 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of On-Device Streaming ASR: A Compact, High-Accuracy English Model for Low-Latency Inference
Apr 16, 2026Deploying high-quality automatic speech recognition (ASR) on edge devices requires models that jointly optimize accuracy, latency, and memory footprint while operating entirely on CPU without GPU acceleration. We conduct a systematic empirical study of state-of-the-art ASR architectures, encompassing encoder-decoder, transducer, and LLM-based paradigms, evaluated across batch, chunked, and streaming inference modes. Through a comprehensive benchmark of over 50 configurations spanning OpenAI Whisper, NVIDIA Nemotron, Parakeet TDT, Canary, Conformer Transducer, and Qwen3-ASR, we identify NVIDIA's Nemotron Speech Streaming as the strongest candidate for real-time English streaming on resource-constrained hardware. We then re-implement the complete streaming inference pipeline in ONNX Runtime and conduct a controlled evaluation of multiple post-training quantization strategies, including importance-weighted k-quant, mixed-precision schemes, and round-to-nearest quantization, combined with graph-level operator fusion. These optimizations reduce the model from 2.47 GB to as little as 0.67 GB while maintaining word error rate (WER) within 1% absolute of the full-precision PyTorch baseline. Our recommended configuration, the int4 k-quant variant, achieves 8.20% average streaming WER across eight standard benchmarks, running comfortably faster than real-time on CPU with 0.56 s algorithmic latency, establishing a new quality-efficiency Pareto point for on-device streaming ASR.
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
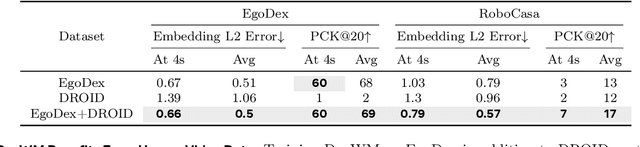
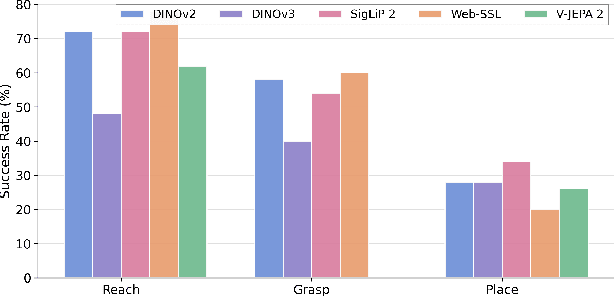
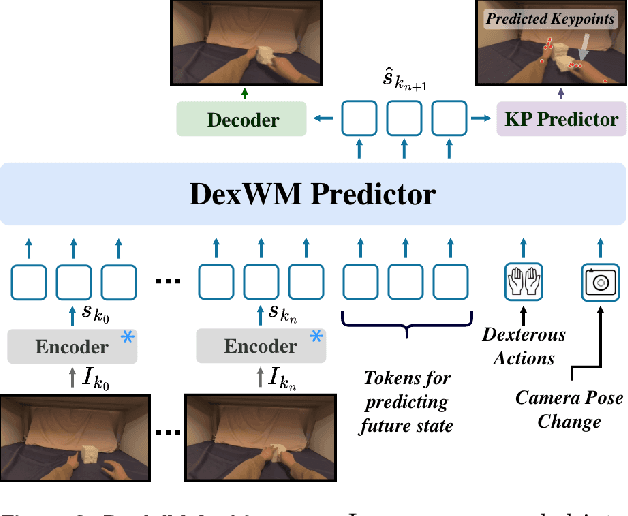
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Scaling Language-Free Visual Representation Learning
Apr 01, 2025



Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is often attributed to the semantics introduced by language supervision, even though visual SSL and CLIP models are often trained on different data. In this work, we ask the question: "Do visual self-supervised approaches lag behind CLIP due to the lack of language supervision, or differences in the training data?" We study this question by training both visual SSL and CLIP models on the same MetaCLIP data, and leveraging VQA as a diverse testbed for vision encoders. In this controlled setup, visual SSL models scale better than CLIP models in terms of data and model capacity, and visual SSL performance does not saturate even after scaling up to 7B parameters. Consequently, we observe visual SSL methods achieve CLIP-level performance on a wide range of VQA and classic vision benchmarks. These findings demonstrate that pure visual SSL can match language-supervised visual pretraining at scale, opening new opportunities for vision-centric representation learning.
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Dec 18, 2024



