 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileBench-OL: A Comprehensive Chinese Benchmark for Evaluating Mobile GUI Agents in Real-World Environment
Jan 29, 2026Recent advances in mobile Graphical User Interface (GUI) agents highlight the growing need for comprehensive evaluation benchmarks. While new online benchmarks offer more realistic testing than offline ones, they tend to focus on the agents' task instruction-following ability while neglecting their reasoning and exploration ability. Moreover, these benchmarks do not consider the random noise in real-world mobile environments. This leads to a gap between benchmarks and real-world environments. To addressing these limitations, we propose MobileBench-OL, an online benchmark with 1080 tasks from 80 Chinese apps. It measures task execution, complex reasoning, and noise robustness of agents by including 5 subsets, which set multiple evaluation dimensions. We also provide an auto-eval framework with a reset mechanism, enabling stable and repeatable real-world benchmarking. Evaluating 12 leading GUI agents on MobileBench-OL shows significant room for improvement to meet real-world requirements. Human evaluation further confirms that MobileBench-OL can reliably measure the performance of leading GUI agents in real environments. Our data and code will be released upon acceptance.
ReflectEvo: Improving Meta Introspection of Small LLMs by Learning Self-Reflection
May 22, 2025We present a novel pipeline, ReflectEvo, to demonstrate that small language models (SLMs) can enhance meta introspection through reflection learning. This process iteratively generates self-reflection for self-training, fostering a continuous and self-evolving process. Leveraging this pipeline, we construct ReflectEvo-460k, a large-scale, comprehensive, self-generated reflection dataset with broadened instructions and diverse multi-domain tasks. Building upon this dataset, we demonstrate the effectiveness of reflection learning to improve SLMs' reasoning abilities using SFT and DPO with remarkable performance, substantially boosting Llama-3 from 52.4% to 71.2% and Mistral from 44.4% to 71.1%. It validates that ReflectEvo can rival or even surpass the reasoning capability of the three prominent open-sourced models on BIG-bench without distillation from superior models or fine-grained human annotation. We further conduct a deeper analysis of the high quality of self-generated reflections and their impact on error localization and correction. Our work highlights the potential of continuously enhancing the reasoning performance of SLMs through iterative reflection learning in the long run.
R-AIF: Solving Sparse-Reward Robotic Tasks from Pixels with Active Inference and World Models
Sep 21, 2024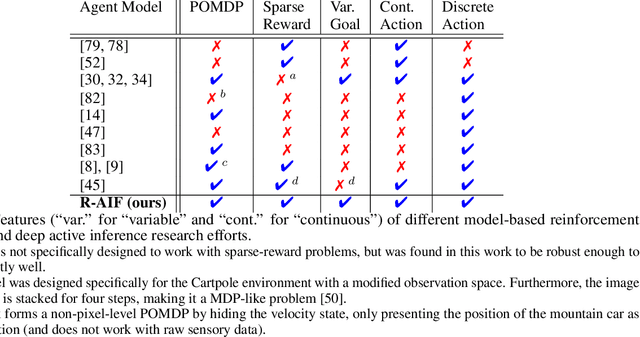
