 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas: A Novel Pathology Foundation Model by Mayo Clinic, Charité, and Aignostics
Jan 10, 2025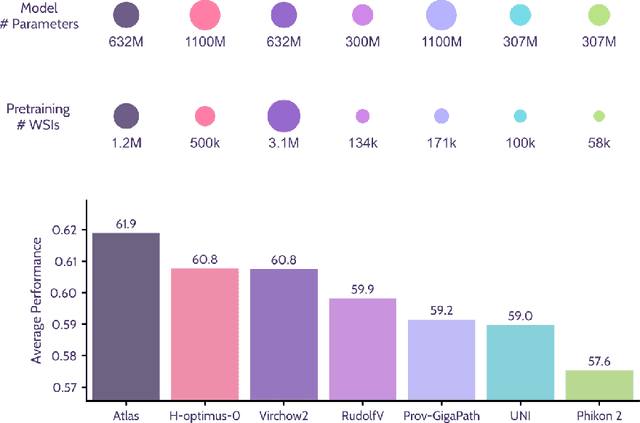
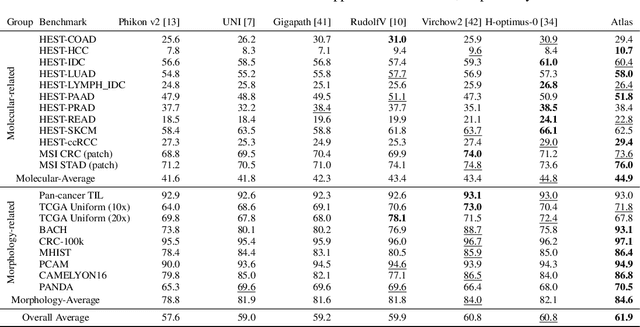
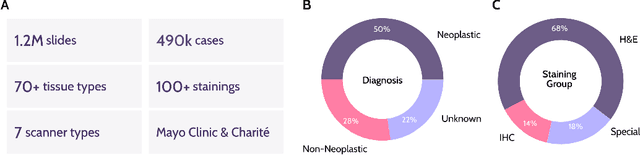
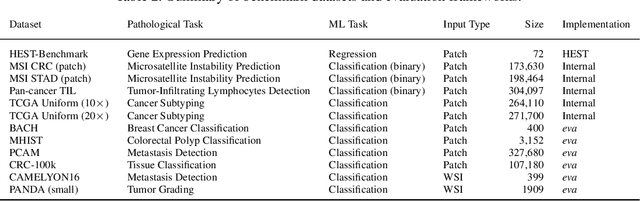
Recent advances in digital pathology have demonstrated the effectiveness of foundation models across diverse applications. In this report, we present Atlas, a novel vision foundation model based on the RudolfV approach. Our model was trained on a dataset comprising 1.2 million histopathology whole slide images, collected from two medical institutions: Mayo Clinic and Charit\'e - Universt\"atsmedizin Berlin. Comprehensive evaluations show that Atlas achieves state-of-the-art performance across twenty-one public benchmark datasets, even though it is neither the largest model by parameter count nor by training dataset size.
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Mar 26, 2024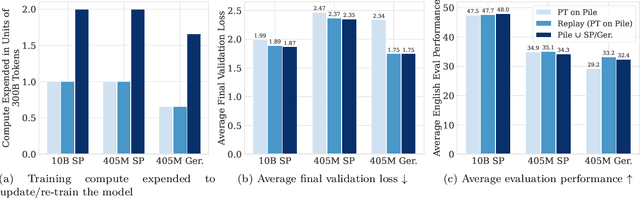
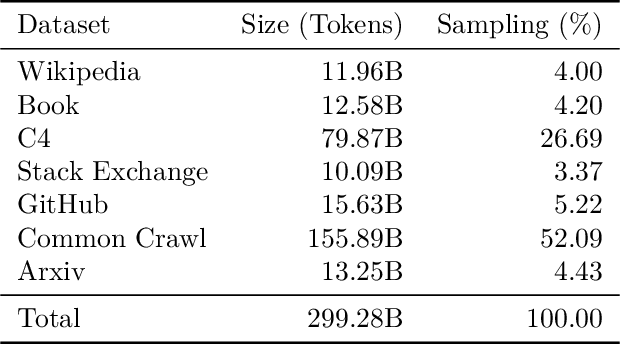
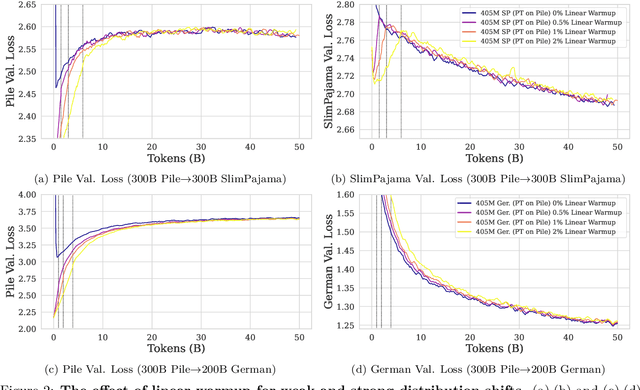
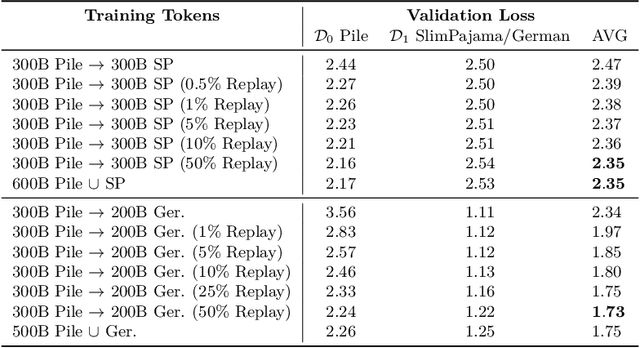
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
A Study of Continual Learning Under Language Shift
Nov 02, 2023The recent increase in data and model scale for language model pre-training has led to huge training costs. In scenarios where new data become available over time, updating a model instead of fully retraining it would therefore provide significant gains. In this paper, we study the benefits and downsides of updating a language model when new data comes from new languages - the case of continual learning under language shift. Starting from a monolingual English language model, we incrementally add data from Norwegian and Icelandic to investigate how forward and backward transfer