 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything
Apr 05, 2023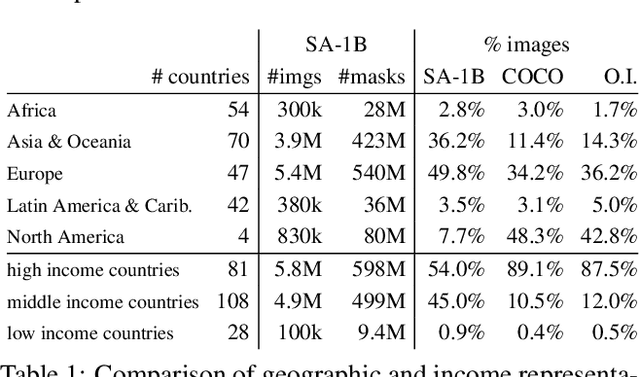

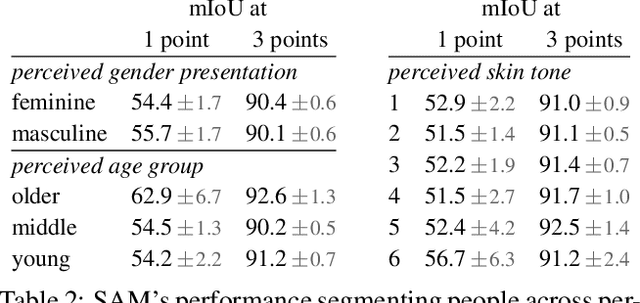

We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
Learning Humanoid Locomotion with Transformers
Mar 06, 2023We present a sim-to-real learning-based approach for real-world humanoid locomotion. Our controller is a causal Transformer trained by autoregressive prediction of future actions from the history of observations and actions. We hypothesize that the observation-action history contains useful information about the world that a powerful Transformer model can use to adapt its behavior in-context, without updating its weights. We do not use state estimation, dynamics models, trajectory optimization, reference trajectories, or pre-computed gait libraries. Our controller is trained with large-scale model-free reinforcement learning on an ensemble of randomized environments in simulation and deployed to the real world in a zero-shot fashion. We evaluate our approach in high-fidelity simulation and successfully deploy it to the real robot as well. To the best of our knowledge, this is the first demonstration of a fully learning-based method for real-world full-sized humanoid locomotion.
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

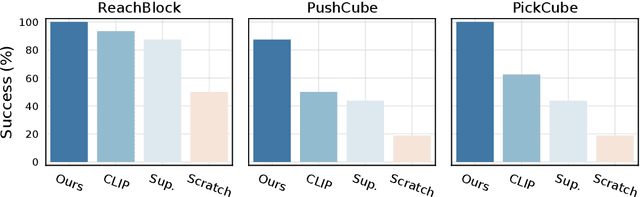
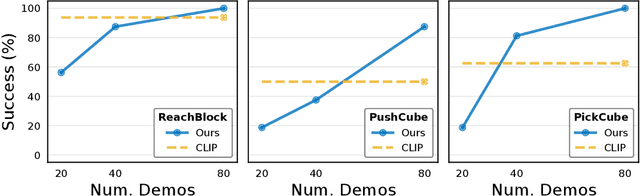
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.
Masked Visual Pre-training for Motor Control
Mar 11, 2022
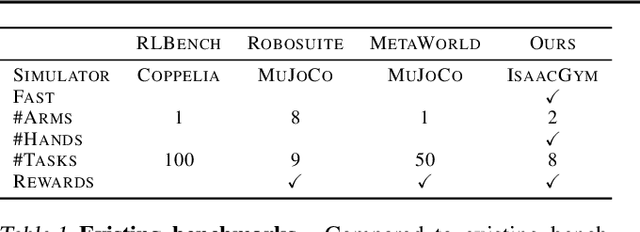
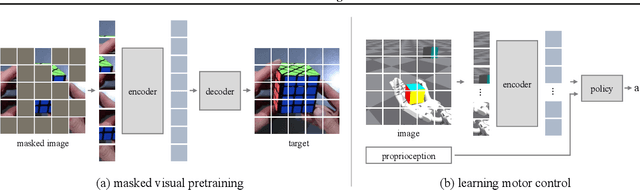

This paper shows that self-supervised visual pre-training from real-world images is effective for learning motor control tasks from pixels. We first train the visual representations by masked modeling of natural images. We then freeze the visual encoder and train neural network controllers on top with reinforcement learning. We do not perform any task-specific fine-tuning of the encoder; the same visual representations are used for all motor control tasks. To the best of our knowledge, this is the first self-supervised model to exploit real-world images at scale for motor control. To accelerate progress in learning from pixels, we contribute a benchmark suite of hand-designed tasks varying in movements, scenes, and robots. Without relying on labels, state-estimation, or expert demonstrations, we consistently outperform supervised encoders by up to 80% absolute success rate, sometimes even matching the oracle state performance. We also find that in-the-wild images, e.g., from YouTube or Egocentric videos, lead to better visual representations for various manipulation tasks than ImageNet images.
Early Convolutions Help Transformers See Better
Jul 12, 2021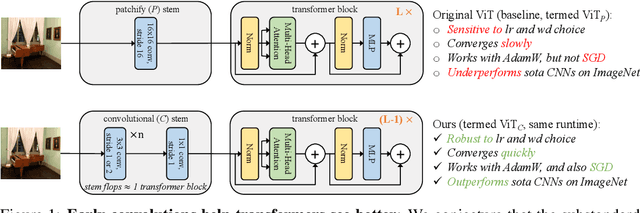

