 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023

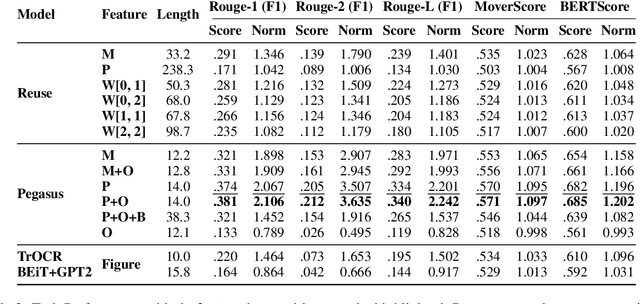
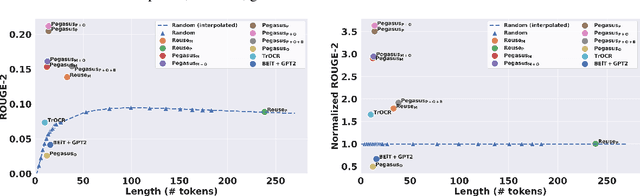
Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.
Extractive Summarizer for Scholarly Articles
Aug 25, 2020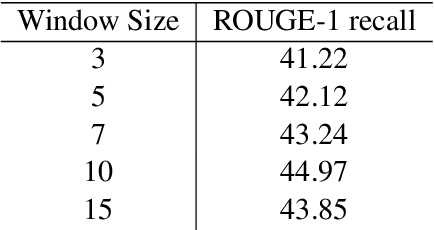
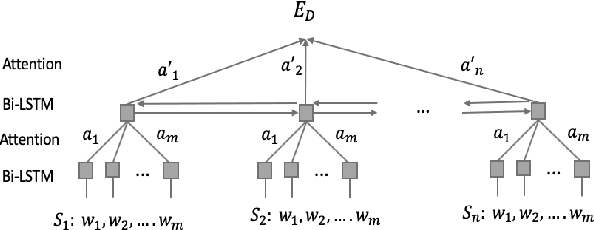

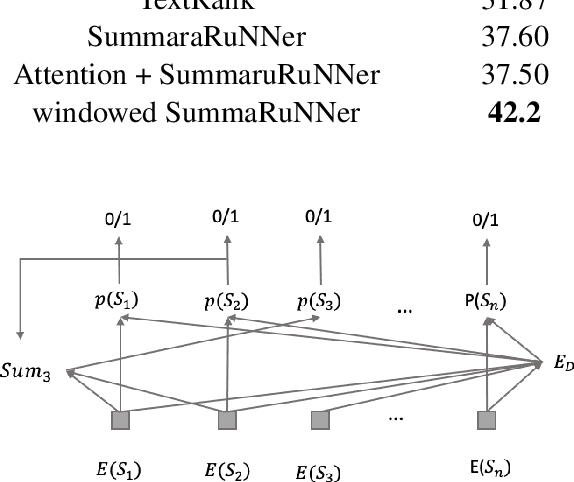
We introduce an extractive method that will summarize long scientific papers. Our model uses presentation slides provided by the authors of the papers as the gold summary standard to label the sentences. The sentences are ranked based on their novelty and their importance as estimated by deep neural networks. Our window-based extractive labeling of sentences results in the improvement of at least 4 ROUGE1-Recall points.
Recognizing Long Grammatical Sequences Using Recurrent Networks Augmented With An External Differentiable Stack
Apr 22, 2020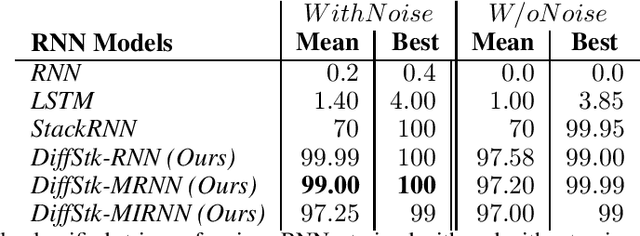
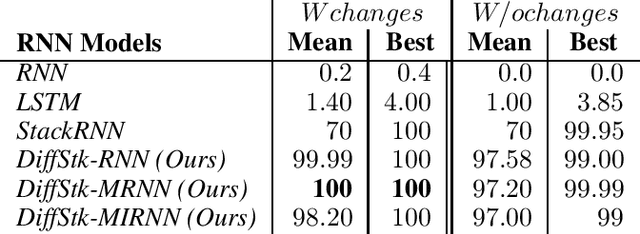
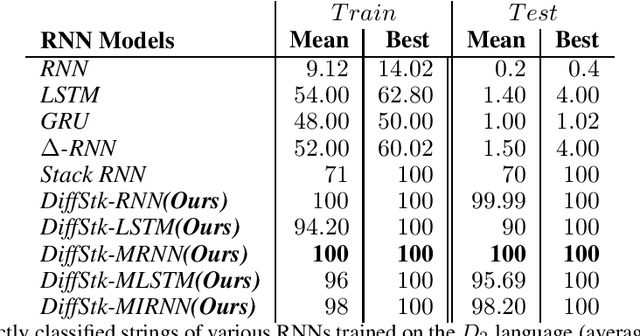

Recurrent neural networks (RNNs) are a widely used deep architecture for sequence modeling, generation, and prediction. Despite success in applications such as machine translation and voice recognition, these stateful models have several critical shortcomings. Specifically, RNNs generalize poorly over very long sequences, which limits their applicability to many important temporal processing and time series forecasting problems. For example, RNNs struggle in recognizing complex context free languages (CFLs), never reaching 100% accuracy on training. One way to address these shortcomings is to couple an RNN with an external, differentiable memory structure, such as a stack. However, differentiable memories in prior work have neither been extensively studied on CFLs nor tested on sequences longer than those seen in training. The few efforts that have studied them have shown that continuous differentiable memory structures yield poor generalization for complex CFLs, making the RNN less interpretable. In this paper, we improve the memory-augmented RNN with important architectural and state updating mechanisms that ensure that the model learns to properly balance the use of its latent states with external memory. Our improved RNN models exhibit better generalization performance and are able to classify long strings generated by complex hierarchical context free grammars (CFGs). We evaluate our models on CGGs, including the Dyck languages, as well as on the Penn Treebank language modelling task, and achieve stable, robust performance across these benchmarks. Furthermore, we show that only our memory-augmented networks are capable of retaining memory for a longer duration up to strings of length 160.
Sibling Neural Estimators: Improving Iterative Image Decoding with Gradient Communication
Nov 20, 2019

For lossy image compression, we develop a neural-based system which learns a nonlinear estimator for decoding from quantized representations. The system links two recurrent networks that \help" each other reconstruct same target image patches using complementary portions of spatial context that communicate via gradient signals. This dual agent system builds upon prior work that proposed the iterative refinement algorithm for recurrent neural network (RNN)based decoding which improved image reconstruction compared to standard decoding techniques. Our approach, which works with any encoder, neural or non-neural, This system progressively reduces image patch reconstruction error over a fixed number of steps. Experiment with variants of RNN memory cells, with and without future information, find that our model consistently creates lower distortion images of higher perceptual quality compared to other approaches. Specifically, on the Kodak Lossless True Color Image Suite, we observe as much as a 1:64 decibel (dB) gain over JPEG, a 1:46 dB gain over JPEG 2000, a 1:34 dB gain over the GOOG neural baseline, 0:36 over E2E (a modern competitive neural compression model), and 0:37 over a single iterative neural decoder.