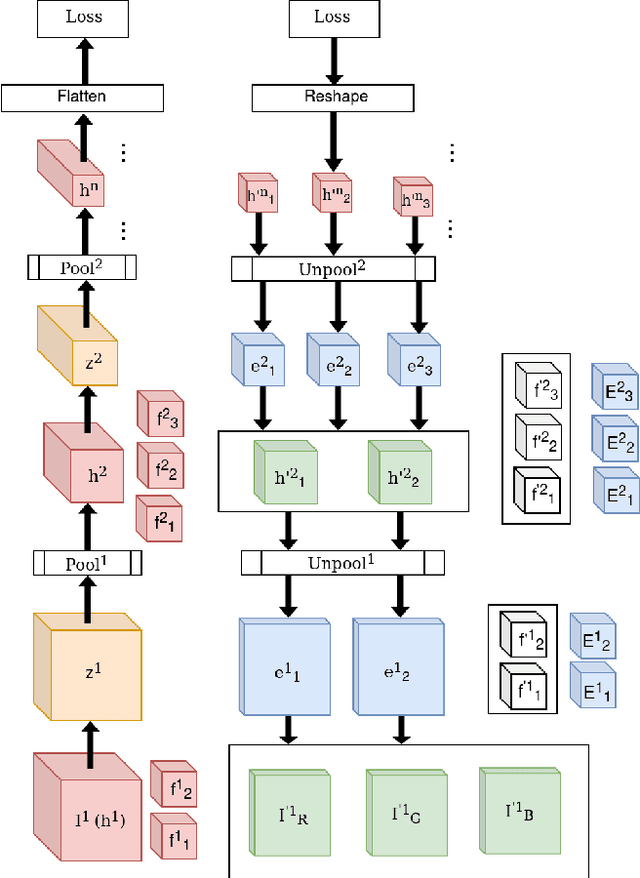
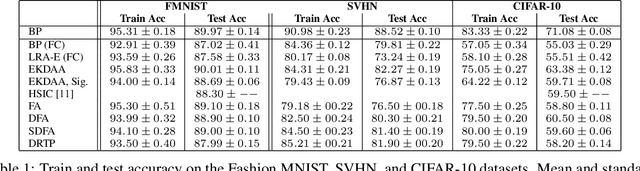
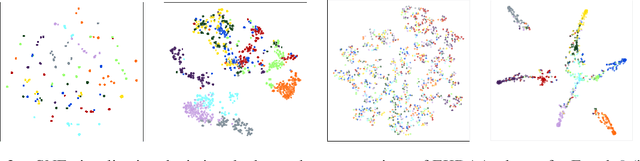
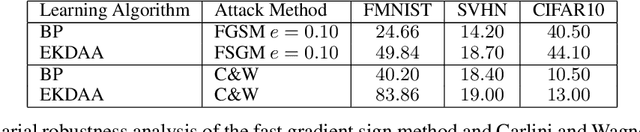
While current deep learning algorithms have been successful for a wide variety of artificial intelligence (AI) tasks, including those involving structured image data, they present deep neurophysiological conceptual issues due to their reliance on the gradients computed by backpropagation of errors (backprop) to obtain synaptic weight adjustments; hence are biologically implausible. We present a more biologically plausible approach, the error-kernel driven activation alignment (EKDAA) algorithm, to train convolution neural networks (CNNs) using locally derived error transmission kernels and error maps. We demonstrate the efficacy of EKDAA by performing the task of visual-recognition on the Fashion MNIST, CIFAR-10 and SVHN benchmarks as well as conducting blackbox robustness tests on adversarial examples derived from these datasets. Furthermore, we also present results for a CNN trained using a non-differentiable activation function. All recognition results nearly matches that of backprop and exhibit greater adversarial robustness compared to backprop.