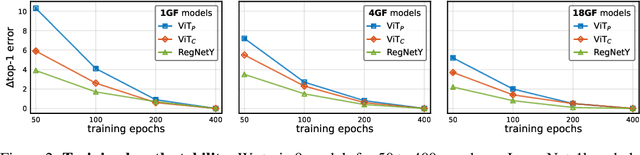
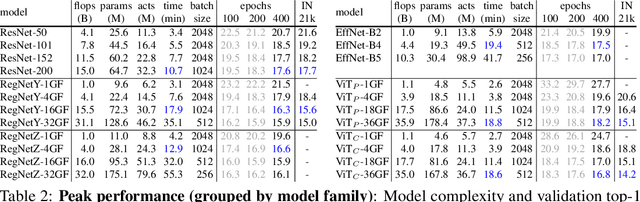
Vision transformer (ViT) models exhibit substandard optimizability. In particular, they are sensitive to the choice of optimizer (AdamW vs. SGD), optimizer hyperparameters, and training schedule length. In comparison, modern convolutional neural networks are far easier to optimize. Why is this the case? In this work, we conjecture that the issue lies with the patchify stem of ViT models, which is implemented by a stride-p pxp convolution (p=16 by default) applied to the input image. This large-kernel plus large-stride convolution runs counter to typical design choices of convolutional layers in neural networks. To test whether this atypical design choice causes an issue, we analyze the optimization behavior of ViT models with their original patchify stem versus a simple counterpart where we replace the ViT stem by a small number of stacked stride-two 3x3 convolutions. While the vast majority of computation in the two ViT designs is identical, we find that this small change in early visual processing results in markedly different training behavior in terms of the sensitivity to optimization settings as well as the final model accuracy. Using a convolutional stem in ViT dramatically increases optimization stability and also improves peak performance (by ~1-2% top-1 accuracy on ImageNet-1k), while maintaining flops and runtime. The improvement can be observed across the wide spectrum of model complexities (from 1G to 36G flops) and dataset scales (from ImageNet-1k to ImageNet-21k). These findings lead us to recommend using a standard, lightweight convolutional stem for ViT models as a more robust architectural choice compared to the original ViT model design.
Region Similarity Representation Learning
Mar 24, 2021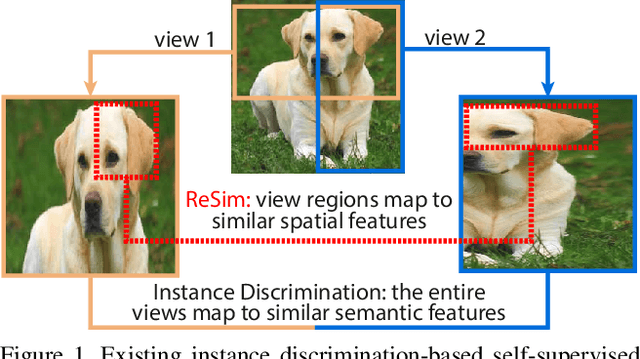
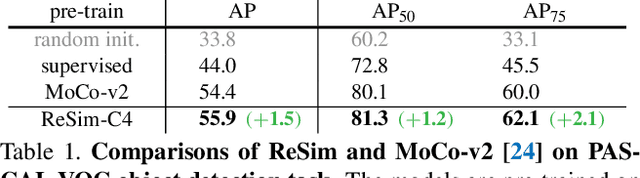
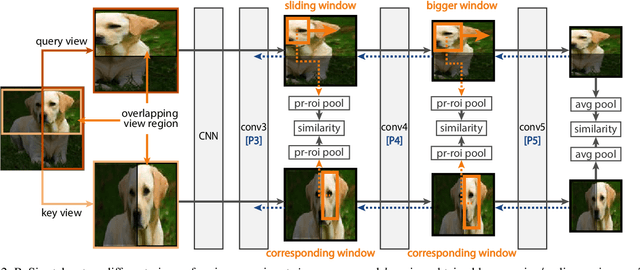
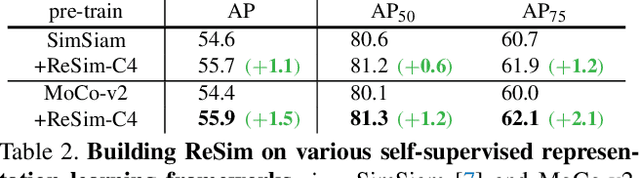
We present Region Similarity Representation Learning (ReSim), a new approach to self-supervised representation learning for localization-based tasks such as object detection and segmentation. While existing work has largely focused on solely learning global representations for an entire image, ReSim learns both regional representations for localization as well as semantic image-level representations. ReSim operates by sliding a fixed-sized window across the overlapping area between two views (e.g., image crops), aligning these areas with their corresponding convolutional feature map regions, and then maximizing the feature similarity across views. As a result, ReSim learns spatially and semantically consistent feature representation throughout the convolutional feature maps of a neural network. A shift or scale of an image region, e.g., a shift or scale of an object, has a corresponding change in the feature maps; this allows downstream tasks to leverage these representations for localization. Through object detection, instance segmentation, and dense pose estimation experiments, we illustrate how ReSim learns representations which significantly improve the localization and classification performance compared to a competitive MoCo-v2 baseline: $+2.7$ AP$^{\text{bb}}_{75}$ VOC, $+1.1$ AP$^{\text{bb}}_{75}$ COCO, and $+1.9$ AP$^{\text{mk}}$ Cityscapes. Code and pre-trained models are released at: \url{https://github.com/Tete-Xiao/ReSim}
Learning Cross-Domain Correspondence for Control with Dynamics Cycle-Consistency
Dec 17, 2020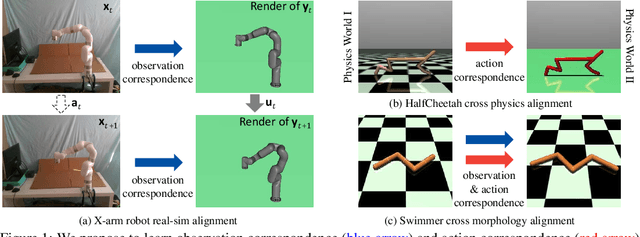
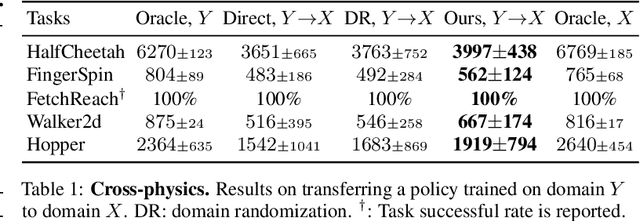
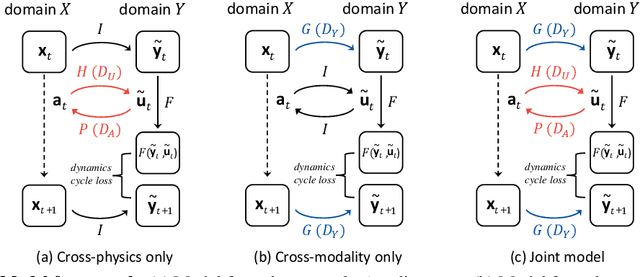

