 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide to Streaming Continual Learning
Mar 02, 2026Continual Learning (CL) and Streaming Machine Learning (SML) study the ability of agents to learn from a stream of non-stationary data. Despite sharing some similarities, they address different and complementary challenges. While SML focuses on rapid adaptation after changes (concept drifts), CL aims to retain past knowledge when learning new tasks. After a brief introduction to CL and SML, we discuss Streaming Continual Learning (SCL), an emerging paradigm providing a unifying solution to real-world problems, which may require both SML and CL abilities. We claim that SCL can i) connect the CL and SML communities, motivating their work towards the same goal, and ii) foster the design of hybrid approaches that can quickly adapt to new information (as in SML) without forgetting previous knowledge (as in CL). We conclude the paper with a motivating example and a set of experiments, highlighting the need for SCL by showing how CL and SML alone struggle in achieving rapid adaptation and knowledge retention.
CRoSS: A Continual Robotic Simulation Suite for Scalable Reinforcement Learning with High Task Diversity and Realistic Physics Simulation
Feb 04, 2026Continual reinforcement learning (CRL) requires agents to learn from a sequence of tasks without forgetting previously acquired policies. In this work, we introduce a novel benchmark suite for CRL based on realistically simulated robots in the Gazebo simulator. Our Continual Robotic Simulation Suite (CRoSS) benchmarks rely on two robotic platforms: a two-wheeled differential-drive robot with lidar, camera and bumper sensor, and a robotic arm with seven joints. The former represent an agent in line-following and object-pushing scenarios, where variation of visual and structural parameters yields a large number of distinct tasks, whereas the latter is used in two goal-reaching scenarios with high-level cartesian hand position control (modeled after the Continual World benchmark), and low-level control based on joint angles. For the robotic arm benchmarks, we provide additional kinematics-only variants that bypass the need for physical simulation (as long as no sensor readings are required), and which can be run two orders of magnitude faster. CRoSS is designed to be easily extensible and enables controlled studies of continual reinforcement learning in robotic settings with high physical realism, and in particular allow the use of almost arbitrary simulated sensors. To ensure reproducibility and ease of use, we provide a containerized setup (Apptainer) that runs out-of-the-box, and report performances of standard RL algorithms, including Deep Q-Networks (DQN) and policy gradient methods. This highlights the suitability as a scalable and reproducible benchmark for CRL research.
Continual Learning: Applications and the Road Forward
Nov 21, 2023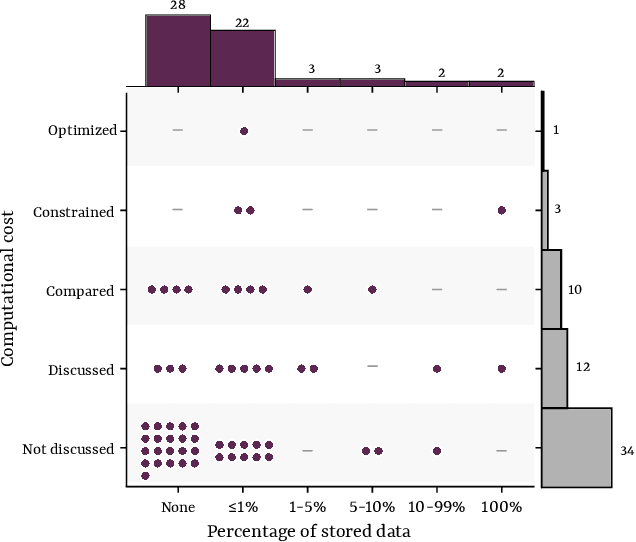
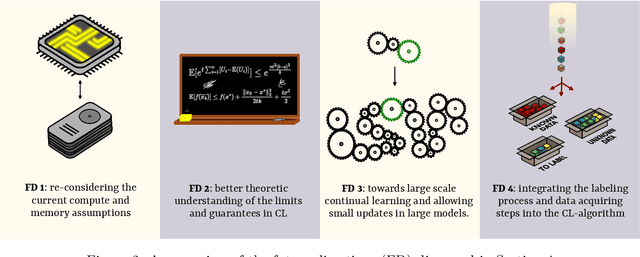
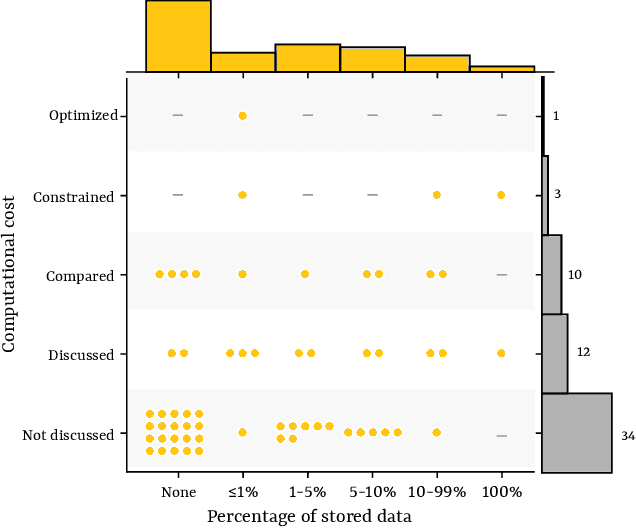
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
Large-scale gradient-based training of Mixtures of Factor Analyzers
Aug 26, 2023

