 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Art-Free Generative Models: Art Creation Without Graphic Art Knowledge
Nov 29, 2024



We explore the question: "How much prior art knowledge is needed to create art?" To investigate this, we propose a text-to-image generation model trained without access to art-related content. We then introduce a simple yet effective method to learn an art adapter using only a few examples of selected artistic styles. Our experiments show that art generated using our method is perceived by users as comparable to art produced by models trained on large, art-rich datasets. Finally, through data attribution techniques, we illustrate how examples from both artistic and non-artistic datasets contributed to the creation of new artistic styles.
AirLetters: An Open Video Dataset of Characters Drawn in the Air
Oct 03, 2024
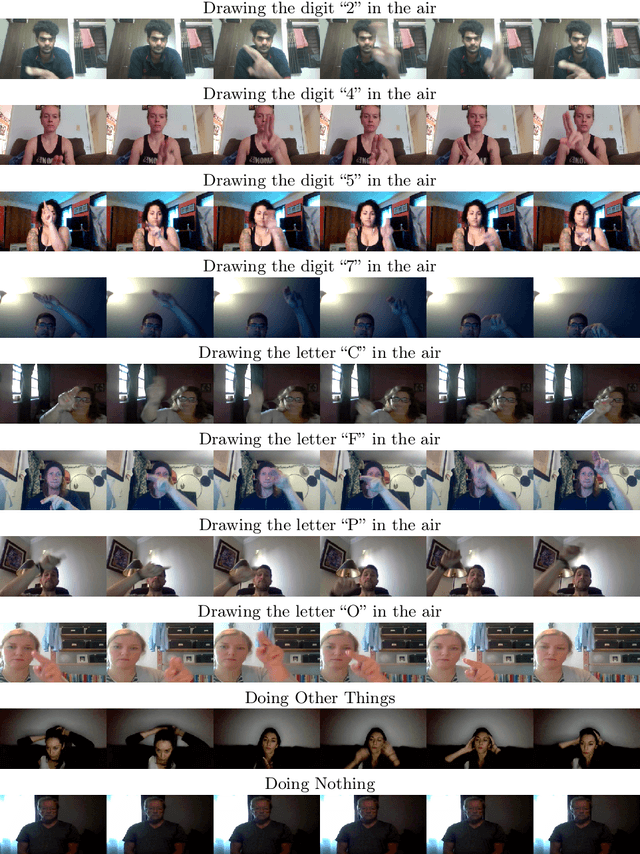


We introduce AirLetters, a new video dataset consisting of real-world videos of human-generated, articulated motions. Specifically, our dataset requires a vision model to predict letters that humans draw in the air. Unlike existing video datasets, accurate classification predictions for AirLetters rely critically on discerning motion patterns and on integrating long-range information in the video over time. An extensive evaluation of state-of-the-art image and video understanding models on AirLetters shows that these methods perform poorly and fall far behind a human baseline. Our work shows that, despite recent progress in end-to-end video understanding, accurate representations of complex articulated motions -- a task that is trivial for humans -- remains an open problem for end-to-end learning.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


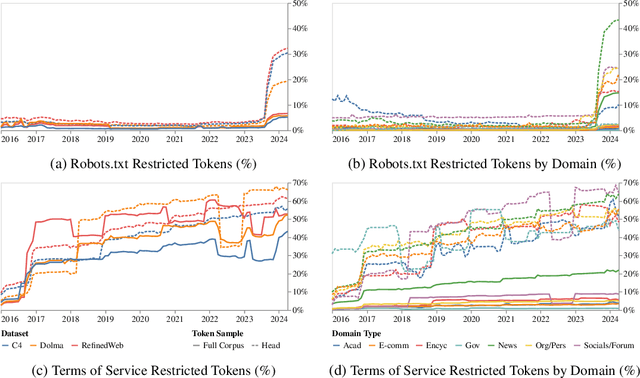
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Customizing Motion in Text-to-Video Diffusion Models
Dec 07, 2023



