 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparse Training of Diagonally Sparse Networks
Jun 13, 2025Recent advances in Dynamic Sparse Training (DST) have pushed the frontier of sparse neural network training in structured and unstructured contexts, matching dense-model performance while drastically reducing parameter counts to facilitate model scaling. However, unstructured sparsity often fails to translate into practical speedups on modern hardware. To address this shortcoming, we propose DynaDiag, a novel structured sparse-to-sparse DST method that performs at par with unstructured sparsity. DynaDiag enforces a diagonal sparsity pattern throughout training and preserves sparse computation in forward and backward passes. We further leverage the diagonal structure to accelerate computation via a custom CUDA kernel, rendering the method hardware-friendly. Empirical evaluations on diverse neural architectures demonstrate that our method maintains accuracy on par with unstructured counterparts while benefiting from tangible computational gains. Notably, with 90% sparse linear layers in ViTs, we observe up to a 3.13x speedup in online inference without sacrificing model performance and a 1.59x speedup in training on a GPU compared to equivalent unstructured layers. Our source code is available at https://github.com/horizon-research/DynaDiag/.
A Good Start Matters: Enhancing Continual Learning with Data-Driven Weight Initialization
Mar 09, 2025



To adapt to real-world data streams, continual learning (CL) systems must rapidly learn new concepts while preserving and utilizing prior knowledge. When it comes to adding new information to continually-trained deep neural networks (DNNs), classifier weights for newly encountered categories are typically initialized randomly, leading to high initial training loss (spikes) and instability. Consequently, achieving optimal convergence and accuracy requires prolonged training, increasing computational costs. Inspired by Neural Collapse (NC), we propose a weight initialization strategy to improve learning efficiency in CL. In DNNs trained with mean-squared-error, NC gives rise to a Least-Square (LS) classifier in the last layer, whose weights can be analytically derived from learned features. We leverage this LS formulation to initialize classifier weights in a data-driven manner, aligning them with the feature distribution rather than using random initialization. Our method mitigates initial loss spikes and accelerates adaptation to new tasks. We evaluate our approach in large-scale CL settings, demonstrating faster adaptation and improved CL performance.