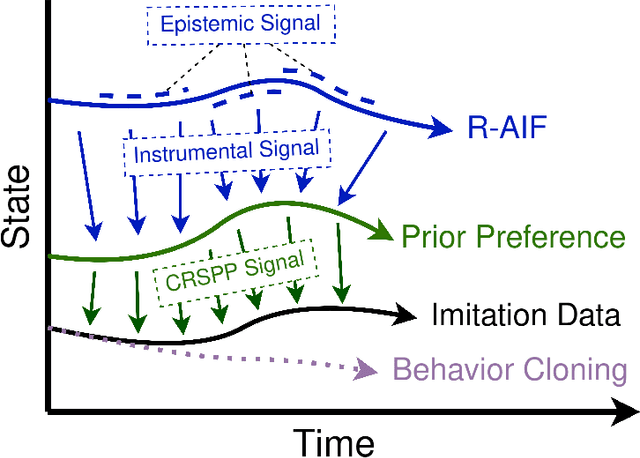
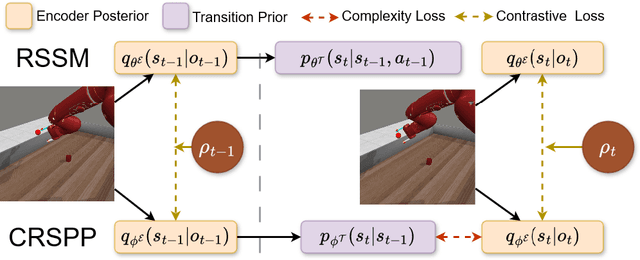
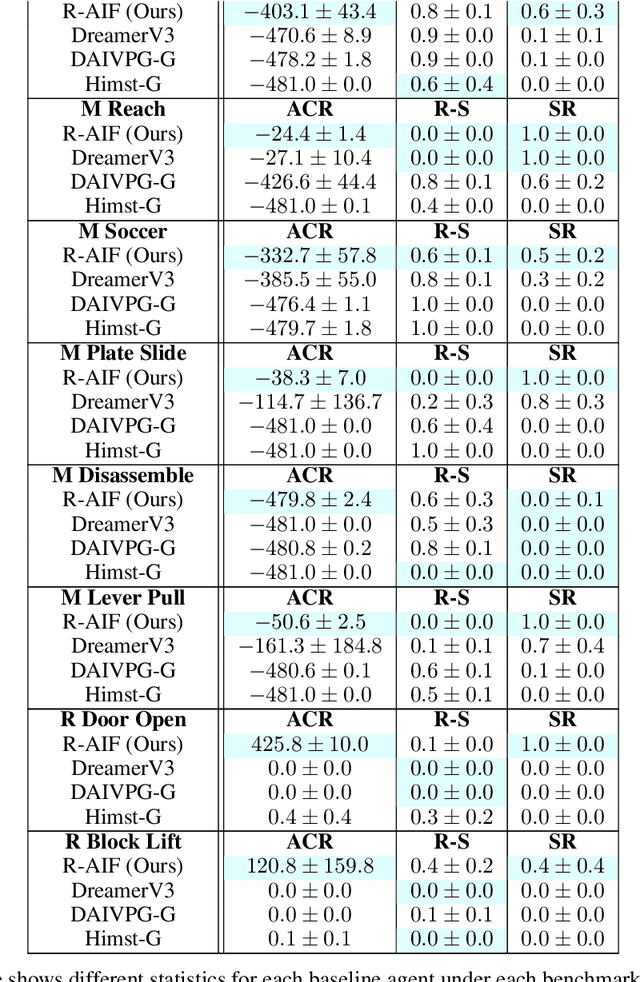
Although research has produced promising results demonstrating the utility of active inference (AIF) in Markov decision processes (MDPs), there is relatively less work that builds AIF models in the context of environments and problems that take the form of partially observable Markov decision processes (POMDPs). In POMDP scenarios, the agent must infer the unobserved environmental state from raw sensory observations, e.g., pixels in an image. Additionally, less work exists in examining the most difficult form of POMDP-centered control: continuous action space POMDPs under sparse reward signals. In this work, we address issues facing the AIF modeling paradigm by introducing novel prior preference learning techniques and self-revision schedules to help the agent excel in sparse-reward, continuous action, goal-based robotic control POMDP environments. Empirically, we show that our agents offer improved performance over state-of-the-art models in terms of cumulative rewards, relative stability, and success rate. The code in support of this work can be found at https://github.com/NACLab/robust-active-inference.
A Neural Active Inference Model of Perceptual-Motor Learning
Nov 16, 2022



The active inference framework (AIF) is a promising new computational framework grounded in contemporary neuroscience that can produce human-like behavior through reward-based learning. In this study, we test the ability for the AIF to capture the role of anticipation in the visual guidance of action in humans through the systematic investigation of a visual-motor task that has been well-explored -- that of intercepting a target moving over a ground plane. Previous research demonstrated that humans performing this task resorted to anticipatory changes in speed intended to compensate for semi-predictable changes in target speed later in the approach. To capture this behavior, our proposed "neural" AIF agent uses artificial neural networks to select actions on the basis of a very short term prediction of the information about the task environment that these actions would reveal along with a long-term estimate of the resulting cumulative expected free energy. Systematic variation revealed that anticipatory behavior emerged only when required by limitations on the agent's movement capabilities, and only when the agent was able to estimate accumulated free energy over sufficiently long durations into the future. In addition, we present a novel formulation of the prior function that maps a multi-dimensional world-state to a uni-dimensional distribution of free-energy. Together, these results demonstrate the use of AIF as a plausible model of anticipatory visually guided behavior in humans.