effects depend on the pre-training order and characteristics of languages, for different model sizes and learning rate schedulers. Our results show that, while forward transfer is largely positive and independent of language order, backward transfer can be either positive or negative depending on the order and characteristics of new languages. To explain these patterns we explore several language similarity metrics and find that syntactic similarity appears to have the best correlation with our results.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023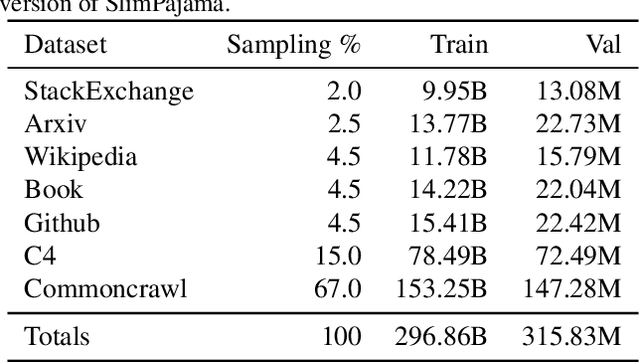
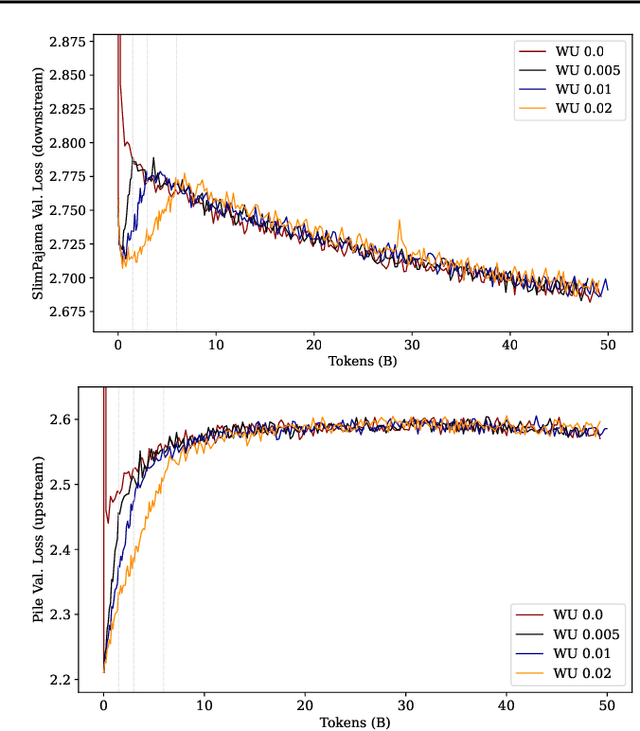
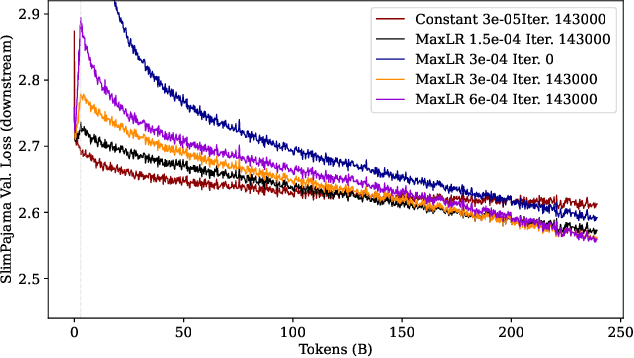
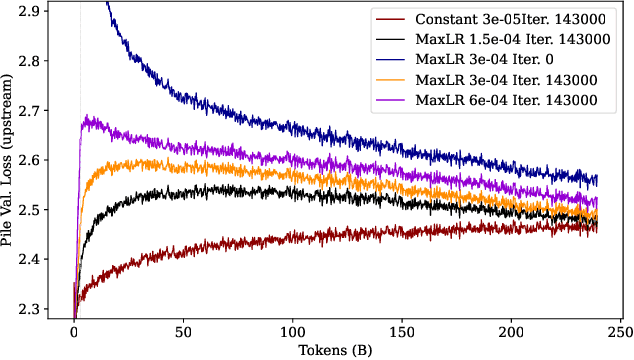
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
Beyond Supervised Continual Learning: a Review
Aug 30, 2022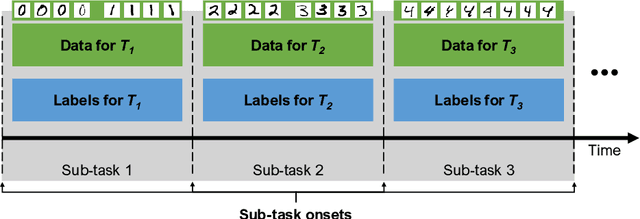
Continual Learning (CL, sometimes also termed incremental learning) is a flavor of machine learning where the usual assumption of stationary data distribution is relaxed or omitted. When naively applying, e.g., DNNs in CL problems, changes in the data distribution can cause the so-called catastrophic forgetting (CF) effect: an abrupt loss of previous knowledge. Although many significant contributions to enabling CL have been made in recent years, most works address supervised (classification) problems. This article reviews literature that study CL in other settings, such as learning with reduced supervision, fully unsupervised learning, and reinforcement learning. Besides proposing a simple schema for classifying CL approaches w.r.t. their level of autonomy and supervision, we discuss the specific challenges associated with each setting and the potential contributions to the field of CL in general.
Scaling the Number of Tasks in Continual Learning
Jul 10, 2022
