 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Planning with Latent World Models
Apr 03, 2026Model predictive control (MPC) with learned world models has emerged as a promising paradigm for embodied control, particularly for its ability to generalize zero-shot when deployed in new environments. However, learned world models often struggle with long-horizon control due to the accumulation of prediction errors and the exponentially growing search space. In this work, we address these challenges by learning latent world models at multiple temporal scales and performing hierarchical planning across these scales, enabling long-horizon reasoning while substantially reducing inference-time planning complexity. Our approach serves as a modular planning abstraction that applies across diverse latent world-model architectures and domains. We demonstrate that this hierarchical approach enables zero-shot control on real-world non-greedy robotic tasks, achieving a 70% success rate on pick-&-place using only a final goal specification, compared to 0% for a single-level world model. In addition, across physics-based simulated environments including push manipulation and maze navigation, hierarchical planning achieves higher success while requiring up to 4x less planning-time compute.
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Mar 17, 2026We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
Sep 16, 2025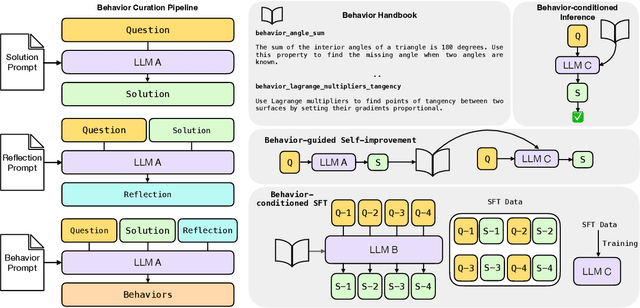



Large language models (LLMs) now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token usage and latency. This saturation of the context window leaves less capacity for exploration. We study a simple mechanism that converts recurring reasoning fragments into concise, reusable "behaviors" (name + instruction) via the model's own metacognitive analysis of prior traces. These behaviors are stored in a "behavior handbook" which supplies them to the model in-context at inference or distills them into parameters via supervised fine-tuning. This approach achieves improved test-time reasoning across three different settings - 1) Behavior-conditioned inference: Providing the LLM relevant behaviors in-context during reasoning reduces number of reasoning tokens by up to 46% while matching or improving baseline accuracy; 2) Behavior-guided self-improvement: Without any parameter updates, the model improves its own future reasoning by leveraging behaviors from its own past problem solving attempts. This yields up to 10% higher accuracy than a naive critique-and-revise baseline; and 3) Behavior-conditioned SFT: SFT on behavior-conditioned reasoning traces is more effective at converting non-reasoning models into reasoning models as compared to vanilla SFT. Together, these results indicate that turning slow derivations into fast procedural hints enables LLMs to remember how to reason, not just what to conclude.
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Jun 11, 2025



Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair -- a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9\%, while the best open-source state-of-the-art video-language model achieves 40.2\% compared to random performance at 25\%.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
Scaling Language-Free Visual Representation Learning
Apr 01, 2025



Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is often attributed to the semantics introduced by language supervision, even though visual SSL and CLIP models are often trained on different data. In this work, we ask the question: "Do visual self-supervised approaches lag behind CLIP due to the lack of language supervision, or differences in the training data?" We study this question by training both visual SSL and CLIP models on the same MetaCLIP data, and leveraging VQA as a diverse testbed for vision encoders. In this controlled setup, visual SSL models scale better than CLIP models in terms of data and model capacity, and visual SSL performance does not saturate even after scaling up to 7B parameters. Consequently, we observe visual SSL methods achieve CLIP-level performance on a wide range of VQA and classic vision benchmarks. These findings demonstrate that pure visual SSL can match language-supervised visual pretraining at scale, opening new opportunities for vision-centric representation learning.