INSIGHT: Explainable Weakly-Supervised Medical Image Analysis
Dec 02, 2024
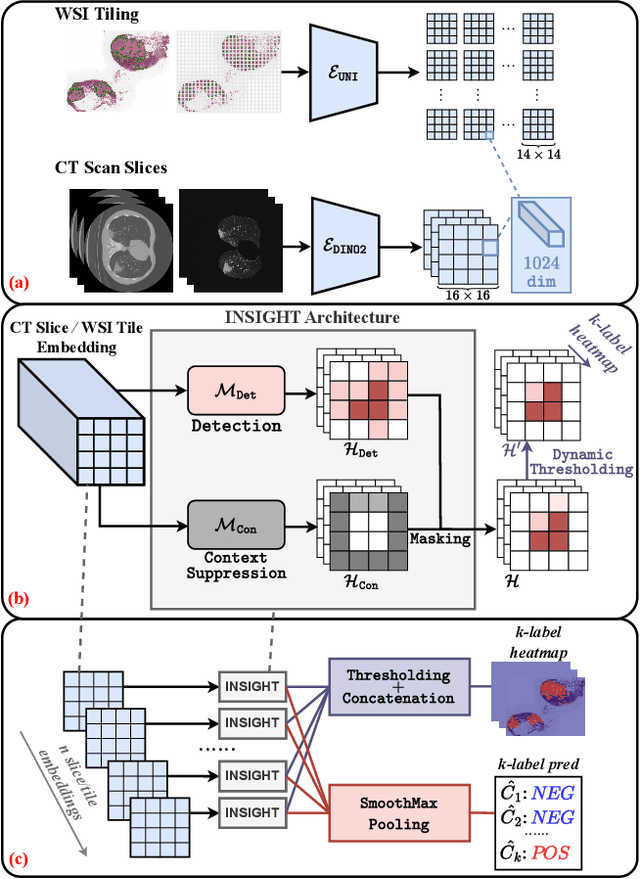
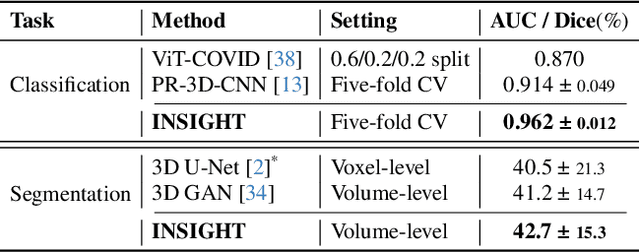

Due to their large sizes, volumetric scans and whole-slide pathology images (WSIs) are often processed by extracting embeddings from local regions and then an aggregator makes predictions from this set. However, current methods require post-hoc visualization techniques (e.g., Grad-CAM) and often fail to localize small yet clinically crucial details. To address these limitations, we introduce INSIGHT, a novel weakly-supervised aggregator that integrates heatmap generation as an inductive bias. Starting from pre-trained feature maps, INSIGHT employs a detection module with small convolutional kernels to capture fine details and a context module with a broader receptive field to suppress local false positives. The resulting internal heatmap highlights diagnostically relevant regions. On CT and WSI benchmarks, INSIGHT achieves state-of-the-art classification results and high weakly-labeled semantic segmentation performance. Project website and code are available at: https://zhangdylan83.github.io/ewsmia/
Improving Multimodal Large Language Models Using Continual Learning
Oct 25, 2024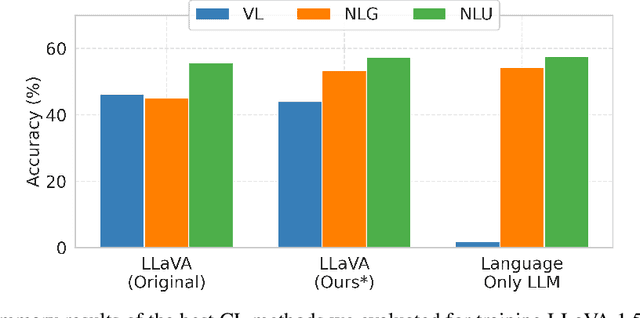
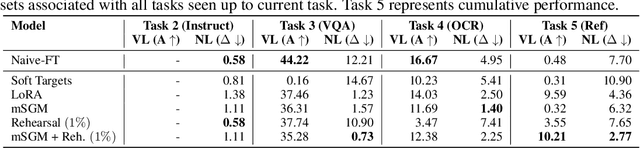
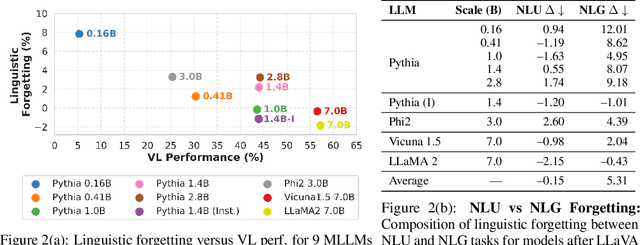
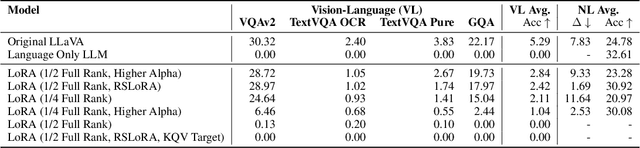
Generative large language models (LLMs) exhibit impressive capabilities, which can be further augmented by integrating a pre-trained vision model into the original LLM to create a multimodal LLM (MLLM). However, this integration often significantly decreases performance on natural language understanding and generation tasks, compared to the original LLM. This study investigates this issue using the LLaVA MLLM, treating the integration as a continual learning problem. We evaluate five continual learning methods to mitigate forgetting and identify a technique that enhances visual understanding while minimizing linguistic performance loss. Our approach reduces linguistic performance degradation by up to 15\% over the LLaVA recipe, while maintaining high multimodal accuracy. We also demonstrate the robustness of our method through continual learning on a sequence of vision-language tasks, effectively preserving linguistic skills while acquiring new multimodal capabilities.