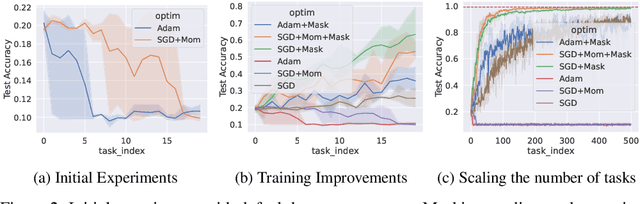

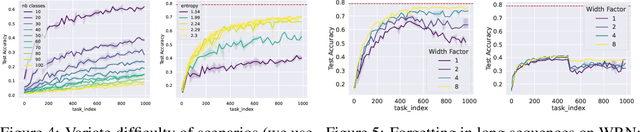
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
Continual Feature Selection: Spurious Features in Continual Learning
Mar 02, 2022

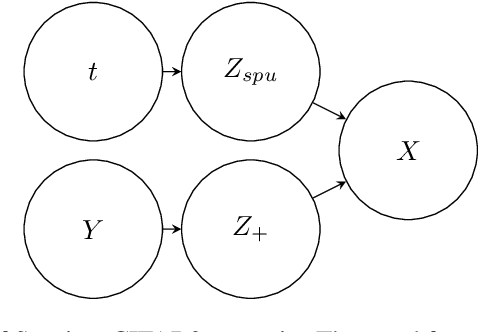

Continual Learning (CL) is the research field addressing learning settings where the data distribution is not static. This paper studies spurious features' influence on continual learning algorithms. Indeed, we show that learning algorithms solve tasks by overfitting features that are not generalizable. To better understand these phenomena and their impact, we propose a domain incremental scenario that we study through various out-of-distribution generalizations and continual learning algorithms. The experiments of this paper show that continual learning algorithms face two related challenges: (1) the spurious features challenge: some features are well correlated with labels in train data but not in test data due to a covariate shift between train and test. (2) the local spurious features challenge: some features correlate well with labels within a task but not within the whole task sequence. The challenge is to learn general features that are neither spurious (in general) nor locally spurious. We prove that the latter is a major cause of performance decrease in continual learning along with catastrophic forgetting. Our results indicate that the best solution to overcome the feature selection problems varies depending on the correlation between spurious features (SFs) and labels. The vanilla replay approach seems to be a powerful approach to deal with SFs, which could explain its good performance in the continual learning literature. This paper presents a different way of understanding performance decrease in continual learning by describing the influence of spurious/local spurious features.
