 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Neurorobot Policy under Limited Demonstration Data through Preference Regret
Apr 04, 2026Robot reinforcement learning from demonstrations (RLfD) assumes that expert data is abundant; this is usually unrealistic in the real world given data scarcity as well as high collection cost. Furthermore, imitation learning algorithms assume that the data is independently and identically distributed, which ultimately results in poorer performance as gradual errors emerge and compound within test-time trajectories. We address these issues by introducing the "master your own expertise" (MYOE) framework, a self-imitation framework that enables robotic agents to learn complex behaviors from limited demonstration data samples. Inspired by human perception and action, we propose and design what we call the queryable mixture-of-preferences state space model (QMoP-SSM), which estimates the desired goal at every time step. These desired goals are used in computing the "preference regret", which is used to optimize the robot control policy. Our experiments demonstrate the robustness, adaptability, and out-of-sample performance of our agent compared to other state-of-the-art RLfD schemes. The GitHub repository that supports this work can be found at: https://github.com/rxng8/neurorobot-preference-regret-learning.
Enhancing Eye Feature Estimation from Event Data Streams through Adaptive Inference State Space Modeling
Mar 14, 2026Eye feature extraction from event-based data streams can be performed efficiently and with low energy consumption, offering great utility to real-world eye tracking pipelines. However, few eye feature extractors are designed to handle sudden changes in event density caused by the changes between gaze behaviors that vary in their kinematics, leading to degraded prediction performance. In this work, we address this problem by introducing the \emph{adaptive inference state space model} (AISSM), a novel architecture for feature extraction that is capable of dynamically adjusting the relative weight placed on current versus recent information. This relative weighting is determined via estimates of the signal-to-noise ratio and event density produced by a complementary \emph{dynamic confidence network}. Lastly, we craft and evaluate a novel learning technique that improves training efficiency. Experimental results demonstrate that the AISSM system outperforms state-of-the-art models for event-based eye feature extraction.
R-AIF: Solving Sparse-Reward Robotic Tasks from Pixels with Active Inference and World Models
Sep 21, 2024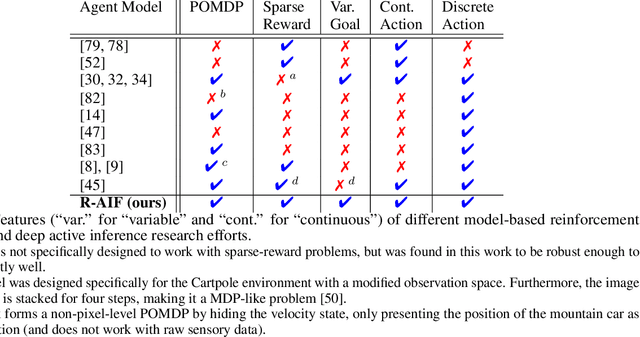
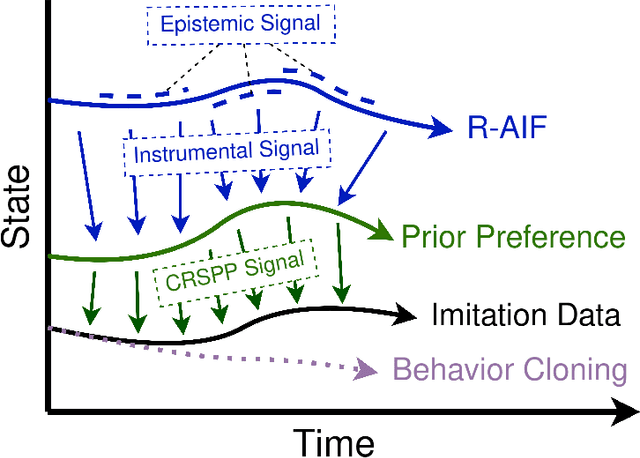
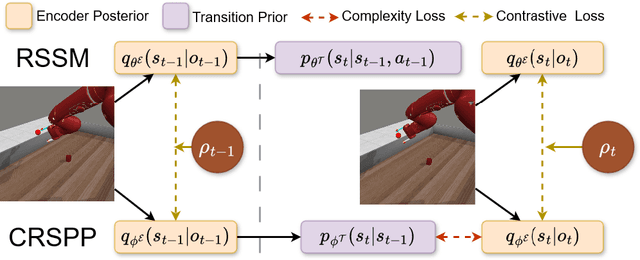