Gaussian Mixture Models (GMMs) are a standard tool in data analysis. However, they face problems when applied to high-dimensional data (e.g., images) due to the size of the required full covariance matrices (CMs), whereas the use of diagonal or spherical CMs often imposes restrictions that are too severe. The Mixture of Factor analyzers (MFA) model is an important extension of GMMs, which allows to smoothly interpolate between diagonal and full CMs based on the number of \textit{factor loadings} $l$. MFA has successfully been applied for modeling high-dimensional image data. This article contributes both a theoretical analysis as well as a new method for efficient high-dimensional MFA training by stochastic gradient descent, starting from random centroid initializations. This greatly simplifies the training and initialization process, and avoids problems of batch-type algorithms such Expectation-Maximization (EM) when training with huge amounts of data. In addition, by exploiting the properties of the matrix determinant lemma, we prove that MFA training and inference/sampling can be performed based on precision matrices, which does not require matrix inversions after training is completed. At training time, the methods requires the inversion of $l\times l$ matrices only. Besides the theoretical analysis and proofs, we apply MFA to typical image datasets such as SVHN and MNIST, and demonstrate the ability to perform sample generation and outlier detection.
Adiabatic replay for continual learning
Mar 23, 2023Conventional replay-based approaches to continual learning (CL) require, for each learning phase with new data, the replay of samples representing all of the previously learned knowledge in order to avoid catastrophic forgetting. Since the amount of learned knowledge grows over time in CL problems, generative replay spends an increasing amount of time just re-learning what is already known. In this proof-of-concept study, we propose a replay-based CL strategy that we term adiabatic replay (AR), which derives its efficiency from the (reasonable) assumption that each new learning phase is adiabatic, i.e., represents only a small addition to existing knowledge. Each new learning phase triggers a sampling process that selectively replays, from the body of existing knowledge, just such samples that are similar to the new data, in contrast to replaying all of it. Complete replay is not required since AR represents the data distribution by GMMs, which are capable of selectively updating their internal representation only where data statistics have changed. As long as additions are adiabatic, the amount of to-be-replayed samples need not to depend on the amount of previously acquired knowledge at all. We verify experimentally that AR is superior to state-of-the-art deep generative replay using VAEs.
A Framework for the Automated Parameterization of a Sensorless Bearing Fault Detection Pipeline
Mar 15, 2023
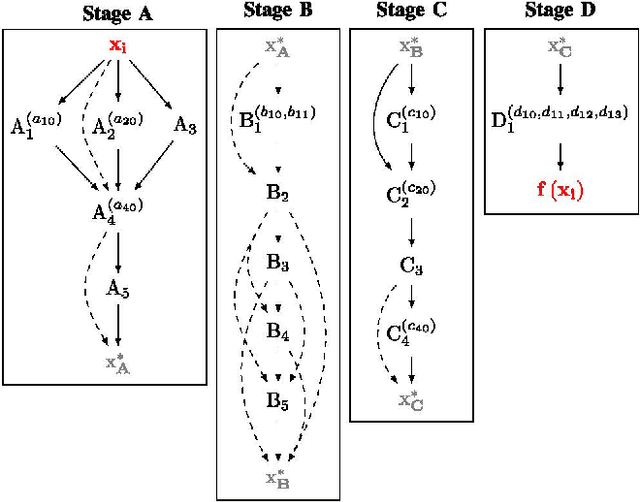


This study proposes a framework for the automated hyperparameter optimization of a bearing fault detection pipeline for permanent magnet synchronous motors (PMSMs) without the need of external sensors. A automated machine learning (AutoML) pipeline search is performed by means of a genetic optimization to reduce human induced bias due to inappropriate parameterizations. For this purpose, a search space is defined, which includes general methods of signal processing and manipulation as well as methods tailored to the respective task and domain. The proposed framework is evaluated on the bearing fault detection