Can Kans (re)discover predictive models for Direct-Drive Laser Fusion?
Sep 13, 2024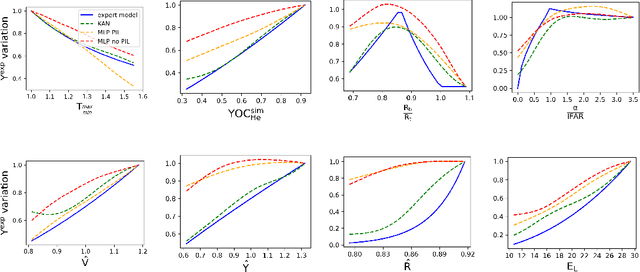


The domain of laser fusion presents a unique and challenging predictive modeling application landscape for machine learning methods due to high problem complexity and limited training data. Data-driven approaches utilizing prescribed functional forms, inductive biases and physics-informed learning (PIL) schemes have been successful in the past for achieving desired generalization ability and model interpretation that aligns with physics expectations. In complex multi-physics application domains, however, it is not always obvious how architectural biases or discriminative penalties can be formulated. In this work, focusing on nuclear fusion energy using high powered lasers, we present the use of Kolmogorov-Arnold Networks (KANs) as an alternative to PIL for developing a new type of data-driven predictive model which is able to achieve high prediction accuracy and physics interpretability. A KAN based model, a MLP with PIL, and a baseline MLP model are compared in generalization ability and interpretation with a domain expert-derived symbolic regression model. Through empirical studies in this high physics complexity domain, we show that KANs can potentially provide benefits when developing predictive models for data-starved physics applications.
Revisiting Multi-Modal LLM Evaluation
Aug 09, 2024
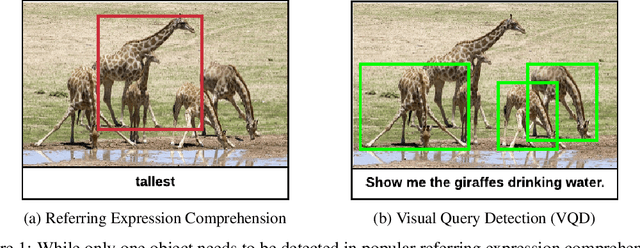

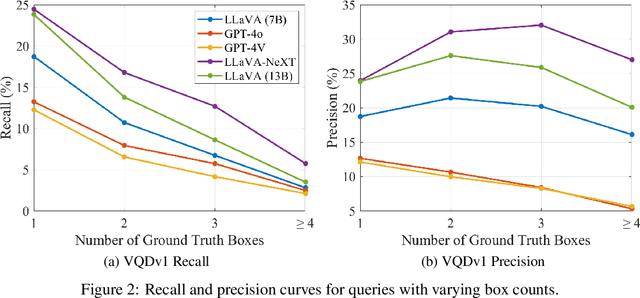
With the advent of multi-modal large language models (MLLMs), datasets used for visual question answering (VQA) and referring expression comprehension have seen a resurgence. However, the most popular datasets used to evaluate MLLMs are some of the earliest ones created, and they have many known problems, including extreme bias, spurious correlations, and an inability to