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020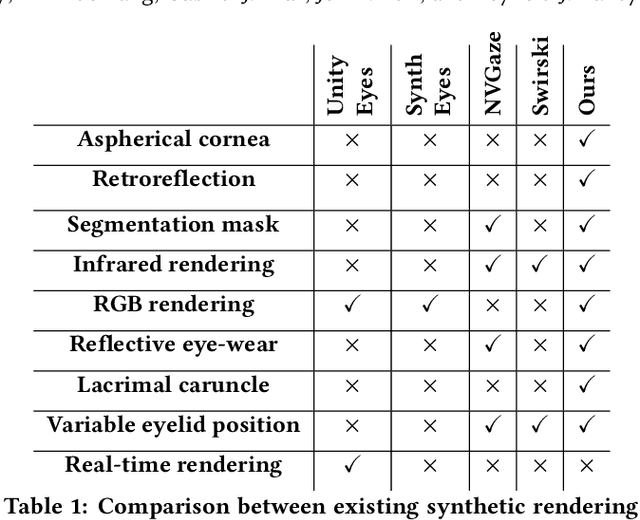
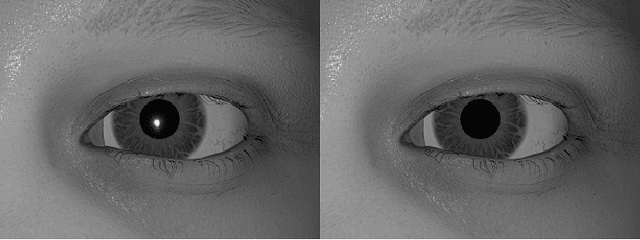
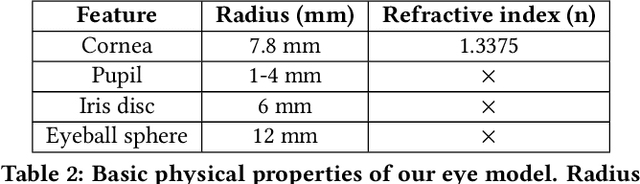
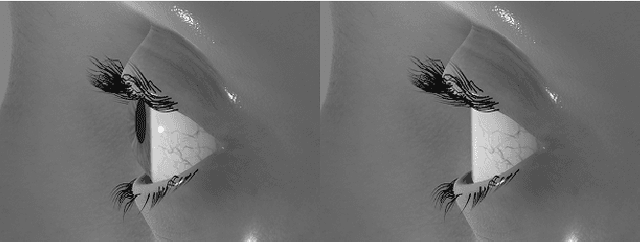
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.
Gaze-in-wild: A dataset for studying eye and head coordination in everyday activities
May 09, 2019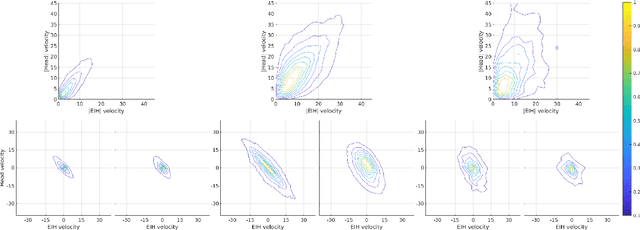
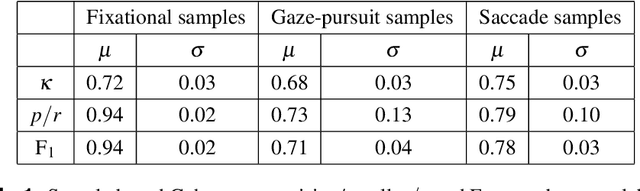

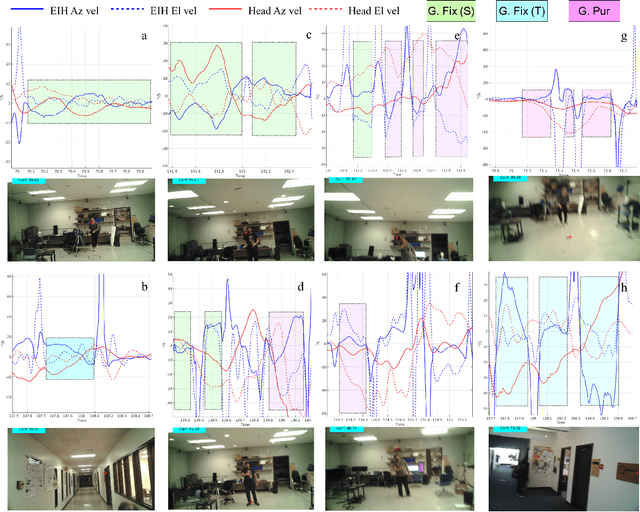
The interaction between the vestibular and ocular system has primarily been studied in controlled environments. Consequently, off-the shelf tools for categorization of gaze events (e.g. fixations, pursuits, saccade) fail when head movements are allowed. Our approach was to collect a novel, naturalistic, and multimodal dataset of eye+head movements when subjects performed everyday tasks while wearing a mobile eye tracker equipped with an inertial measurement unit and a 3D stereo camera. This Gaze-in-the-Wild dataset (GW) includes eye+head rotational velocities (deg/s), infrared eye images and scene imagery (RGB+D). A portion was labelled by coders into gaze motion events with a mutual agreement of 0.72 sample based Cohen's $\kappa$. This labelled data was used to train and evaluate two machine learning algorithms, Random Forest and a Recurrent Neural Network model, for gaze event classification. Assessment involved the application of established and novel event based performance metrics. Classifiers achieve $\sim$90$\%$ human performance in detecting fixations and saccades but fall short (60$\%$) on detecting pursuit movements. Moreover, pursuit classification is far worse in the absence of head movement information. A subsequent analysis of feature significance in our best-performing model revealed a reliance upon absolute eye and head velocity, indicating that classification does not require spatial alignment of the head and eye tracking coordinate systems. The GW dataset, trained classifiers and evaluation metrics will be made publicly available with the intention of facilitating growth in the emerging area of head-free gaze event classification.