use case under real world conditions. Considerations on the generalization of the deployed fault detection pipelines are also taken into account. Likewise, attention was paid to experimental studies for evaluations of the robustness of the fault detection pipeline to variations of the motors working condition parameters between the training and test domain. The present work contributes to the research of fault detection on rotating machinery in the following terms: (1) Reduction of the human induced bias to the data science process, while still considering expert and task related knowledge, ending in a generic search approach (2) tackling the bearing fault detection task without the need for external sensors (sensorless) (3) learning a domain robust fault detection pipeline applicable to varying motor operating parameters without the need of re-parameterizations or fine-tuning (4) investigations on working condition discrepancies with an excessive degree to determine the pipeline limitations regarding the abstraction of the motor parameters and the pipeline hyperparameters
Beyond Supervised Continual Learning: a Review
Aug 30, 2022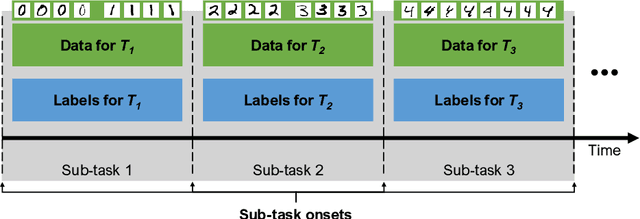
Continual Learning (CL, sometimes also termed incremental learning) is a flavor of machine learning where the usual assumption of stationary data distribution is relaxed or omitted. When naively applying, e.g., DNNs in CL problems, changes in the data distribution can cause the so-called catastrophic forgetting (CF) effect: an abrupt loss of previous knowledge. Although many significant contributions to enabling CL have been made in recent years, most works address supervised (classification) problems. This article reviews literature that study CL in other settings, such as learning with reduced supervision, fully unsupervised learning, and reinforcement learning. Besides proposing a simple schema for classifying CL approaches w.r.t. their level of autonomy and supervision, we discuss the specific challenges associated with each setting and the potential contributions to the field of CL in general.
A Study of Continual Learning Methods for Q-Learning
Jun 08, 2022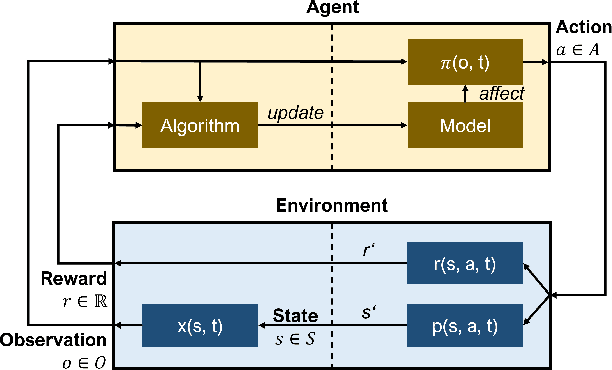


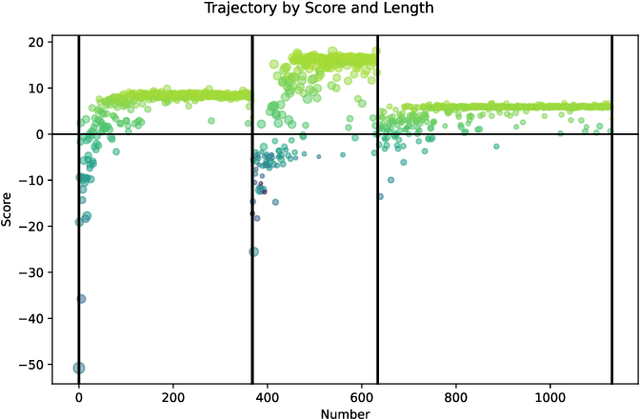
We present an empirical study on the use of continual learning (CL) methods in a reinforcement learning (RL) scenario, which, to the best of our knowledge, has not been described before. CL is a very active recent research topic concerned with machine learning under non-stationary data distributions. Although this naturally applies to RL, the use of dedicated CL methods is still uncommon. This may be due to the fact that CL methods often assume a decomposition of CL problems into disjoint sub-tasks of stationary distribution, that the onset of these sub-tasks is known, and that sub-tasks are non-contradictory. In this study, we perform an empirical comparison of selected CL methods in a RL problem where a physically simulated robot must follow a racetrack by vision. In order to make CL methods applicable, we restrict the RL setting and introduce non-conflicting subtasks of known onset, which are however not disjoint and whose distribution, from the learner's point of view, is still non-stationary. Our results show that dedicated CL methods can significantly improve learning when compared to the baseline technique of "experience replay".