We introduce an approach for augmenting text-to-video generation models with customized motions, extending their capabilities beyond the motions depicted in the original training data. By leveraging a few video samples demonstrating specific movements as input, our method learns and generalizes the input motion patterns for diverse, text-specified scenarios. Our contributions are threefold. First, to achieve our results, we finetune an existing text-to-video model to learn a novel mapping between the depicted motion in the input examples to a new unique token. To avoid overfitting to the new custom motion, we introduce an approach for regularization over videos. Second, by leveraging the motion priors in a pretrained model, our method can produce novel videos featuring multiple people doing the custom motion, and can invoke the motion in combination with other motions. Furthermore, our approach extends to the multimodal customization of motion and appearance of individualized subjects, enabling the generation of videos featuring unique characters and distinct motions. Third, to validate our method, we introduce an approach for quantitatively evaluating the learned custom motion and perform a systematic ablation study. We show that our method significantly outperforms prior appearance-based customization approaches when extended to the motion customization task.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Nov 27, 2023



We present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. Our approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes. A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments comparing to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference. We showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at https://sliders.baulab.info/
A Function Interpretation Benchmark for Evaluating Interpretability Methods
Sep 07, 2023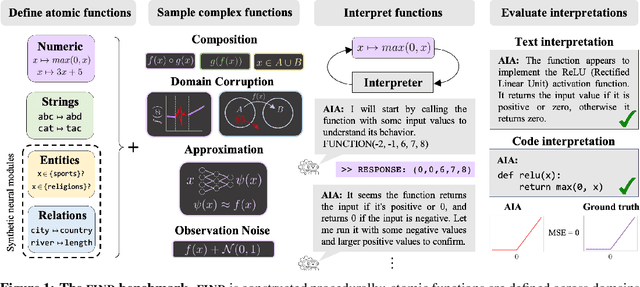



Labeling neural network submodules with human-legible descriptions is useful for many downstream tasks: such descriptions can surface failures, guide interventions, and perhaps even explain important model behaviors. To date, most mechanistic descriptions of trained networks have involved small models, narrowly delimited phenomena, and large amounts of human labor. Labeling all human-interpretable sub-computations in models of increasing size and complexity will almost certainly require tools that can generate and validate descriptions automatically. Recently, techniques that use learned models in-the-loop for labeling have begun to gain traction, but methods for evaluating their efficacy are limited and ad-hoc. How should we validate and compare open-ended labeling tools? This paper introduces FIND (Function INterpretation and Description), a benchmark suite for evaluating the building blocks of automated interpretability methods. FIND contains functions that resemble components of trained neural networks, and accompanying descriptions of the kind we seek to generate. The functions are procedurally constructed across textual and numeric domains, and involve a range of real-world complexities, including noise, composition, approximation, and bias. We evaluate new and existing methods that use language models (LMs) to produce code-based and language descriptions of function behavior. We find that an off-the-shelf LM augmented with only black-box access to functions can sometimes infer their structure, acting as a scientist by forming hypotheses, proposing experiments, and updating descriptions in light of new data. However, LM-based descriptions tend to capture global function behavior and miss local corruptions. These results show that FIND will be useful for characterizing the performance of more sophisticated interpretability methods before they are applied to real-world models.
Erasing Concepts from Diffusion Models
Mar 16, 2023



Motivated by recent advancements in text-to-image diffusion, we study erasure of specific concepts from the model's weights. While Stable Diffusion has shown promise in producing explicit or realistic artwork, it has raised concerns regarding its potential for misuse. We propose a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. We benchmark our method against previous approaches that remove sexually explicit content and demonstrate its effectiveness, performing on par with Safe Latent Diffusion and censored training. To evaluate artistic style removal, we conduct experiments erasing five modern artists from the network and conduct a user study to assess the human perception of the removed styles. Unlike previous methods, our approach can remove concepts from a diffusion model permanently rather than modifying the output at the inference time, so it cannot be circumvented even if a user has access to model weights. Our code, data, and results are available at https://erasing.baulab.info/
Disentangling visual and written concepts in CLIP
Jun 15, 2022



