 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Leech Quantization for Visual Tokenization and Generation
Dec 16, 2025



Non-parametric quantization has received much attention due to its efficiency on parameters and scalability to a large codebook. In this paper, we present a unified formulation of different non-parametric quantization methods through the lens of lattice coding. The geometry of lattice codes explains the necessity of auxiliary loss terms when training auto-encoders with certain existing lookup-free quantization variants such as BSQ. As a step forward, we explore a few possible candidates, including random lattices, generalized Fibonacci lattices, and densest sphere packing lattices. Among all, we find the Leech lattice-based quantization method, which is dubbed as Spherical Leech Quantization ($Λ_{24}$-SQ), leads to both a simplified training recipe and an improved reconstruction-compression tradeoff thanks to its high symmetry and even distribution on the hypersphere. In image tokenization and compression tasks, this quantization approach achieves better reconstruction quality across all metrics than BSQ, the best prior art, while consuming slightly fewer bits. The improvement also extends to state-of-the-art auto-regressive image generation frameworks.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
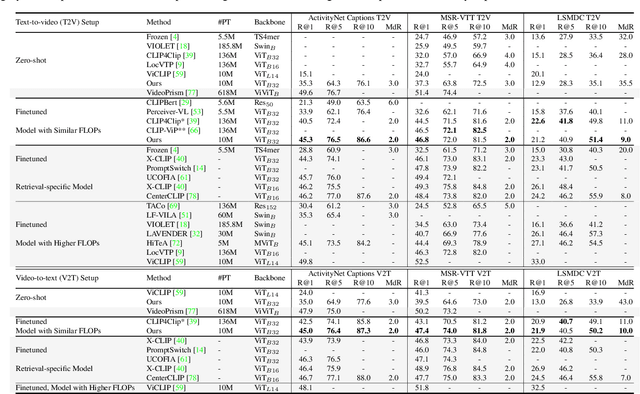
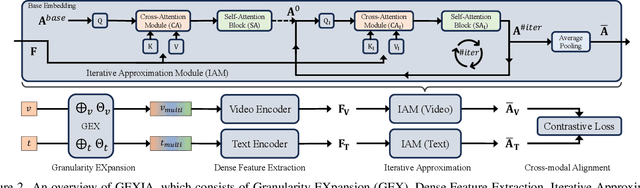
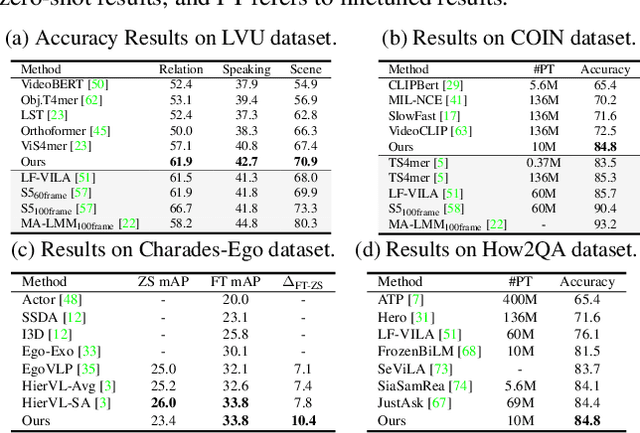
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
Self-Supervised Multi-Object Tracking with Path Consistency
Apr 08, 2024In this paper, we propose a novel concept of path consistency to learn robust object matching without using manual object identity supervision. Our key idea is that, to track a object through frames, we can obtain multiple different association results from a model by varying the frames it can observe, i.e., skipping frames in observation. As the differences in observations do not alter the identities of objects, the obtained association results should be consistent. Based on this rationale, we generate multiple observation paths, each specifying a different set of frames to be skipped, and formulate the Path Consistency Loss that enforces the association results are consistent across different observation paths. We use the proposed loss to train our object matching model with only self-supervision. By extensive experiments on three tracking datasets (MOT17, PersonPath22, KITTI), we demonstrate that our method outperforms existing unsupervised methods with consistent margins on various evaluation metrics, and even achieves performance close to supervised methods.