Continual Competitive Memory: A Neural System for Online Task-Free Lifelong Learning
Jun 24, 2021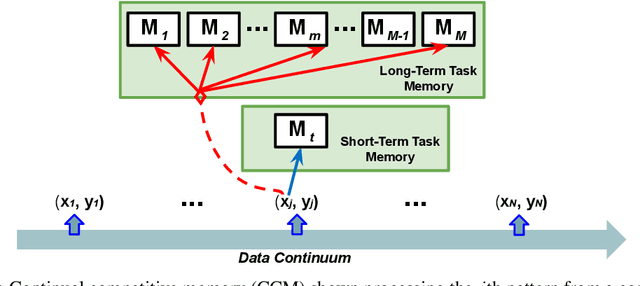
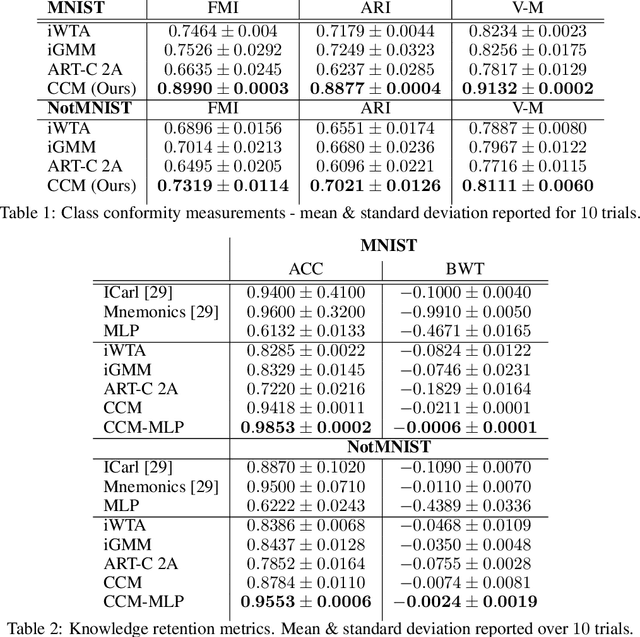

In this article, we propose a novel form of unsupervised learning, continual competitive memory (CCM), as well as a computational framework to unify related neural models that operate under the principles of competition. The resulting neural system is shown to offer an effective approach for combating catastrophic forgetting in online continual classification problems. We demonstrate that the proposed CCM system not only outperforms other competitive learning neural models but also yields performance that is competitive with several modern, state-of-the-art lifelong learning approaches on benchmarks such as Split MNIST and Split NotMNIST. CCM yields a promising path forward for acquiring representations that are robust to interference from data streams, especially when the task is unknown to the model and must be inferred without external guidance.
Improving Label Quality by Jointly Modeling Items and Annotators
Jun 20, 2021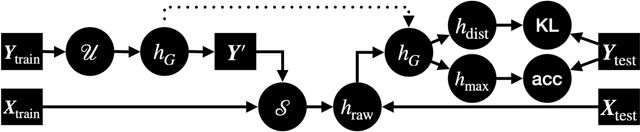

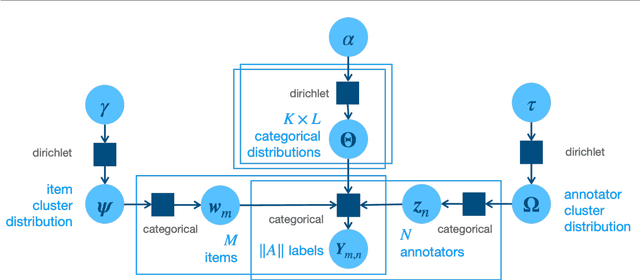
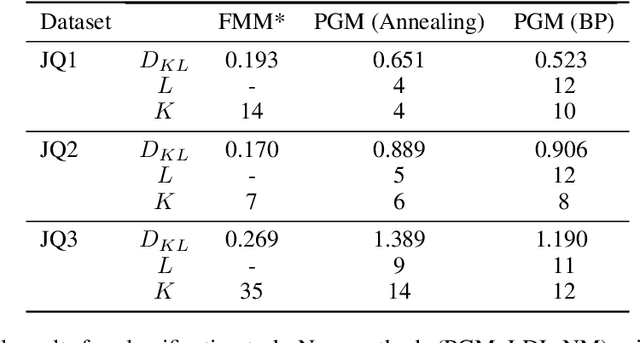
We propose a fully Bayesian framework for learning ground truth labels from noisy annotators. Our framework ensures scalability by factoring a generative, Bayesian soft clustering model over label distributions into the classic David and Skene joint annotator-data model. Earlier research along these lines has neither fully incorporated label distributions nor explored clustering by annotators only or data only. Our framework incorporates all of these properties as: (1) a graphical model designed to provide better ground truth estimates of annotator responses as input to \emph{any} black box supervised learning algorithm, and (2) a standalone neural model whose internal structure captures many of the properties of the graphical model. We conduct supervised learning experiments using both models and compare them to the performance of one baseline and a state-of-the-art model.
