 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


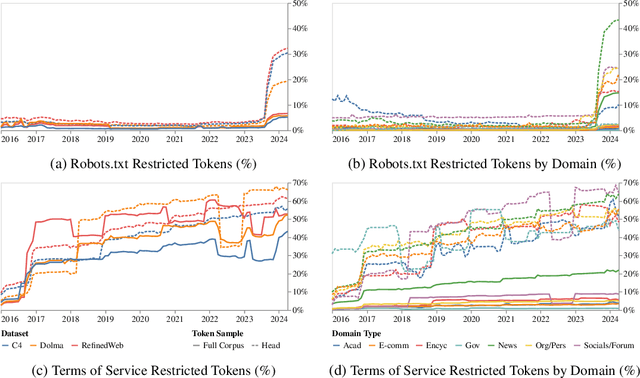
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers
Jan 21, 2024We present the Hourglass Diffusion Transformer (HDiT), an image generative model that exhibits linear scaling with pixel count, supporting training at high-resolution (e.g. $1024 \times 1024$) directly in pixel-space. Building on the Transformer architecture, which is known to scale to billions of parameters, it bridges the gap between the efficiency of convolutional U-Nets and the scalability of Transformers. HDiT trains successfully without typical high-resolution training techniques such as multiscale architectures, latent autoencoders or self-conditioning. We demonstrate that HDiT performs competitively with existing models on ImageNet $256^2$, and sets a new state-of-the-art for diffusion models on FFHQ-$1024^2$.
The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI
Nov 04, 2023



The race to train language models on vast, diverse, and inconsistently documented datasets has raised pressing concerns about the legal and ethical risks for practitioners. To remedy these practices threatening data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace 1800+ text datasets. We develop tools and standards to trace the lineage of these datasets, from their source, creators, series of license conditions, properties, and subsequent use. Our landscape analysis highlights the sharp divides in composition and focus of commercially open vs closed datasets, with closed datasets monopolizing important categories: lower resource languages, more creative tasks, richer topic variety, newer and more synthetic training data. This points to a deepening divide in the types of data that are made available under different license conditions, and heightened implications for jurisdictional legal interpretations of copyright and fair use. We also observe frequent miscategorization of licenses on widely used dataset hosting sites, with license omission of 70%+ and error rates of 50%+. This points to a crisis in misattribution and informed use of the most popular datasets driving many recent breakthroughs. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire audit, with an interactive UI, the Data Provenance Explorer, which allows practitioners to trace and filter on data provenance for the most popular open source finetuning data collections: www.dataprovenance.org.
YaRN: Efficient Context Window Extension of Large Language Models
Aug 31, 2023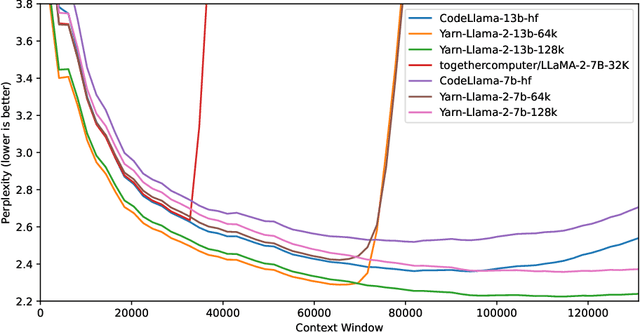


Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. We publish the checkpoints of Llama 2 7B/13B fine-tuned using YaRN with 64k and 128k context windows at https://github.com/jquesnelle/yarn