 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMislabeled examples detection viewed as probing machine learning models: concepts, survey and extensive benchmark
Oct 21, 2024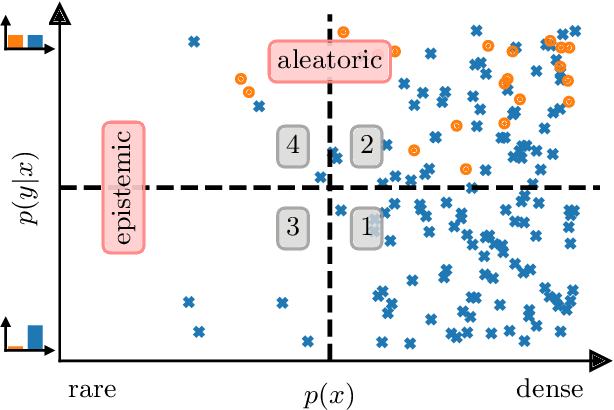
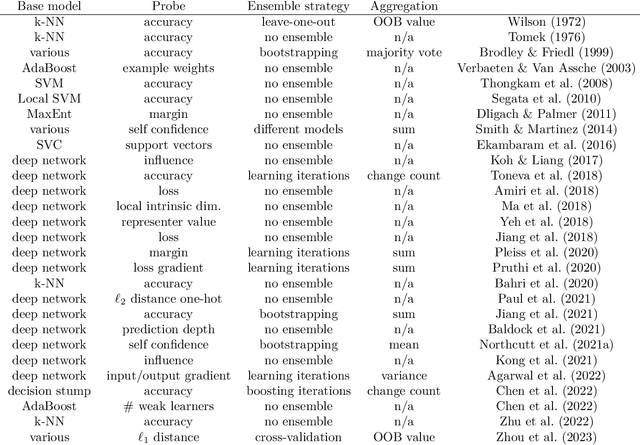
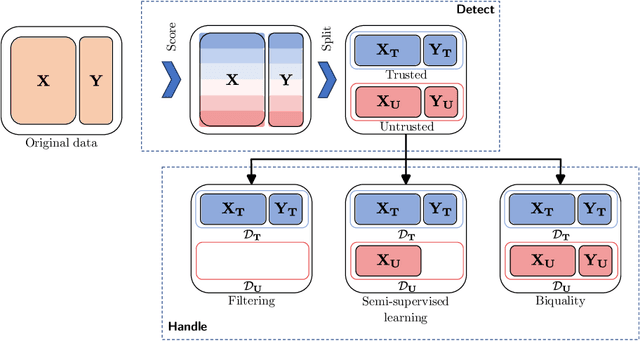
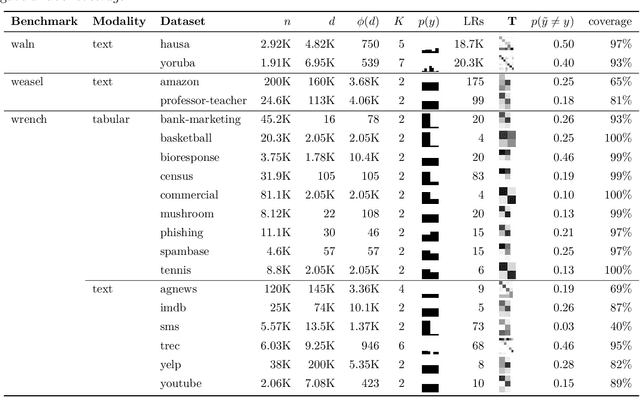
Mislabeled examples are ubiquitous in real-world machine learning datasets, advocating the development of techniques for automatic detection. We show that most mislabeled detection methods can be viewed as probing trained machine learning models using a few core principles. We formalize a modular framework that encompasses these methods, parameterized by only 4 building blocks, as well as a Python library that demonstrates that these principles can actually be implemented. The focus is on classifier-agnostic concepts, with an emphasis on adapting methods developed for deep learning models to non-deep classifiers for tabular data. We benchmark existing methods on (artificial) Completely At Random (NCAR) as well as (realistic) Not At Random (NNAR) labeling noise from a variety of tasks with imperfect labeling rules. This benchmark provides new insights as well as limitations of existing methods in this setup.