A new perspective on probabilistic image modeling
Mar 21, 2022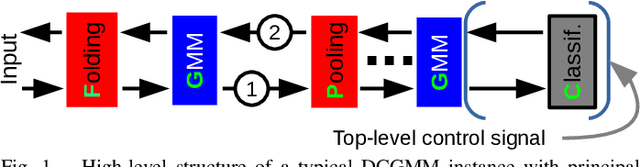


We present the Deep Convolutional Gaussian Mixture Model (DCGMM), a new probabilistic approach for image modeling capable of density estimation, sampling and tractable inference. DCGMM instances exhibit a CNN-like layered structure, in which the principal building blocks are convolutional Gaussian Mixture (cGMM) layers. A key innovation w.r.t. related models like sum-product networks (SPNs) and probabilistic circuits (PCs) is that each cGMM layer optimizes an independent loss function and therefore has an independent probabilistic interpretation. This modular approach permits intervening transformation layers to harness the full spectrum of (potentially non-invertible) mappings available to CNNs, e.g., max-pooling or half-convolutions. DCGMM sampling and inference are realized by a deep chain of hierarchical priors, where a sample generated by a given cGMM layer defines the parameters of sampling in the next-lower cGMM layer. For sampling through non-invertible transformation layers, we introduce a new gradient-based sharpening technique that exploits redundancy (overlap) in, e.g., half-convolutions. DCGMMs can be trained end-to-end by SGD from random initial conditions, much like CNNs. We show that DCGMMs compare favorably to several recent PC and SPN models in terms of inference, classification and sampling, the latter particularly for challenging datasets such as SVHN. We provide a public TF2 implementation.
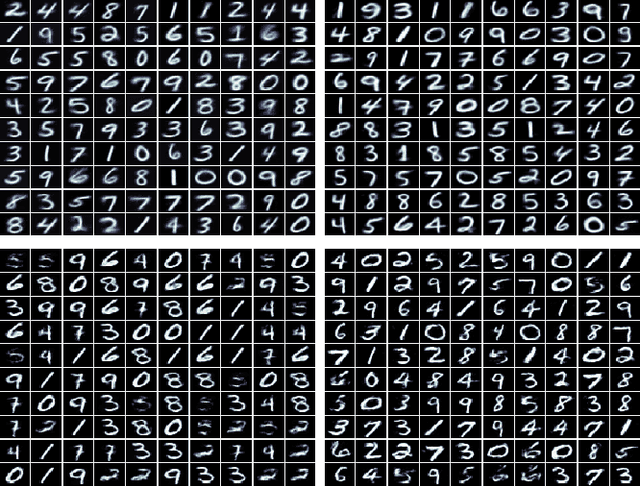
An Investigation of Replay-based Approaches for Continual Learning
Aug 15, 2021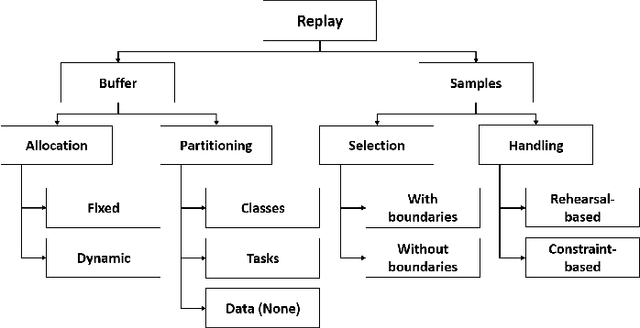
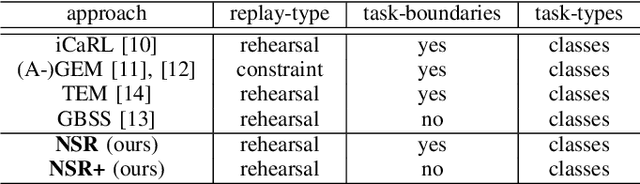


Continual learning (CL) is a major challenge of machine learning (ML) and describes the ability to learn several tasks sequentially without catastrophic forgetting (CF). Recent works indicate that CL is a complex topic, even more so when real-world scenarios with multiple constraints are involved. Several solution classes have been proposed, of which so-called replay-based approaches seem very promising due to their simplicity and robustness. Such approaches store a subset of past samples in a dedicated memory for later processing: while this does not solve all problems, good results have been obtained. In this article, we empirically investigate replay-based approaches of continual learning and assess their potential for applications. Selected recent approaches as well as own proposals are compared on a common set of benchmarks, with a particular focus on assessing the performance of different sample selection strategies. We find that the impact of sample selection increases when a smaller number of samples is stored. Nevertheless, performance varies strongly between different replay approaches. Surprisingly, we find that the most naive rehearsal-based approaches that we propose here can outperform recent state-of-the-art methods.