In this work, we propose Visual-Predictive Instruction Tuning (VPiT) - a simple and effective extension to visual instruction tuning that enables a pretrained LLM to quickly morph into an unified autoregressive model capable of generating both text and visual tokens. VPiT teaches an LLM to predict discrete text tokens and continuous visual tokens from any input sequence of image and text data curated in an instruction-following format. Our empirical investigation reveals several intriguing properties of VPiT: (1) visual generation ability emerges as a natural byproduct of improved visual understanding, and can be unlocked efficiently with a small amount of generation data; (2) while we find understanding and generation to be mutually beneficial, understanding data contributes to both capabilities more effectively than generation data. Building upon these findings, we train our MetaMorph model and achieve competitive performance on both visual understanding and generation. In visual generation, MetaMorph can leverage the world knowledge and reasoning abilities gained from LLM pretraining, and overcome common failure modes exhibited by other generation models. Our results suggest that LLMs may have strong "prior" vision capabilities that can be efficiently adapted to both visual understanding and generation with a relatively simple instruction tuning process.
NowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024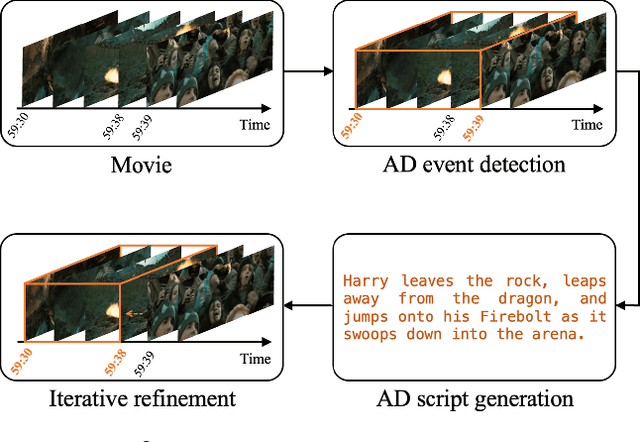
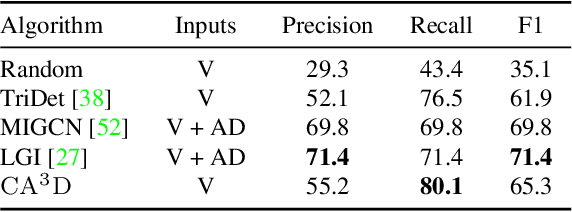
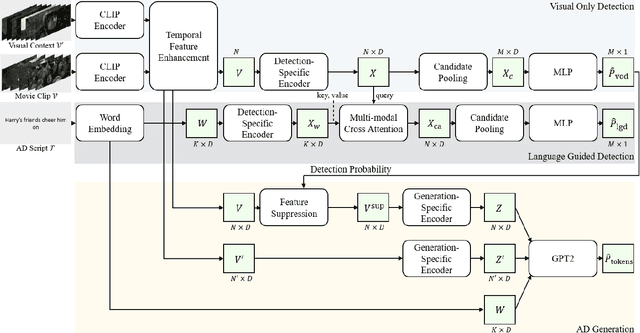

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
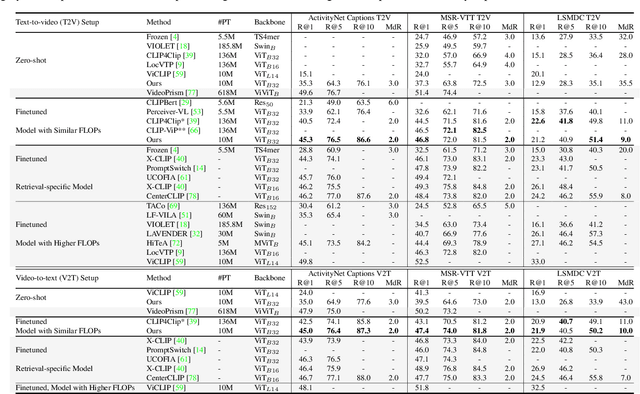
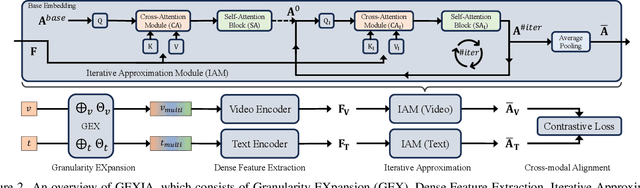
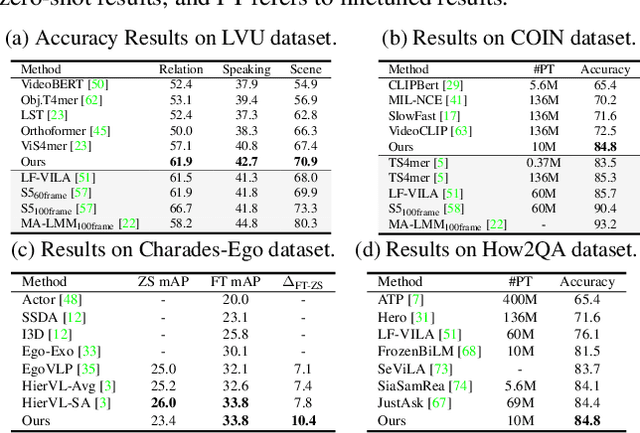
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.