 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Neurorobot Policy under Limited Demonstration Data through Preference Regret
Apr 04, 2026Robot reinforcement learning from demonstrations (RLfD) assumes that expert data is abundant; this is usually unrealistic in the real world given data scarcity as well as high collection cost. Furthermore, imitation learning algorithms assume that the data is independently and identically distributed, which ultimately results in poorer performance as gradual errors emerge and compound within test-time trajectories. We address these issues by introducing the "master your own expertise" (MYOE) framework, a self-imitation framework that enables robotic agents to learn complex behaviors from limited demonstration data samples. Inspired by human perception and action, we propose and design what we call the queryable mixture-of-preferences state space model (QMoP-SSM), which estimates the desired goal at every time step. These desired goals are used in computing the "preference regret", which is used to optimize the robot control policy. Our experiments demonstrate the robustness, adaptability, and out-of-sample performance of our agent compared to other state-of-the-art RLfD schemes. The GitHub repository that supports this work can be found at: https://github.com/rxng8/neurorobot-preference-regret-learning.
Enhancing Eye Feature Estimation from Event Data Streams through Adaptive Inference State Space Modeling
Mar 14, 2026Eye feature extraction from event-based data streams can be performed efficiently and with low energy consumption, offering great utility to real-world eye tracking pipelines. However, few eye feature extractors are designed to handle sudden changes in event density caused by the changes between gaze behaviors that vary in their kinematics, leading to degraded prediction performance. In this work, we address this problem by introducing the \emph{adaptive inference state space model} (AISSM), a novel architecture for feature extraction that is capable of dynamically adjusting the relative weight placed on current versus recent information. This relative weighting is determined via estimates of the signal-to-noise ratio and event density produced by a complementary \emph{dynamic confidence network}. Lastly, we craft and evaluate a novel learning technique that improves training efficiency. Experimental results demonstrate that the AISSM system outperforms state-of-the-art models for event-based eye feature extraction.
Formulating Reinforcement Learning for Human-Robot Collaboration through Off-Policy Evaluation
Jan 27, 2026Reinforcement learning (RL) has the potential to transform real-world decision-making systems by enabling autonomous agents to learn from experience. Deploying RL in real-world settings, especially in the context of human-robot interaction, requires defining state representations and reward functions, which are critical for learning efficiency and policy performance. Traditional RL approaches often rely on domain expertise and trial-and-error, necessitating extensive human involvement as well as direct interaction with the environment, which can be costly and impractical, especially in complex and safety-critical applications. This work proposes a novel RL framework that leverages off-policy evaluation (OPE) for state space and reward function selection, using only logged interaction data. This approach eliminates the need for real-time access to the environment or human-in-the-loop feedback, greatly reducing the dependency on costly real-time interactions. The proposed approach systematically evaluates multiple candidate state representations and reward functions by training offline RL agents and applying OPE to estimate policy performance. The optimal state space and reward function are selected based on their ability to produce high-performing policies under OPE metrics. Our method is validated on two environments: the Lunar Lander environment by OpenAI Gym, which provides a controlled setting for assessing state space and reward function selection, and a NASA-MATB-II human subjects study environment, which evaluates the approach's real-world applicability to human-robot teaming scenarios. This work enhances the feasibility and scalability of offline RL for real-world environments by automating critical RL design decisions through a data-driven OPE-based evaluation, enabling more reliable, effective, and sustainable RL formulation for complex human-robot interaction settings.
Class Incremental Continual Learning with Self-Organizing Maps and Variational Autoencoders Using Synthetic Replay
Aug 28, 2025This work introduces a novel generative continual learning framework based on self-organizing maps (SOMs) and variational autoencoders (VAEs) to enable memory-efficient replay, eliminating the need to store raw data samples or task labels. For high-dimensional input spaces, such as of CIFAR-10 and CIFAR-100, we design a scheme where the SOM operates over the latent space learned by a VAE, whereas, for lower-dimensional inputs, such as those found in MNIST and FashionMNIST, the SOM operates in a standalone fashion. Our method stores a running mean, variance, and covariance for each SOM unit, from which synthetic samples are then generated during future learning iterations. For the VAE-based method, generated samples are then fed through the decoder to then be used in subsequent replay. Experimental results on standard class-incremental benchmarks show that our approach performs competitively with state-of-the-art memory-based methods and outperforms memory-free methods, notably improving over best state-of-the-art single class incremental performance on CIFAR-10 and CIFAR-100 by nearly $10$\% and $7$\%, respectively. Our methodology further facilitates easy visualization of the learning process and can also be utilized as a generative model post-training. Results show our method's capability as a scalable, task-label-free, and memory-efficient solution for continual learning.