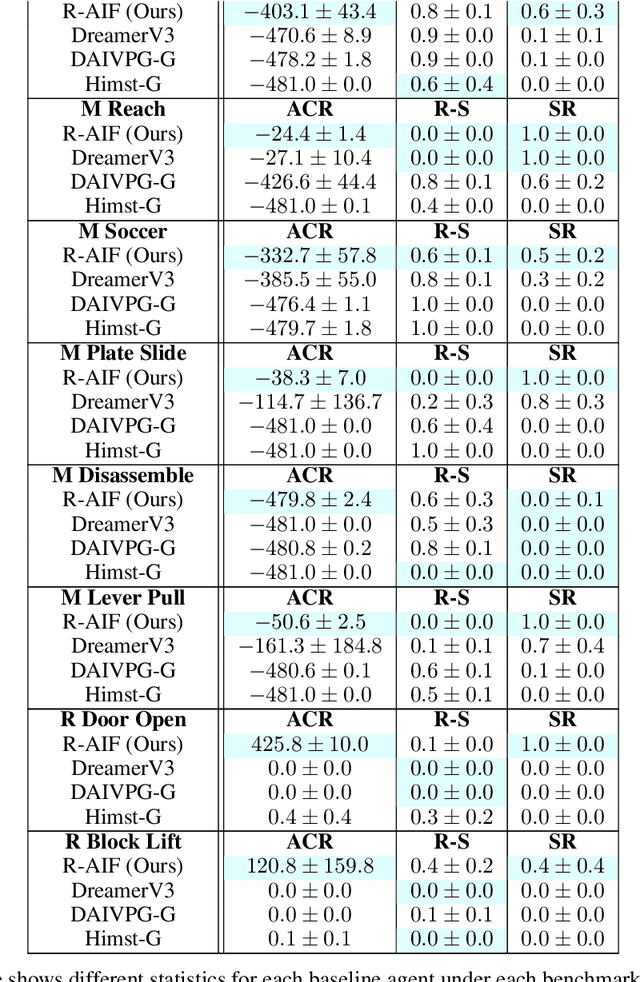
Although research has produced promising results demonstrating the utility of active inference (AIF) in Markov decision processes (MDPs), there is relatively less work that builds AIF models in the context of environments and problems that take the form of partially observable Markov decision processes (POMDPs). In POMDP scenarios, the agent must infer the unobserved environmental state from raw sensory observations, e.g., pixels in an image. Additionally, less work exists in examining the most difficult form of POMDP-centered control: continuous action space POMDPs under sparse reward signals. In this work, we address issues facing the AIF modeling paradigm by introducing novel prior preference learning techniques and self-revision schedules to help the agent excel in sparse-reward, continuous action, goal-based robotic control POMDP environments. Empirically, we show that our agents offer improved performance over state-of-the-art models in terms of cumulative rewards, relative stability, and success rate. The code in support of this work can be found at https://github.com/NACLab/robust-active-inference.
Revisiting the Disequilibrium Issues in Tackling Heart Disease Classification Tasks
Jul 19, 2024



In the field of heart disease classification, two primary obstacles arise. Firstly, existing Electrocardiogram (ECG) datasets consistently demonstrate imbalances and biases across various modalities. Secondly, these time-series data consist of diverse lead signals, causing Convolutional Neural Networks (CNNs) to become overfitting to the one with higher power, hence diminishing the performance of the Deep Learning (DL) process. In addition, when facing an imbalanced dataset, performance from such high-dimensional data may be susceptible to overfitting. Current efforts predominantly focus on enhancing DL models by designing novel architectures, despite these evident challenges, seemingly overlooking the core issues, therefore hindering advancements in heart disease classification. To address these obstacles, our proposed approach introduces two straightforward and direct methods to enhance the classification tasks. To address the high dimensionality issue, we employ a Channel-wise Magnitude Equalizer (CME) on signal-encoded images. This approach reduces redundancy in the feature data range, highlighting changes in the dataset. Simultaneously, to counteract data imbalance, we propose the Inverted Weight Logarithmic Loss (IWL) to alleviate imbalances among the data. When applying IWL loss, the accuracy of state-of-the-art models (SOTA) increases up to 5% in the CPSC2018 dataset. CME in combination with IWL also surpasses the classification results of other baseline models from 5% to 10%.