Sequoia: A Software Framework to Unify Continual Learning Research
Aug 03, 2021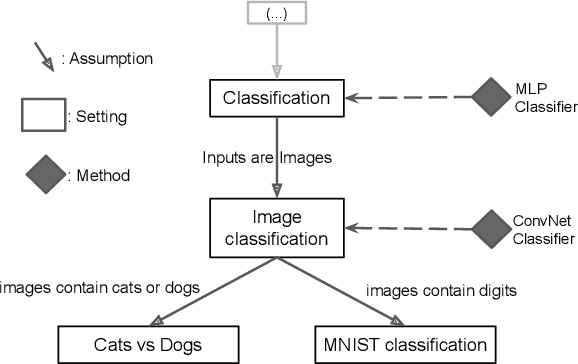
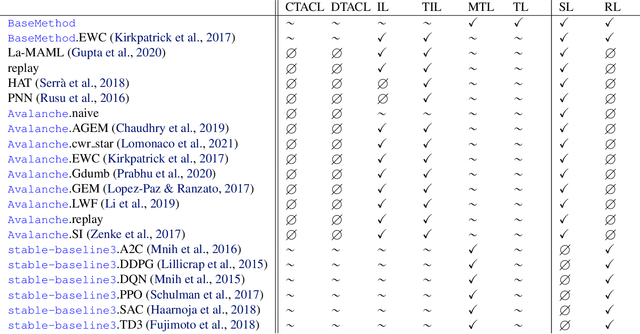
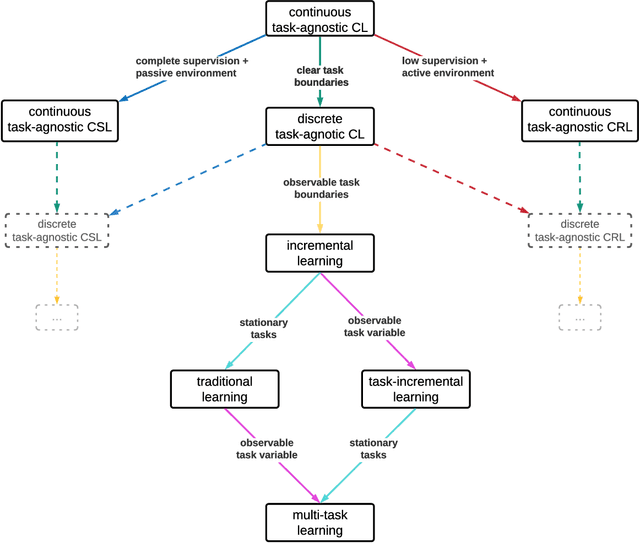
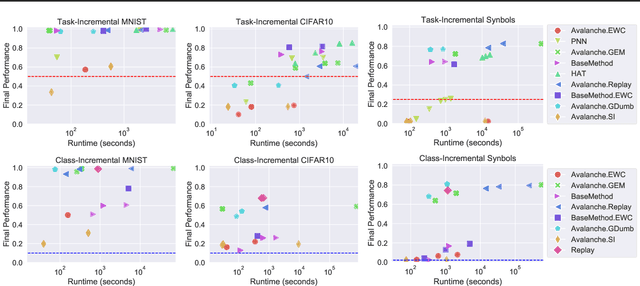
The field of Continual Learning (CL) seeks to develop algorithms that accumulate knowledge and skills over time through interaction with non-stationary environments and data distributions. Measuring progress in CL can be difficult because a plethora of evaluation procedures (ettings) and algorithmic solutions (methods) have emerged, each with their own potentially disjoint set of assumptions about the CL problem. In this work, we view each setting as a set of assumptions. We then create a tree-shaped hierarchy of the research settings in CL, in which more general settings become the parents of those with more restrictive assumptions. This makes it possible to use inheritance to share and reuse research, as developing a method for a given setting also makes it directly applicable onto any of its children. We instantiate this idea as a publicly available software framework called Sequoia, which features a variety of settings from both the Continual Supervised Learning (CSL) and Continual Reinforcement Learning (CRL) domains. Sequoia also includes a growing suite of methods which are easy to extend and customize, in addition to more specialized methods from third-party libraries. We hope that this new paradigm and its first implementation can serve as a foundation for the unification and acceleration of research in CL. You can help us grow the tree by visiting www.github.com/lebrice/Sequoia.