Challenges of Zero-Shot Recognition with Vision-Language Models: Granularity and Correctness
Jun 28, 2023



This paper investigates the challenges of applying vision-language models (VLMs) to zero-shot visual recognition tasks in an open-world setting, with a focus on contrastive vision-language models such as CLIP. We first examine the performance of VLMs on concepts of different granularity levels. We propose a way to fairly evaluate the performance discrepancy under two experimental setups and find that VLMs are better at recognizing fine-grained concepts. Furthermore, we find that the similarity scores from VLMs do not strictly reflect the correctness of the textual inputs given visual input. We propose an evaluation protocol to test our hypothesis that the scores can be biased towards more informative descriptions, and the nature of the similarity score between embedding makes it challenging for VLMs to recognize the correctness between similar but wrong descriptions. Our study highlights the challenges of using VLMs in open-world settings and suggests directions for future research to improve their zero-shot capabilities.
ScaleDet: A Scalable Multi-Dataset Object Detector
Jun 08, 2023



Multi-dataset training provides a viable solution for exploiting heterogeneous large-scale datasets without extra annotation cost. In this work, we propose a scalable multi-dataset detector (ScaleDet) that can scale up its generalization across datasets when increasing the number of training datasets. Unlike existing multi-dataset learners that mostly rely on manual relabelling efforts or sophisticated optimizations to unify labels across datasets, we introduce a simple yet scalable formulation to derive a unified semantic label space for multi-dataset training. ScaleDet is trained by visual-textual alignment to learn the label assignment with label semantic similarities across datasets. Once trained, ScaleDet can generalize well on any given upstream and downstream datasets with seen and unseen classes. We conduct extensive experiments using LVIS, COCO, Objects365, OpenImages as upstream datasets, and 13 datasets from Object Detection in the Wild (ODinW) as downstream datasets. Our results show that ScaleDet achieves compelling strong model performance with an mAP of 50.7 on LVIS, 58.8 on COCO, 46.8 on Objects365, 76.2 on OpenImages, and 71.8 on ODinW, surpassing state-of-the-art detectors with the same backbone.
Improving Dense Contrastive Learning with Dense Negative Pairs
Oct 11, 2022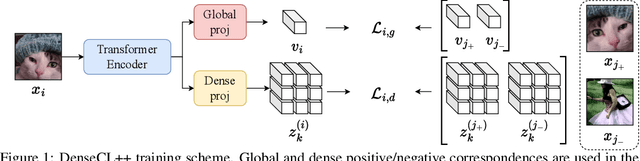
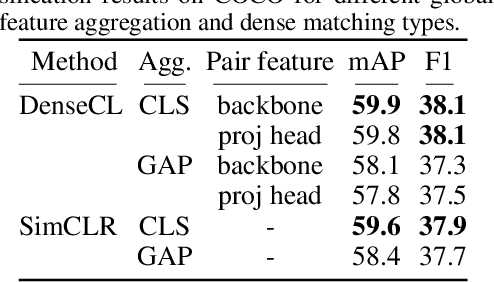
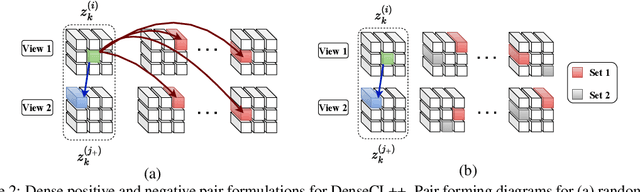
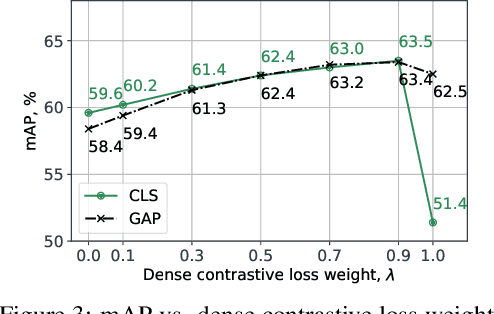
Many contrastive representation learning methods learn a single global representation of an entire image. However, dense contrastive representation learning methods such as DenseCL [19] can learn better representations for tasks requiring stronger spatial localization of features, such as multi-label classification, detection, and segmentation. In this work, we study how to improve the quality of the representations learned by DenseCL by modifying the training scheme and objective function, and propose DenseCL++. We also conduct several ablation studies to better understand the effects of: (i) various techniques to form dense negative pairs among augmentations of different images, (ii) cross-view dense negative and positive pairs, and (iii) an auxiliary reconstruction task. Our results show 3.5% and 4% mAP improvement over SimCLR [3] and DenseCL in COCO multi-label classification. In COCO and VOC segmentation tasks, we achieve 1.8% and 0.7% mIoU improvements over SimCLR, respectively.