How Homogenizing the Channel-wise Magnitude Can Enhance EEG Classification Model?
Jul 19, 2024A significant challenge in the electroencephalogram EEG lies in the fact that current data representations involve multiple electrode signals, resulting in data redundancy and dominant lead information. However extensive research conducted on EEG classification focuses on designing model architectures without tackling the underlying issues. Otherwise, there has been a notable gap in addressing data preprocessing for EEG, leading to considerable computational overhead in Deep Learning (DL) processes. In light of these issues, we propose a simple yet effective approach for EEG data pre-processing. Our method first transforms the EEG data into an encoded image by an Inverted Channel-wise Magnitude Homogenization (ICWMH) to mitigate inter-channel biases. Next, we apply the edge detection technique on the EEG-encoded image combined with skip connection to emphasize the most significant transitions in the data while preserving structural and invariant information. By doing so, we can improve the EEG learning process efficiently without using a huge DL network. Our experimental evaluations reveal that we can significantly improve (i.e., from 2% to 5%) over current baselines.
PAT: Pixel-wise Adaptive Training for Long-tailed Segmentation
Apr 09, 2024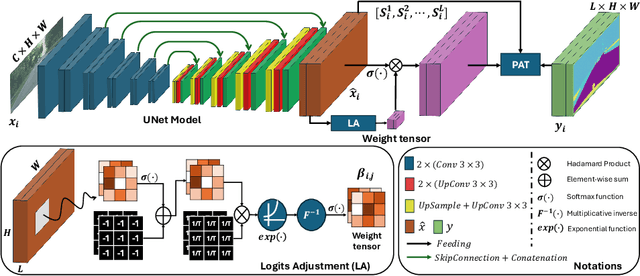
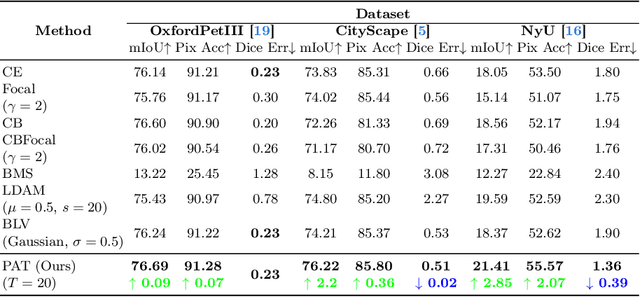
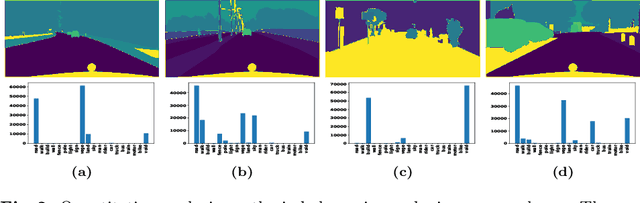
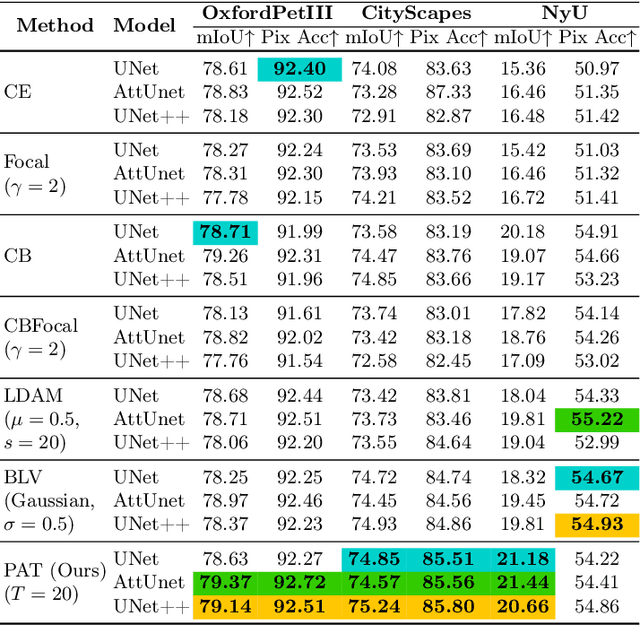
Beyond class frequency, we recognize the impact of class-wise relationships among various class-specific predictions and the imbalance in label masks on long-tailed segmentation learning. To address these challenges, we propose an innovative Pixel-wise Adaptive Training (PAT) technique tailored for long-tailed segmentation. PAT has two key features: 1) class-wise gradient magnitude homogenization, and 2) pixel-wise class-specific loss adaptation (PCLA). First, the class-wise gradient magnitude homogenization helps alleviate the imbalance among label masks by ensuring equal consideration of the class-wise impact on model updates. Second, PCLA tackles the detrimental impact of both rare classes within the long-tailed distribution and inaccurate predictions from previous training stages by encouraging learning classes with low prediction confidence and guarding against forgetting classes with high confidence. This combined approach fosters robust learning while preventing the model from forgetting previously learned knowledge. PAT exhibits significant performance improvements, surpassing the current state-of-the-art by 2.2% in the NyU dataset. Moreover, it enhances overall pixel-wise accuracy by 2.85% and intersection over union value by 2.07%, with a particularly notable declination of 0.39% in detecting rare classes compared to Balance Logits Variation, as demonstrated on the three popular datasets, i.e., OxfordPetIII, CityScape, and NYU.