The CLIP network measures the similarity between natural text and images; in this work, we investigate the entanglement of the representation of word images and natural images in its image encoder. First, we find that the image encoder has an ability to match word images with natural images of scenes described by those words. This is consistent with previous research that suggests that the meaning and the spelling of a word might be entangled deep within the network. On the other hand, we also find that CLIP has a strong ability to match nonsense words, suggesting that processing of letters is separated from processing of their meaning. To explicitly determine whether the spelling capability of CLIP is separable, we devise a procedure for identifying representation subspaces that selectively isolate or eliminate spelling capabilities. We benchmark our methods against a range of retrieval tasks, and we also test them by measuring the appearance of text in CLIP-guided generated images. We find that our methods are able to cleanly separate spelling capabilities of CLIP from the visual processing of natural images.
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
Dec 20, 2019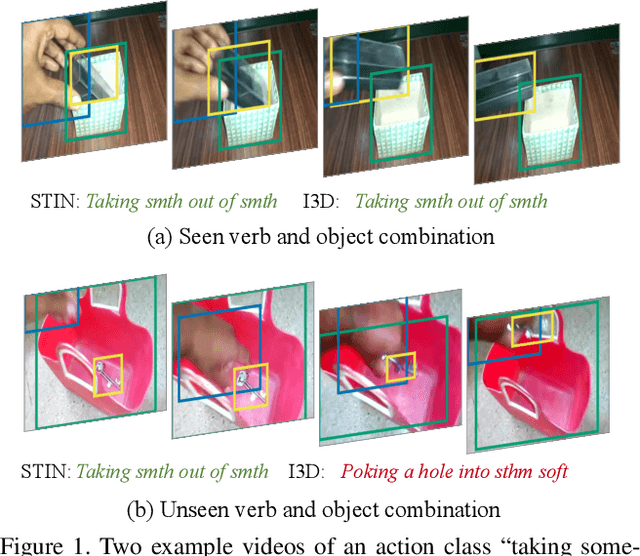
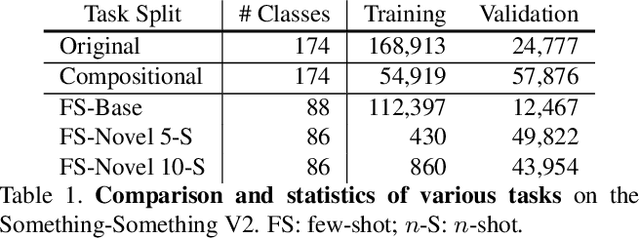
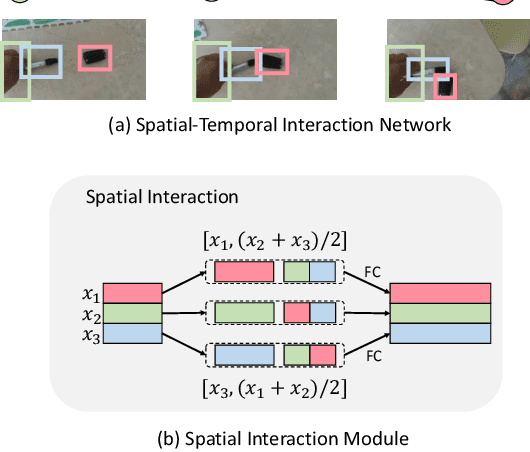
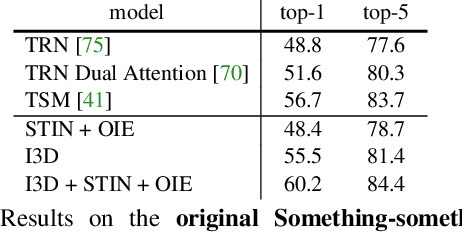
Human action is naturally compositional: humans can easily recognize and perform actions with objects that are different from those used in training demonstrations. In this paper, we study the compositionality of action by looking into the dynamics of subject-object interactions. We propose a novel model which can explicitly reason about the geometric relations between constituent objects and an agent performing an action. To train our model, we collect dense object box annotations on the Something-Something dataset. We propose a novel compositional action recognition task where the training combinations of verbs and nouns do not overlap with the test set. The novel aspects of our model are applicable to activities with prominent object interaction dynamics and to objects which can be tracked using state-of-the-art approaches; for activities without clearly defined spatial object-agent interactions, we rely on baseline scene-level spatio-temporal representations. We show the effectiveness of our approach not only on the proposed compositional action recognition task, but also in a few-shot compositional setting which requires the model to generalize across both object appearance and action category.