Continual Learning in Deep Networks: an Analysis of the Last Layer
Jun 03, 2021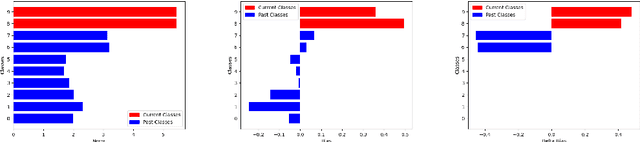
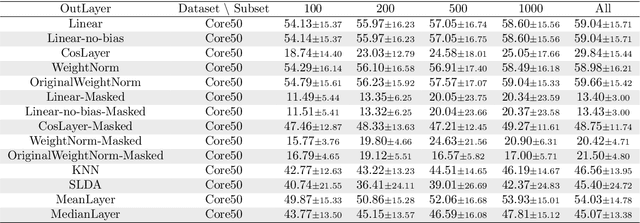


We study how different output layer types of a deep neural network learn and forget in continual learning settings. We describe the three factors affecting catastrophic forgetting in the output layer: (1) weights modifications, (2) interferences, and (3) projection drift. Our goal is to provide more insights into how different types of output layers can address (1) and (2). We also propose potential solutions and evaluate them on several benchmarks. We show that the best-performing output layer type depends on the data distribution drifts or the amount of data available. In particular, in some cases where a standard linear layer would fail, it is sufficient to change the parametrization and get significantly better performance while still training with SGD. Our results and analysis shed light on the dynamics of the output layer in continual learning scenarios and help select the best-suited output layer for a given scenario.
Understanding Continual Learning Settings with Data Distribution Drift Analysis
Apr 04, 2021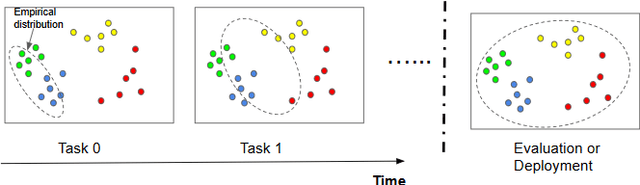
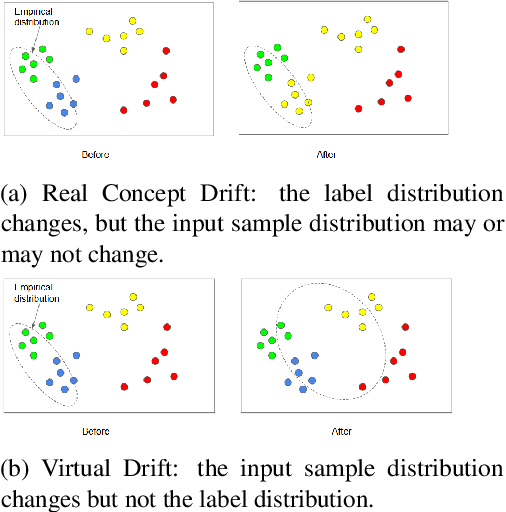

Classical machine learning algorithms often assume that the data are drawn i.i.d. from a stationary probability distribution. Recently, continual learning emerged as a rapidly growing area of machine learning where this assumption is relaxed, namely, where the data distribution is non-stationary, i.e., changes over time. However, data distribution drifts may interfere with the learning process and erase previously learned knowledge; thus, continual learning algorithms must include specialized mechanisms to deal with such distribution drifts. A distribution drift may change the class labels distribution, the input distribution, or both. Moreover, distribution drifts might be abrupt or gradual. In this paper, we aim to identify and categorize different types of data distribution drifts and potential assumptions about them, to better characterize various continual-learning scenarios. Moreover, we propose to use the distribution drift framework to provide more precise definitions of several terms commonly used in the continual learning field.