Sibling Neural Estimators: Improving Iterative Image Decoding with Gradient Communication
Nov 20, 2019

For lossy image compression, we develop a neural-based system which learns a nonlinear estimator for decoding from quantized representations. The system links two recurrent networks that \help" each other reconstruct same target image patches using complementary portions of spatial context that communicate via gradient signals. This dual agent system builds upon prior work that proposed the iterative refinement algorithm for recurrent neural network (RNN)based decoding which improved image reconstruction compared to standard decoding techniques. Our approach, which works with any encoder, neural or non-neural, This system progressively reduces image patch reconstruction error over a fixed number of steps. Experiment with variants of RNN memory cells, with and without future information, find that our model consistently creates lower distortion images of higher perceptual quality compared to other approaches. Specifically, on the Kodak Lossless True Color Image Suite, we observe as much as a 1:64 decibel (dB) gain over JPEG, a 1:46 dB gain over JPEG 2000, a 1:34 dB gain over the GOOG neural baseline, 0:36 over E2E (a modern competitive neural compression model), and 0:37 over a single iterative neural decoder.
The Ant Swarm Neuro-Evolution Procedure for Optimizing Recurrent Networks
Sep 27, 2019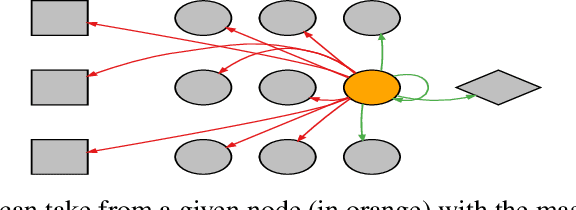
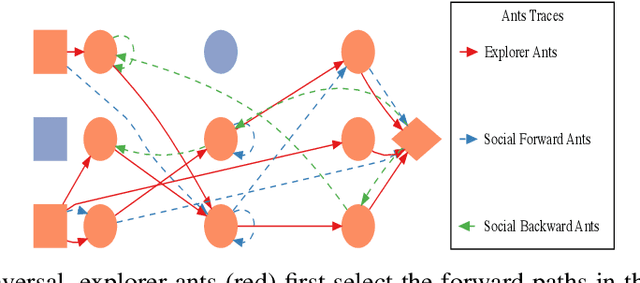
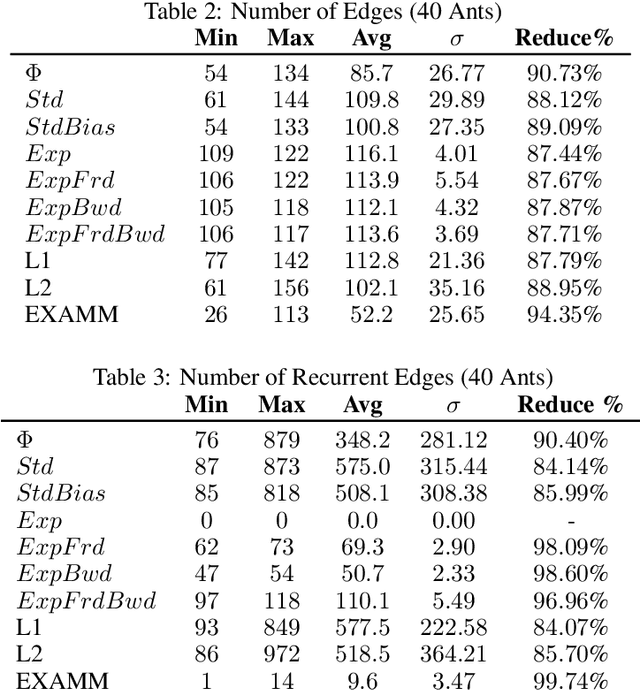
Hand-crafting effective and efficient structures for recurrent neural networks (RNNs) is a difficult, expensive, and time-consuming process. To address this challenge, we propose a novel neuro-evolution algorithm based on ant colony optimization (ACO), called ant swarm neuro-evolution (ASNE), for directly optimizing RNN topologies. The procedure selects from multiple modern recurrent cell types such as Delta-RNN, GRU, LSTM, MGU and UGRNN cells, as well as recurrent connections which may span multiple layers and/or steps of time. In order to introduce an inductive bias that encourages the formation of sparser synaptic connectivity patterns, we investigate several variations of the core algorithm. We do so primarily by formulating different functions that drive the underlying pheromone simulation process (which mimic L1 and L2 regularization in standard machine learning) as well as by introducing ant agents with specialized roles (inspired by how real ant colonies operate), i.e., explorer ants that construct the initial feed forward structure and social ants which select nodes from the feed forward connections to subsequently craft recurrent memory structures. We also incorporate a Lamarckian strategy for weight initialization which reduces the number of backpropagation epochs required to locally train candidate RNNs, speeding up the neuro-evolution process. Our results demonstrate that the sparser RNNs evolved by ASNE significantly outperform traditional one and two layer architectures consisting of modern memory cells, as well as the well-known NEAT algorithm. Furthermore, we improve upon prior state-of-the-art results on the time series dataset utilized in our experiments.