Compositional Generalization in Unsupervised Compositional Representation Learning: A Study on Disentanglement and Emergent Language
Oct 05, 2022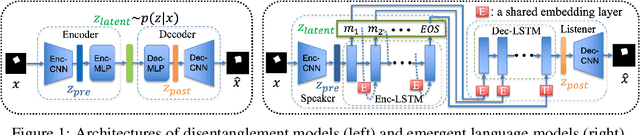

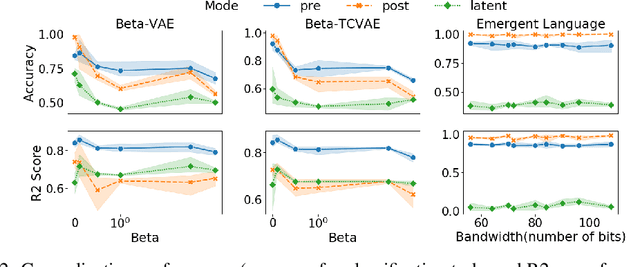

Deep learning models struggle with compositional generalization, i.e. the ability to recognize or generate novel combinations of observed elementary concepts. In hopes of enabling compositional generalization, various unsupervised learning algorithms have been proposed with inductive biases that aim to induce compositional structure in learned representations (e.g. disentangled representation and emergent language learning). In this work, we evaluate these unsupervised learning algorithms in terms of how well they enable compositional generalization. Specifically, our evaluation protocol focuses on whether or not it is easy to train a simple model on top of the learned representation that generalizes to new combinations of compositional factors. We systematically study three unsupervised representation learning algorithms - $\beta$-VAE, $\beta$-TCVAE, and emergent language (EL) autoencoders - on two datasets that allow directly testing compositional generalization. We find that directly using the bottleneck representation with simple models and few labels may lead to worse generalization than using representations from layers before or after the learned representation itself. In addition, we find that the previously proposed metrics for evaluating the levels of compositionality are not correlated with actual compositional generalization in our framework. Surprisingly, we find that increasing pressure to produce a disentangled representation produces representations with worse generalization, while representations from EL models show strong compositional generalization. Taken together, our results shed new light on the compositional generalization behavior of different unsupervised learning algorithms with a new setting to rigorously test this behavior, and suggest the potential benefits of delevoping EL learning algorithms for more generalizable representations.
A Deep Network for Joint Registration and Reconstruction of Images with Pathologies
Aug 17, 2020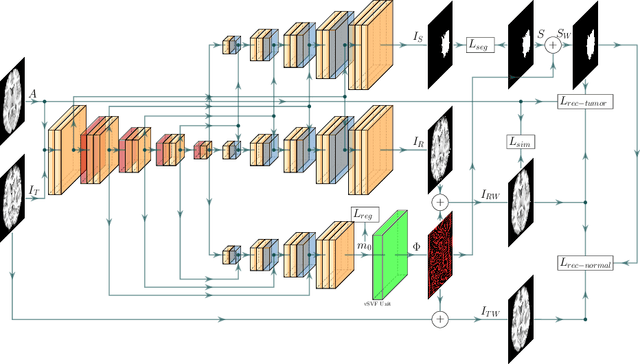
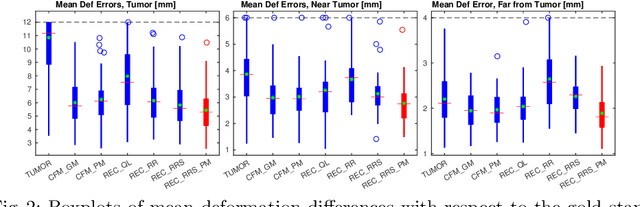
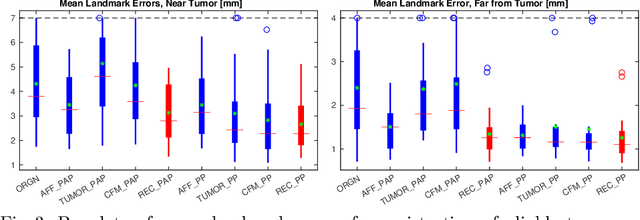
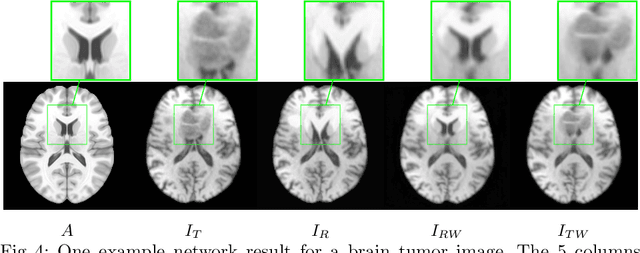
Registration of images with pathologies is challenging due to tissue appearance changes and missing correspondences caused by the pathologies. Moreover, mass effects as observed for brain tumors may displace tissue, creating larger deformations over time than what is observed in a healthy brain. Deep learning models have successfully been applied to image registration to offer dramatic speed up and to use surrogate information (e.g., segmentations) during training. However, existing approaches focus on learning registration models using images from healthy patients. They are therefore not designed for the registration of images with strong pathologies for example in the context of brain tumors, and traumatic brain injuries. In this work, we explore a deep learning approach to register images with brain tumors to an atlas. Our model learns an appearance mapping from images with tumors to the atlas, while simultaneously predicting the transformation to atlas space. Using separate decoders, the network disentangles the tumor mass effect from the reconstruction of quasi-normal images. Results on both synthetic and real brain tumor scans show that our approach outperforms cost function masking for registration to the atlas and that reconstructed quasi-normal images can be used for better longitudinal registrations.