Lazy vs hasty: linearization in deep networks impacts learning schedule based on example difficulty
Sep 19, 2022
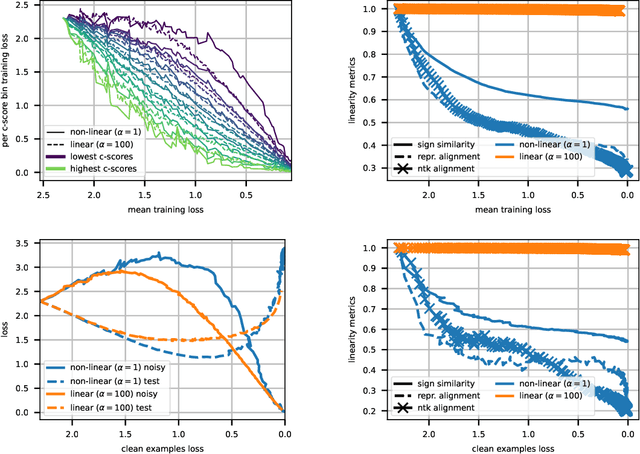
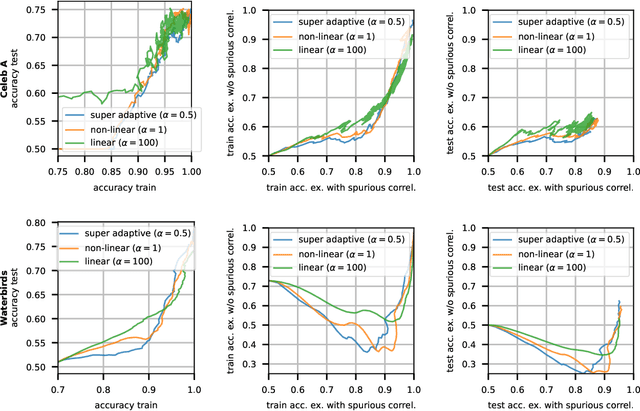
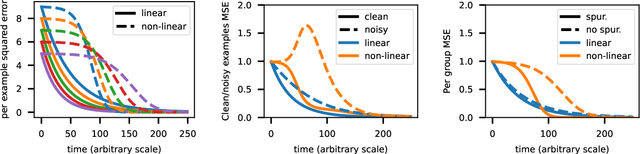
Among attempts at giving a theoretical account of the success of deep neural networks, a recent line of work has identified a so-called `lazy' regime in which the network can be well approximated by its linearization around initialization. Here we investigate the comparative effect of the lazy (linear) and feature learning (non-linear) regimes on subgroups of examples based on their difficulty. Specifically, we show that easier examples are given more weight in feature learning mode, resulting in faster training compared to more difficult ones. In other words, the non-linear dynamics tends to sequentialize the learning of examples of increasing difficulty. We illustrate this phenomenon across different ways to quantify example difficulty, including c-score, label noise, and in the presence of spurious correlations. Our results reveal a new understanding of how deep networks prioritize resources across example difficulty.