An Empirical Exploration of Deep Recurrent Connections and Memory Cells Using Neuro-Evolution
Sep 27, 2019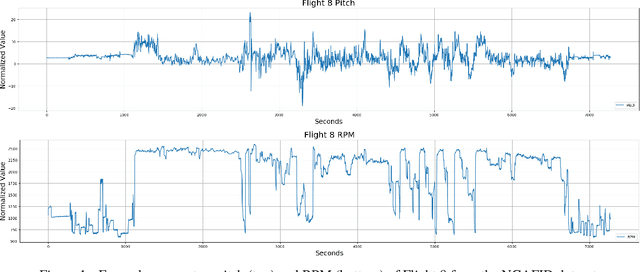
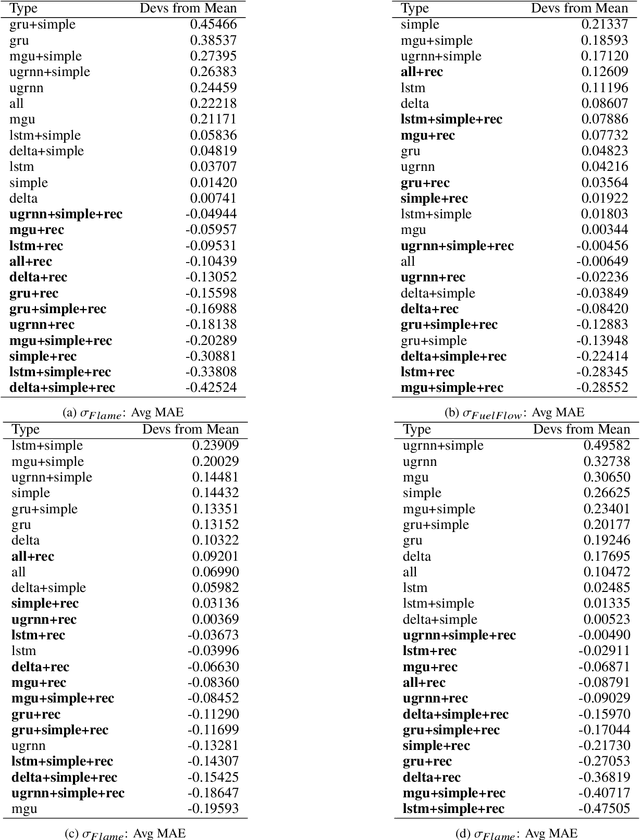
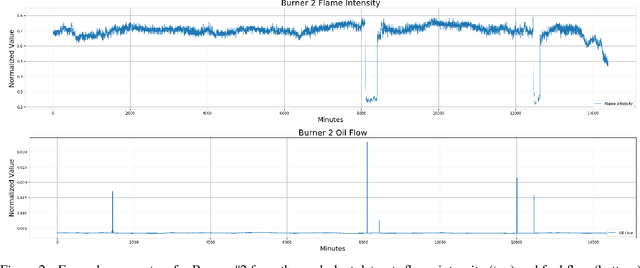
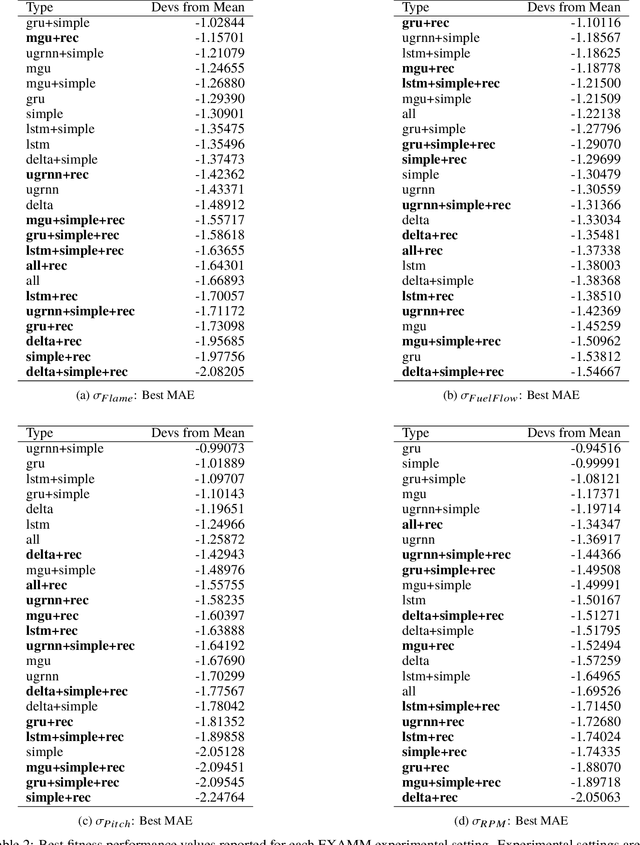
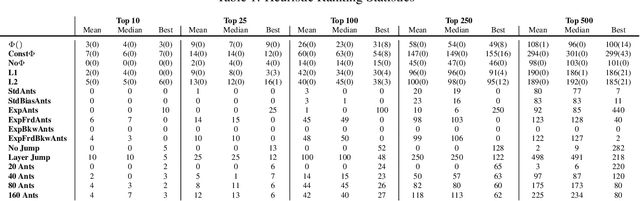
Neuro-evolution and neural architecture search algorithms have gained increasing interest due to the challenges involved in designing optimal artificial neural networks (ANNs). While these algorithms have been shown to possess the potential to outperform the best human crafted architectures, a less common use of them is as a tool for analysis of ANN structural components and connectivity structures. In this work, we focus on this particular use-case to develop a rigorous examination and comparison framework for analyzing recurrent neural networks (RNNs) applied to time series prediction using the novel neuro-evolutionary process known as Evolutionary eXploration of Augmenting Memory Models (EXAMM). Specifically, we use our EXAMM-based analysis to investigate the capabilities of recurrent memory cells and the generalization ability afforded by various complex recurrent connectivity patterns that span one or more steps in time, i.e., deep recurrent connections. EXAMM, in this study, was used to train over 10.56 million RNNs in 5,280 repeated experiments with varying components. While many modern, often hand-crafted RNNs rely on complex memory cells (which have internal recurrent connections that only span a single time step) operating under the assumption that these sufficiently latch information and handle long term dependencies, our results show that networks evolved with deep recurrent connections perform significantly better than those without. More importantly, in some cases, the best performing RNNs consisted of only simple neurons and deep time skip connections, without any memory cells. These results strongly suggest that utilizing deep time skip connections in RNNs for time series data prediction not only deserves further, dedicated study, but also demonstrate the potential of neuro-evolution as a means to better study, understand, and train effective RNNs.
A Neural Temporal Model for Human Motion Prediction