Deep Domain Adaptation: A Sim2Real Neural Approach for Improving Eye-Tracking Systems
Mar 23, 2024Eye image segmentation is a critical step in eye tracking that has great influence over the final gaze estimate. Segmentation models trained using supervised machine learning can excel at this task, their effectiveness is determined by the degree of overlap between the narrow distributions of image properties defined by the target dataset and highly specific training datasets, of which there are few. Attempts to broaden the distribution of existing eye image datasets through the inclusion of synthetic eye images have found that a model trained on synthetic images will often fail to generalize back to real-world eye images. In remedy, we use dimensionality-reduction techniques to measure the overlap between the target eye images and synthetic training data, and to prune the training dataset in a manner that maximizes distribution overlap. We demonstrate that our methods result in robust, improved performance when tackling the discrepancy between simulation and real-world data samples.
An Automated Real-Time Approach for Image Processing and Segmentation of Fluoroscopic Images and Videos Using a Single Deep Learning Network
Jan 23, 2024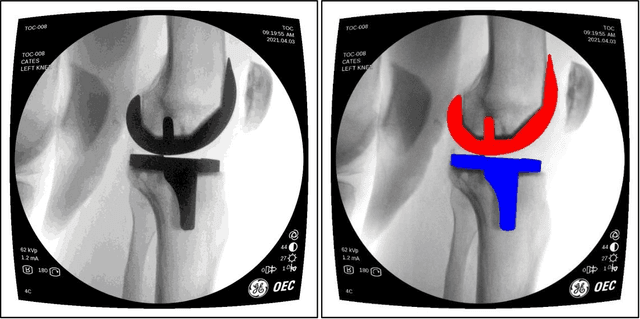

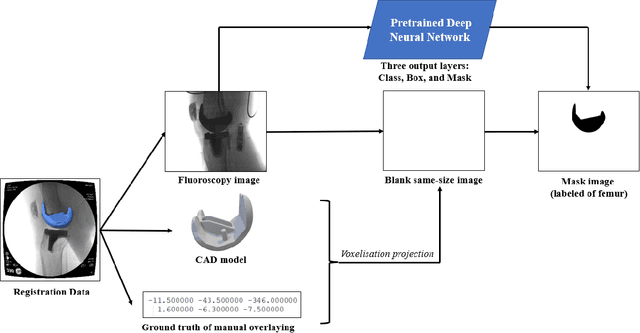
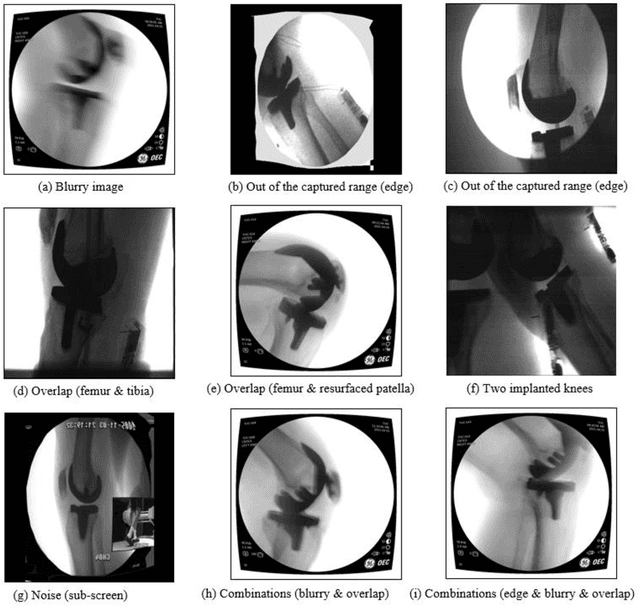
Image segmentation in total knee arthroplasty is crucial for precise preoperative planning and accurate implant positioning, leading to improved surgical outcomes and patient satisfaction. The biggest challenges of image segmentation in total knee arthroplasty include accurately delineating complex anatomical structures, dealing with image artifacts and noise, and developing robust algorithms that can handle anatomical variations and pathologies commonly encountered in patients. The potential of using machine learning for image segmentation in total knee arthroplasty lies in its ability to improve segmentation accuracy, automate the process, and provide real-time assistance to surgeons, leading to enhanced surgical planning, implant placement, and patient outcomes. This paper