A Transfer Learning Pipeline for Educational Resource Discovery with Application in Leading Paragraph Generation
Jan 07, 2022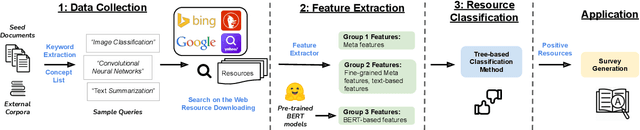

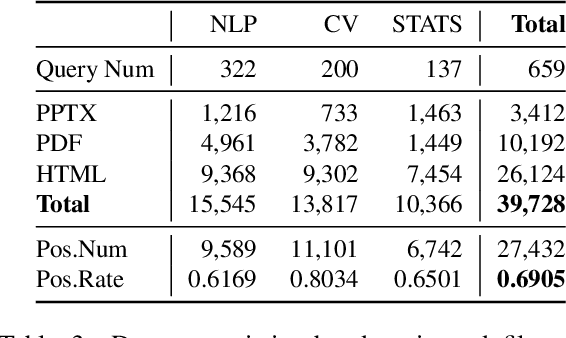

Effective human learning depends on a wide selection of educational materials that align with the learner's current understanding of the topic. While the Internet has revolutionized human learning or education, a substantial resource accessibility barrier still exists. Namely, the excess of online information can make it challenging to navigate and discover high-quality learning materials. In this paper, we propose the educational resource discovery (ERD) pipeline that automates web resource discovery for novel domains. The pipeline consists of three main steps: data collection, feature extraction, and resource classification. We start with a known source domain and conduct resource discovery on two unseen target domains via transfer learning. We first collect frequent queries from a set of seed documents and search on the web to obtain candidate resources, such as lecture slides and introductory blog posts. Then we introduce a novel pretrained information retrieval deep neural network model, query-document masked language modeling (QD-MLM), to extract deep features of these candidate resources. We apply a tree-based classifier to decide whether the candidate is a positive learning resource. The pipeline achieves F1 scores of 0.94 and 0.82 when evaluated on two similar but novel target domains. Finally, we demonstrate how this pipeline can benefit an application: leading paragraph generation for surveys. This is the first study that considers various web resources for survey generation, to the best of our knowledge. We also release a corpus of 39,728 manually labeled web resources and 659 queries from NLP, Computer Vision (CV), and Statistics (STATS).
CLICKER: A Computational LInguistics Classification Scheme for Educational Resources
Dec 16, 2021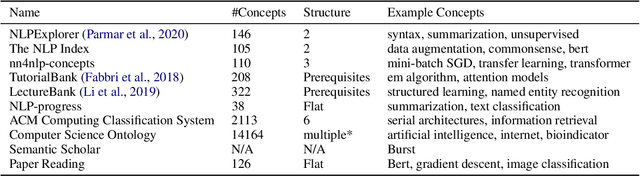
A classification scheme of a scientific subject gives an overview of its body of knowledge. It can also be used to facilitate access to research articles and other materials related to the subject. For example, the ACM Computing Classification System (CCS) is used in the ACM Digital Library search interface and also for indexing computer science papers. We observed that a comprehensive classification system like CCS or Mathematics Subject Classification (MSC) does not exist for Computational Linguistics (CL) and Natural Language Processing (NLP). We propose a classification scheme -- CLICKER for CL/NLP based on the analysis of online lectures from 77 university courses on this subject. The currently proposed taxonomy includes 334 topics and focuses on educational aspects of CL/NLP; it is based primarily, but not exclusively, on lecture notes from NLP courses. We discuss how such a taxonomy can help in various real-world applications, including tutoring platforms, resource retrieval, resource recommendation, prerequisite chain learning, and survey generation.
Continual Learning in Deep Networks: an Analysis of the Last Layer
Jun 03, 2021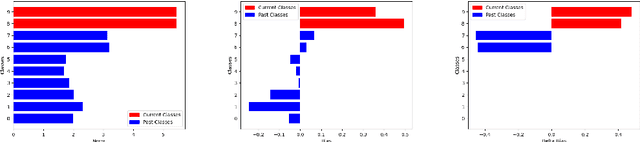
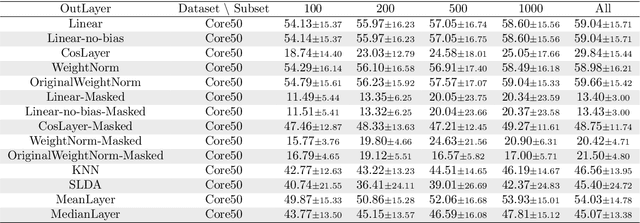


We study how different output layer types of a deep neural network learn and forget in continual learning settings. We describe the three factors affecting catastrophic forgetting in the output layer: (1) weights modifications, (2) interferences, and (3) projection drift. Our goal is to provide more insights into how different types of output layers can address (1) and (2). We also propose potential solutions and evaluate them on several benchmarks. We show that the best-performing output layer type depends on the data distribution drifts or the amount of data available. In particular, in some cases where a standard linear layer would fail, it is sufficient to change the parametrization and get significantly better performance while still training with SGD. Our results and analysis shed light on the dynamics of the output layer in continual learning scenarios and help select the best-suited output layer for a given scenario.