permit fine-grained analysis. In this paper, we pioneer evaluating recent MLLMs (LLaVA 1.5, LLaVA-NeXT, BLIP2, InstructBLIP, GPT-4V, and GPT-4o) on datasets designed to address weaknesses in earlier ones. We assess three VQA datasets: 1) TDIUC, which permits fine-grained analysis on 12 question types; 2) TallyQA, which has simple and complex counting questions; and 3) DVQA, which requires optical character recognition for chart understanding. We also study VQDv1, a dataset that requires identifying all image regions that satisfy a given query. Our experiments reveal the weaknesses of many MLLMs that have not previously been reported. Our code is integrated into the widely used LAVIS framework for MLLM evaluation, enabling the rapid assessment of future MLLMs. Project webpage: https://kevinlujian.github.io/MLLM_Evaluations/
What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
May 23, 2024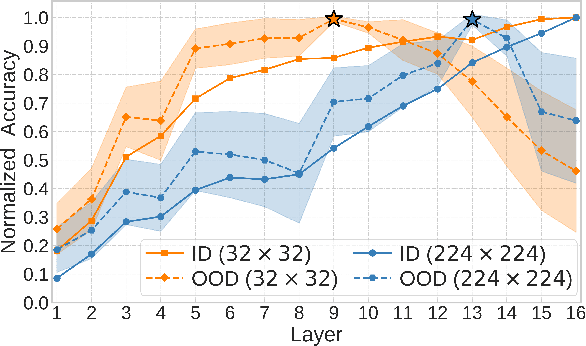
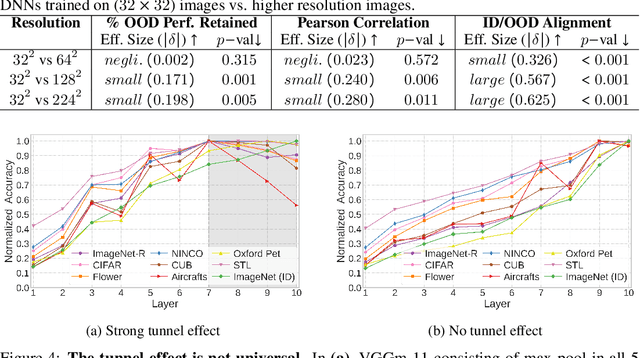

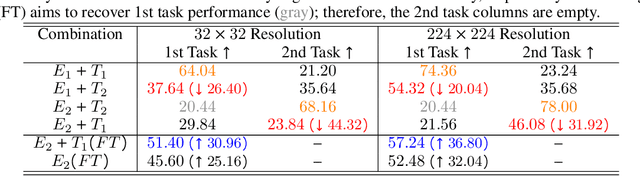
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
PRISM: A Multi-Modal Generative Foundation Model for Slide-Level Histopathology
May 16, 2024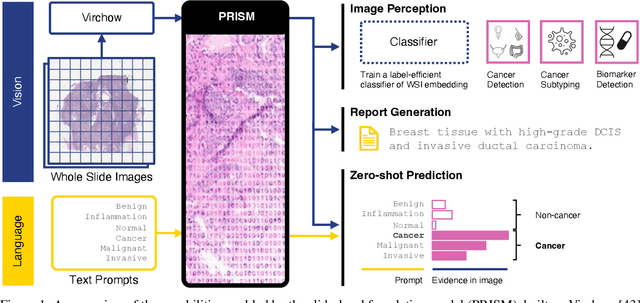
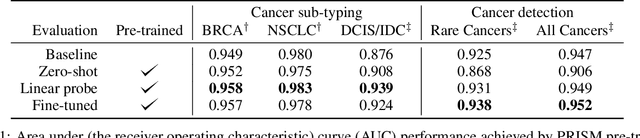
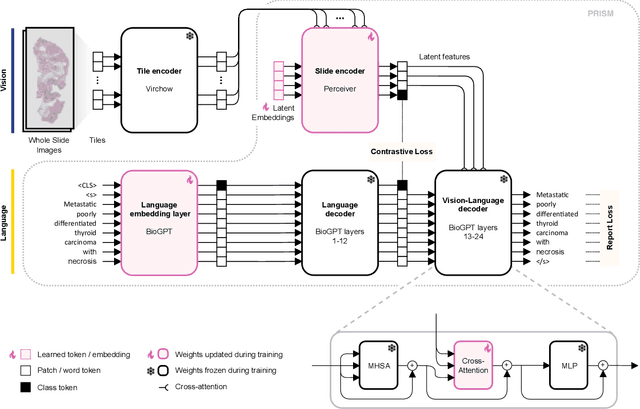
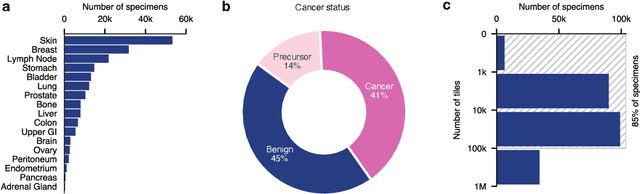
Foundation models in computational pathology promise to unlock the development of new clinical decision support systems and models for precision medicine. However, there is a mismatch between most clinical analysis, which is defined at the level of one or more whole slide images, and foundation models to date, which process the thousands of image tiles contained in a whole slide image separately. The requirement to train a network to aggregate information across a large number of tiles in multiple whole slide images limits these models' impact. In this work, we