Robust and Generalizable Visual Representation Learning via Random Convolutions
Jul 25, 2020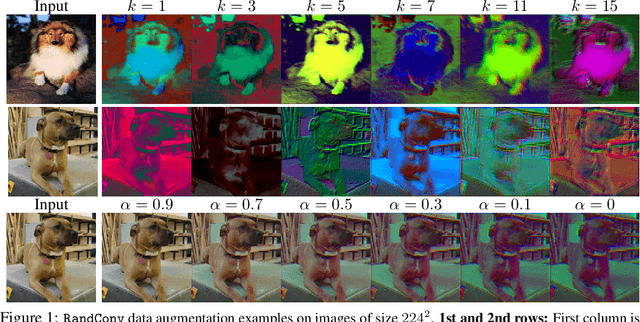
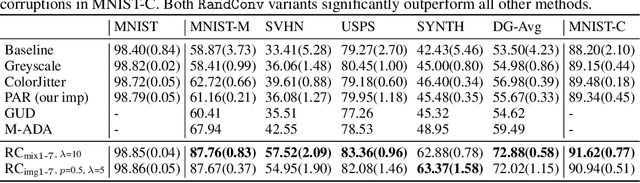
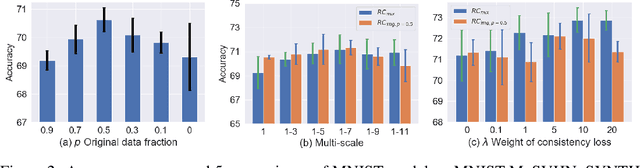
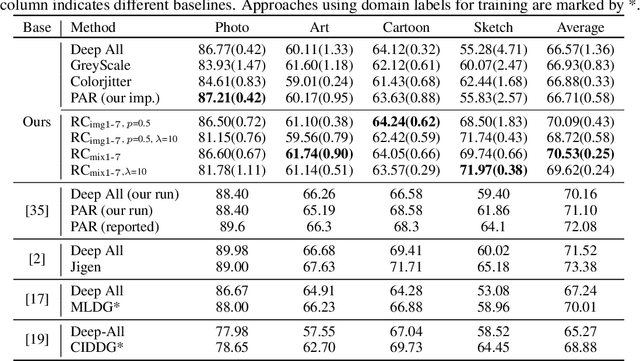
While successful for various computer vision tasks, deep neural networks have shown to be vulnerable to texture style shifts and small perturbations to which humans are robust. Hence, our goal is to train models in such a way that improves their robustness to these perturbations. We are motivated by the approximately shape-preserving property of randomized convolutions, which is due to distance preservation under random linear transforms. Intuitively, randomized convolutions create an infinite number of new domains with similar object shapes but random local texture. Therefore, we explore using outputs of multi-scale random convolutions as new images or mixing them with the original images during training. When applying a network trained with our approach to unseen domains, our method consistently improves the performance on domain generalization benchmarks and is scalable to ImageNet. Especially for the challenging scenario of generalizing to the sketch domain in PACS and to ImageNet-Sketch, our method outperforms state-of-art methods by a large margin. More interestingly, our method can benefit downstream tasks by providing a more robust pretrained visual representation.