Implicit Regularization in Deep Learning: A View from Function Space
Aug 03, 2020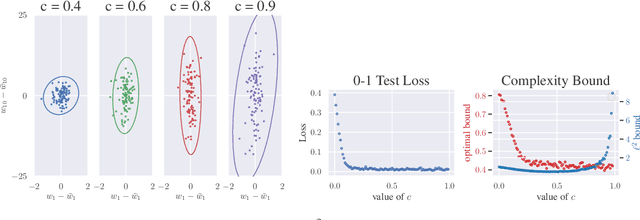
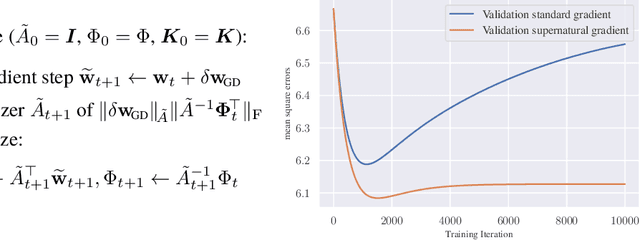
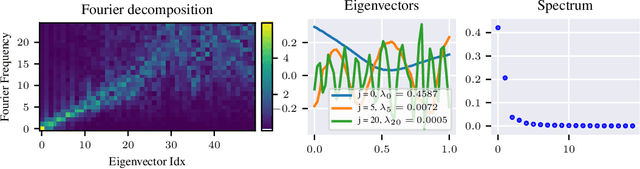
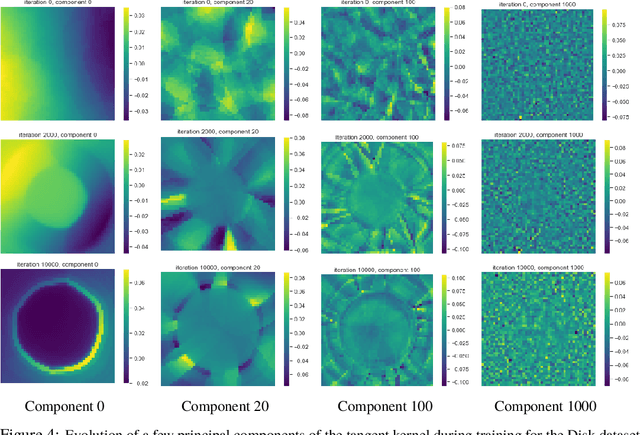
We approach the problem of implicit regularization in deep learning from a geometrical viewpoint. We highlight a possible regularization effect induced by a dynamical alignment of the neural tangent features introduced by Jacot et al, along a small number of task-relevant directions. By extrapolating a new analysis of Rademacher complexity bounds in linear models, we propose and study a new heuristic complexity measure for neural networks which captures this phenomenon, in terms of sequences of tangent kernel classes along in the learning trajectories.
Revisiting Loss Modelling for Unstructured Pruning
Jun 22, 2020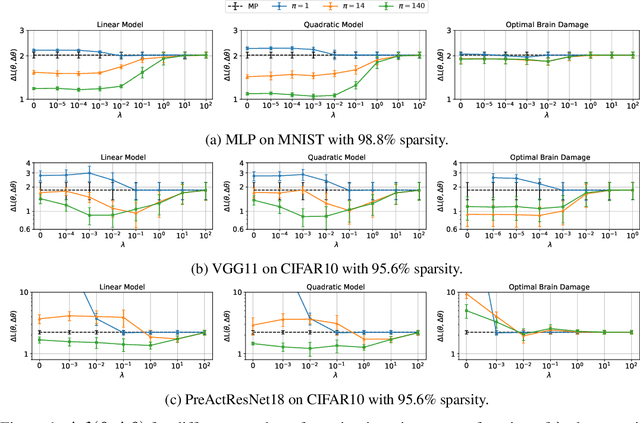
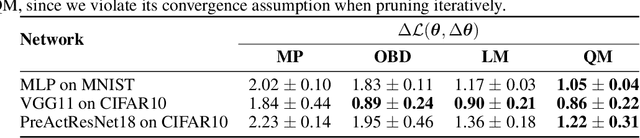

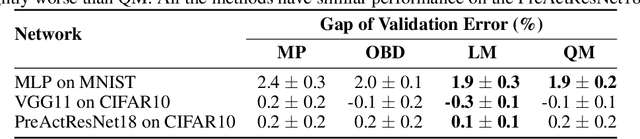
By removing parameters from deep neural networks, unstructured pruning methods aim at cutting down memory footprint and computational cost, while maintaining prediction accuracy. In order to tackle this otherwise intractable problem, many of these methods model the loss landscape using first or second order Taylor expansions to identify which parameters can be discarded. We revisit loss modelling for unstructured pruning: we show the importance of ensuring locality of the pruning steps. We systematically compare first and second order Taylor expansions and empirically show that both can reach similar levels of performance. Finally, we show that better preserving the original network function does not necessarily transfer to better performing networks after fine-tuning, suggesting that only considering the impact of pruning on the loss might not be a sufficient objective to design good pruning criteria.