Extending Spike-Timing Dependent Plasticity to Learning Synaptic Delays
Jun 17, 2025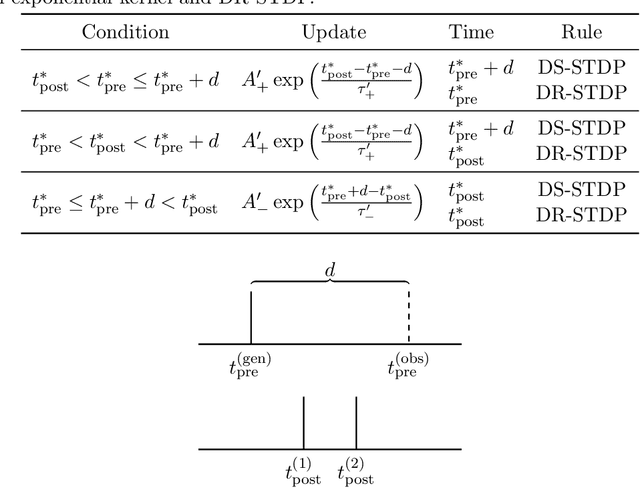
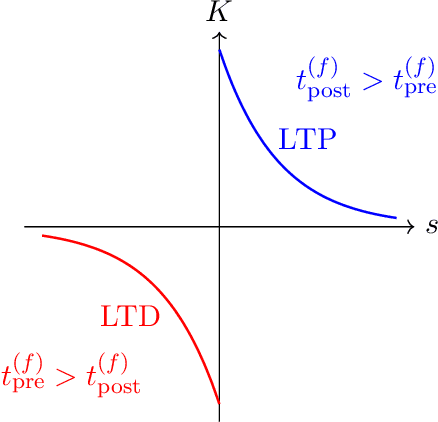
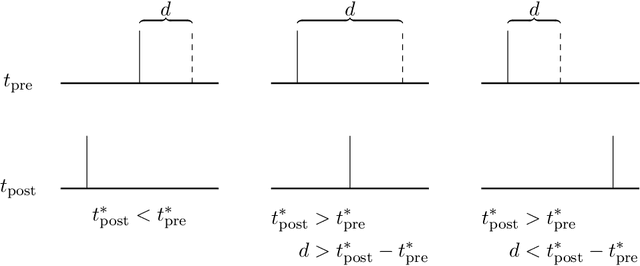
Synaptic delays play a crucial role in biological neuronal networks, where their modulation has been observed in mammalian learning processes. In the realm of neuromorphic computing, although spiking neural networks (SNNs) aim to emulate biology more closely than traditional artificial neural networks do, synaptic delays are rarely incorporated into their simulation. We introduce a novel learning rule for simultaneously learning synaptic connection strengths and delays, by extending spike-timing dependent plasticity (STDP), a Hebbian method commonly used for learning synaptic weights. We validate our approach by extending a widely-used SNN model for classification trained with unsupervised learning. Then we demonstrate the effectiveness of our new method by comparing it against another existing methods for co-learning synaptic weights and delays as well as against STDP without synaptic delays. Results demonstrate that our proposed method consistently achieves superior performance across a variety of test scenarios. Furthermore, our experimental results yield insight into the interplay between synaptic efficacy and delay.
Avoiding Death through Fear Intrinsic Conditioning
Jun 05, 2025



Biological and psychological concepts have inspired reinforcement learning algorithms to create new complex behaviors that expand agents' capacity. These behaviors can be seen in the rise of techniques like goal decomposition, curriculum, and intrinsic rewards, which have paved the way for these complex behaviors. One limitation in evaluating these methods is the requirement for engineered extrinsic for realistic environments. A central challenge in engineering the necessary reward function(s) comes from these environments containing states that carry high negative rewards, but provide no feedback to the agent. Death is one such stimuli that fails to provide direct feedback to the agent. In this work, we introduce an intrinsic reward function inspired by early amygdala development and produce this intrinsic reward through a novel memory-augmented neural network (MANN) architecture. We show how this intrinsic motivation serves to deter exploration of terminal states and results in avoidance behavior similar to fear conditioning observed in animals. Furthermore, we demonstrate how modifying a threshold where the fear response is active produces a range of behaviors that are described under the paradigm of general anxiety disorders (GADs). We demonstrate this behavior in the Miniworld Sidewalk environment, which provides a partially observable Markov decision process (POMDP) and a sparse reward with a non-descriptive terminal condition, i.e., death. In effect, this study results in a biologically-inspired neural architecture and framework for fear conditioning paradigms; we empirically demonstrate avoidance behavior in a constructed agent that is able to solve environments with non-descriptive terminal conditions.