Sep 14, 2018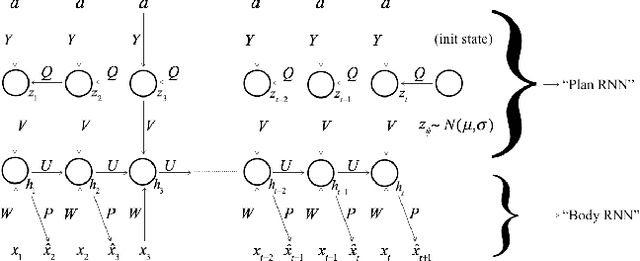


We propose novel neural temporal models for short-term motion prediction and long-term human motion synthesis, achieving state-of-art predictive performance while being computationally less expensive compared to previously proposed approaches. Key aspects of our proposed system include: 1) a novel, two-level processing architecture that aids in generating planned trajectories, 2) a simple set of easily computable features that integrate simple derivative information into the model, and 3) a novel multi-objective loss function that helps the model to slowly progress from the simpler task of next-step prediction to the harder task of multi-step closed-loop prediction. Our results demonstrate that these innovations are shown to facilitate improved modeling of long-term motion trajectories. Finally, we propose a novel metric called Power Spectrum Similarity (NPSS) to evaluate the long-term predictive ability of our trained motion synthesis models, circumventing many of the shortcomings of the popular mean-squared error measure of the Euler angles of joints over time.
Biologically Motivated Algorithms for Propagating Local Target Representations
Sep 06, 2018



Finding biologically plausible alternatives to back-propagation of errors is a fundamentally important challenge in artificial neural network research. In this paper, we propose a simple learning algorithm called error-driven Local Representation Alignment (LRA-E), which has strong connections to predictive coding, a theory that offers a mechanistic way of describing neurocomputational machinery. In addition, we propose an improved variant of Difference Target Propagation, another procedure that comes from the same family of algorithms as Local Representation Alignment. We compare our learning procedures to several other biologically-motivated algorithms, including two feedback alignment algorithms and Equilibrium Propagation. In two benchmark datasets, we find that both of our proposed learning algorithms yield stable performance and strong generalization abilities in comparison to other competing back-propagation alternatives when training deeper, highly nonlinear networks, with LRA-E performing the best overall.