present a slide-level foundation model for H&E-stained histopathology, PRISM, that builds on Virchow tile embeddings and leverages clinical report text for pre-training. Using the tile embeddings, PRISM produces slide-level embeddings with the ability to generate clinical reports, resulting in several modes of use. Using text prompts, PRISM achieves zero-shot cancer detection and sub-typing performance approaching and surpassing that of a supervised aggregator model. Using the slide embeddings with linear classifiers, PRISM surpasses supervised aggregator models. Furthermore, we demonstrate that fine-tuning of the PRISM slide encoder yields label-efficient training for biomarker prediction, a task that typically suffers from low availability of training data; an aggregator initialized with PRISM and trained on as little as 10% of the training data can outperform a supervised baseline that uses all of the data.
DMC4ML: Data Movement Complexity for Machine Learning
Dec 22, 2023The greatest demand for today's computing is machine learning. This paper analyzes three machine learning algorithms: transformers, spatial convolution, and FFT. The analysis is novel in three aspects. First, it measures the cost of memory access on an abstract memory hierarchy, instead of traditional time or space complexity. Second, the analysis is asymptotic and identifies the primary sources of the memory cost. Finally, the result is symbolic, which can be used to select algorithmic parameters such as the group size in grouped query attention for any dimension size and number of heads and the batch size for batched convolution for any image size and kernel size.
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023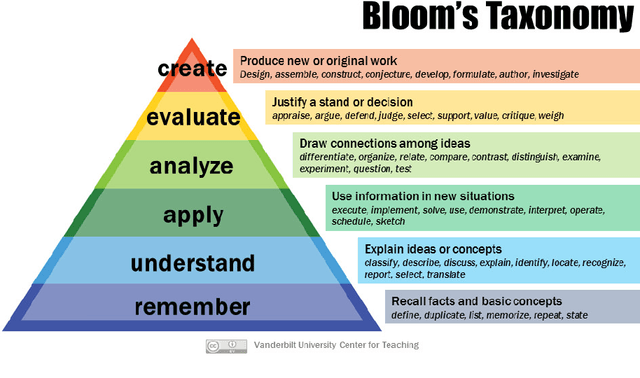
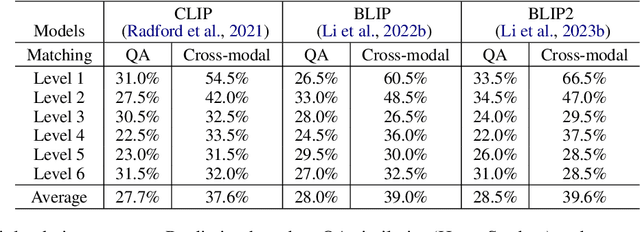

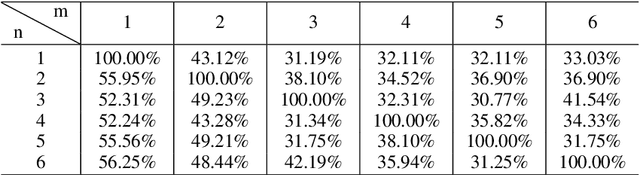
We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.