Tight Stability, Convergence, and Robustness Bounds for Predictive Coding Networks
Oct 07, 2024



Energy-based learning algorithms, such as predictive coding (PC), have garnered significant attention in the machine learning community due to their theoretical properties, such as local operations and biologically plausible mechanisms for error correction. In this work, we rigorously analyze the stability, robustness, and convergence of PC through the lens of dynamical systems theory. We show that, first, PC is Lyapunov stable under mild assumptions on its loss and residual energy functions, which implies intrinsic robustness to small random perturbations due to its well-defined energy-minimizing dynamics. Second, we formally establish that the PC updates approximate quasi-Newton methods by incorporating higher-order curvature information, which makes them more stable and able to converge with fewer iterations compared to models trained via backpropagation (BP). Furthermore, using this dynamical framework, we provide new theoretical bounds on the similarity between PC and other algorithms, i.e., BP and target propagation (TP), by precisely characterizing the role of higher-order derivatives. These bounds, derived through detailed analysis of the Hessian structures, show that PC is significantly closer to quasi-Newton updates than TP, providing a deeper understanding of the stability and efficiency of PC compared to conventional learning methods.
R-AIF: Solving Sparse-Reward Robotic Tasks from Pixels with Active Inference and World Models
Sep 21, 2024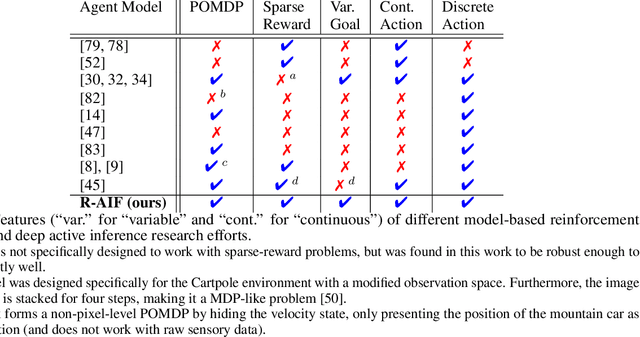
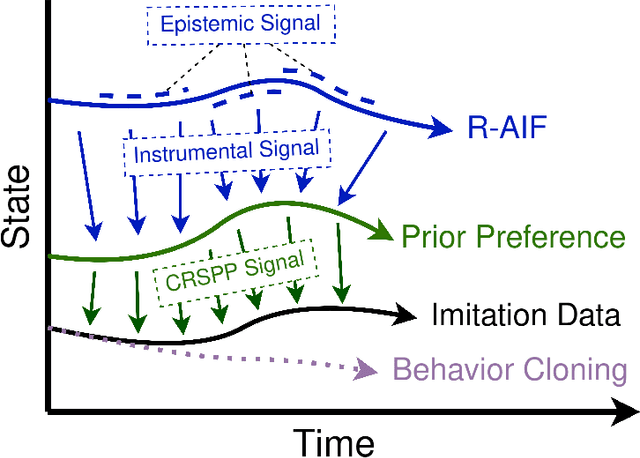
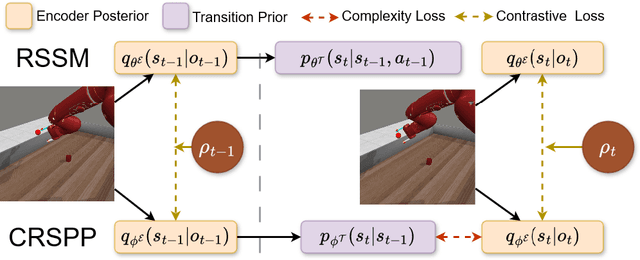
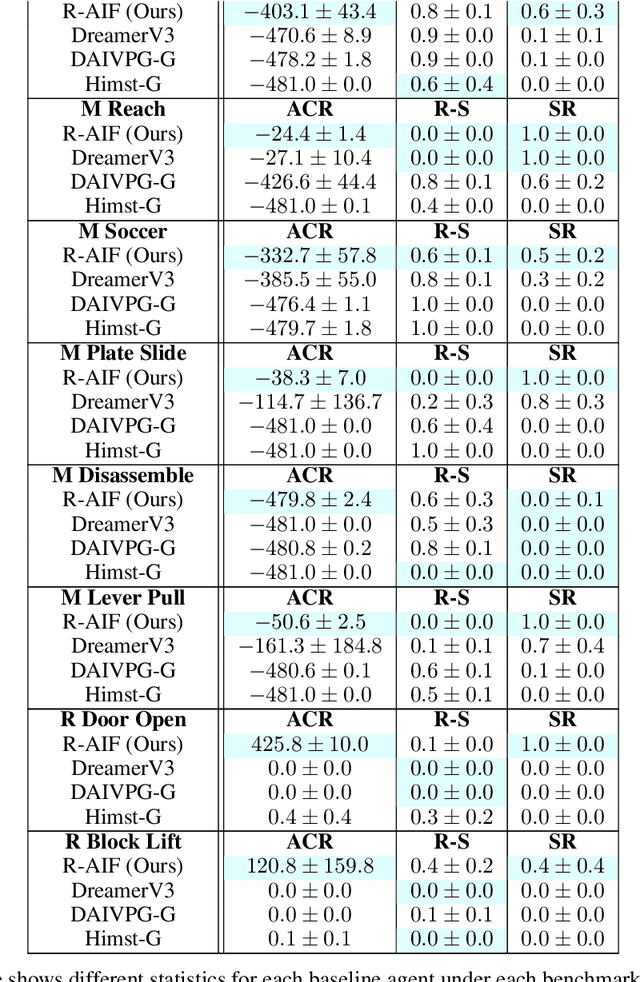
Although research has produced promising results demonstrating the utility of active inference (AIF) in Markov decision processes (MDPs), there is relatively less work that builds AIF models in the context of environments and problems that take the form of partially observable Markov decision processes (POMDPs). In POMDP scenarios, the agent must infer the unobserved environmental state from raw sensory observations, e.g., pixels in an image. Additionally, less work exists in examining the most difficult form of POMDP-centered control: continuous action space POMDPs under sparse reward signals. In this work, we address issues