Fast Approximate Natural Gradient Descent in a Kronecker-factored Eigenbasis
Jun 11, 2018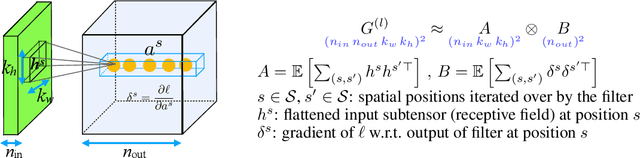
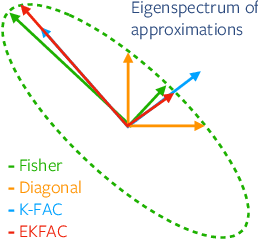
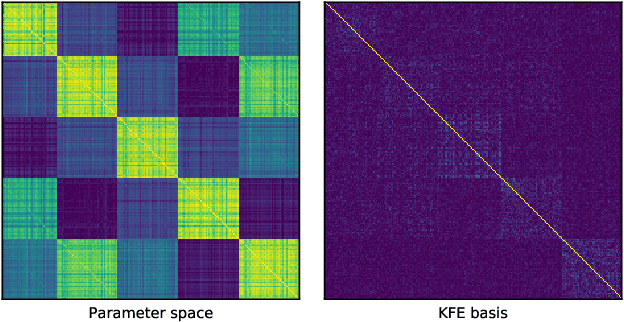
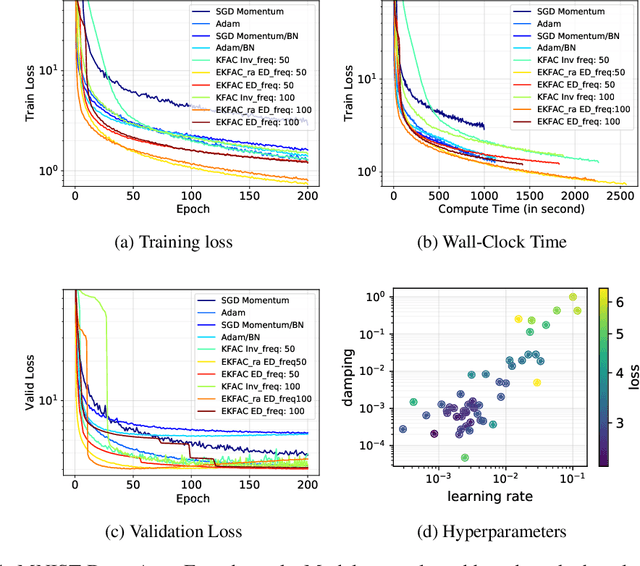
Optimization algorithms that leverage gradient covariance information, such as variants of natural gradient descent (Amari, 1998), offer the prospect of yielding more effective descent directions. For models with many parameters, the covariance matrix they are based on becomes gigantic, making them inapplicable in their original form. This has motivated research into both simple diagonal approximations and more sophisticated factored approximations such as KFAC (Heskes, 2000; Martens & Grosse, 2015; Grosse & Martens, 2016). In the present work we draw inspiration from both to propose a novel approximation that is provably better than KFAC and amendable to cheap partial updates. It consists in tracking a diagonal variance, not in parameter coordinates, but in a Kronecker-factored eigenbasis, in which the diagonal approximation is likely to be more effective. Experiments show improvements over KFAC in optimization speed for several deep network architectures.