proposes a methodology to use deep learning for robust and real-time total knee arthroplasty image segmentation. The deep learning model, trained on a large dataset, demonstrates outstanding performance in accurately segmenting both the implanted femur and tibia, achieving an impressive mean-Average-Precision (mAP) of 88.83 when compared to the ground truth while also achieving a real-time segmented speed of 20 frames per second (fps). We have introduced a novel methodology for segmenting implanted knee fluoroscopic or x-ray images that showcases remarkable levels of accuracy and speed, paving the way for various potential extended applications.
ARPD: Anchor-free Rotation-aware People Detection using Topview Fisheye Camera
Jan 25, 2022

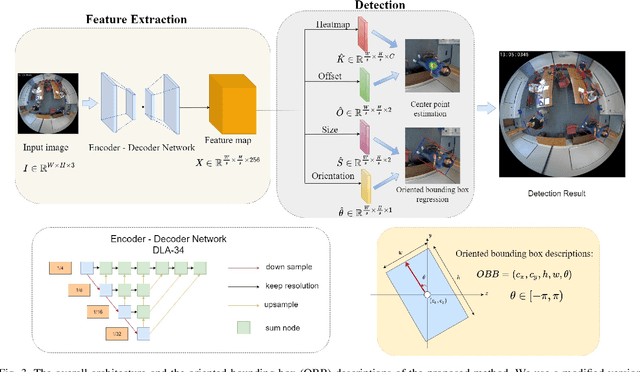
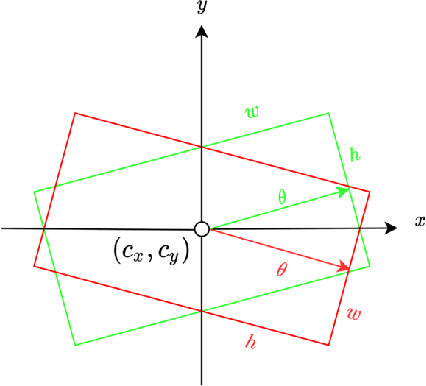
People detection in top-view, fish-eye images is challenging as people in fish-eye images often appear in arbitrary directions and are distorted differently. Due to this unique radial geometry, axis-aligned people detectors often work poorly on fish-eye frames. Recent works account for this variability by modifying existing anchor-based detectors or relying on complex pre/post-processing. Anchor-based methods spread a set of pre-defined bounding boxes on the input image, most of which are invalid. In addition to being inefficient, this approach could lead to a significant imbalance between the positive and negative anchor boxes. In this work, we propose ARPD, a single-stage anchor-free fully convolutional network to detect arbitrarily rotated people in fish-eye images. Our network uses keypoint estimation to find the center point of each object and regress the object's other properties directly. To capture the various orientation of people in fish-eye cameras, in addition to the center and size, ARPD also predicts the angle of each bounding box. We also propose a periodic loss function that accounts for angle periodicity and relieves the difficulty of learning small-angle oscillations. Experimental results show that our method competes favorably with state-of-the-art algorithms while running significantly faster.