facing the AIF modeling paradigm by introducing novel prior preference learning techniques and self-revision schedules to help the agent excel in sparse-reward, continuous action, goal-based robotic control POMDP environments. Empirically, we show that our agents offer improved performance over state-of-the-art models in terms of cumulative rewards, relative stability, and success rate. The code in support of this work can be found at https://github.com/NACLab/robust-active-inference.
Contrastive Learning in Memristor-based Neuromorphic Systems
Sep 17, 2024



Spiking neural networks, the third generation of artificial neural networks, have become an important family of neuron-based models that sidestep many of the key limitations facing modern-day backpropagation-trained deep networks, including their high energy inefficiency and long-criticized biological implausibility. In this work, we design and investigate a proof-of-concept instantiation of contrastive-signal-dependent plasticity (CSDP), a neuromorphic form of forward-forward-based, backpropagation-free learning. Our experimental simulations demonstrate that a hardware implementation of CSDP is capable of learning simple logic functions without the need to resort to complex gradient calculations.
Deep Domain Adaptation: A Sim2Real Neural Approach for Improving Eye-Tracking Systems
Mar 23, 2024Eye image segmentation is a critical step in eye tracking that has great influence over the final gaze estimate. Segmentation models trained using supervised machine learning can excel at this task, their effectiveness is determined by the degree of overlap between the narrow distributions of image properties defined by the target dataset and highly specific training datasets, of which there are few. Attempts to broaden the distribution of existing eye image datasets through the inclusion of synthetic eye images have found that a model trained on synthetic images will often fail to generalize back to real-world eye images. In remedy, we use dimensionality-reduction techniques to measure the overlap between the target eye images and synthetic training data, and to prune the training dataset in a manner that maximizes distribution overlap. We demonstrate that our methods result in robust, improved performance when tackling the discrepancy between simulation and real-world data samples.