At the heart of many robotics problems is the challenge of learning correspondences across domains. For instance, imitation learning requires obtaining correspondence between humans and robots; sim-to-real requires correspondence between physics simulators and the real world; transfer learning requires correspondences between different robotics environments. This paper aims to learn correspondence across domains differing in representation (vision vs. internal state), physics parameters (mass and friction), and morphology (number of limbs). Importantly, correspondences are learned using unpaired and randomly collected data from the two domains. We propose \textit{dynamics cycles} that align dynamic robot behavior across two domains using a cycle-consistency constraint. Once this correspondence is found, we can directly transfer the policy trained on one domain to the other, without needing any additional fine-tuning on the second domain. We perform experiments across a variety of problem domains, both in simulation and on real robot. Our framework is able to align uncalibrated monocular video of a real robot arm to dynamic state-action trajectories of a simulated arm without paired data. Video demonstrations of our results are available at: https://sjtuzq.github.io/cycle_dynamics.html .
What Should Not Be Contrastive in Contrastive Learning
Aug 13, 2020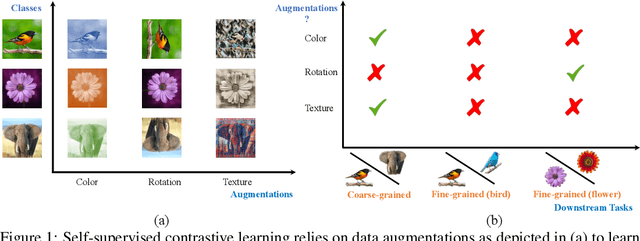
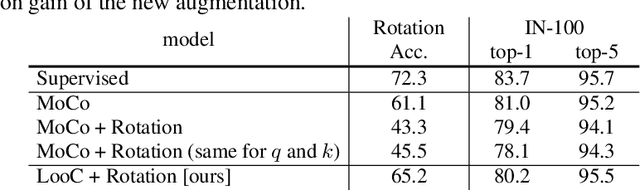
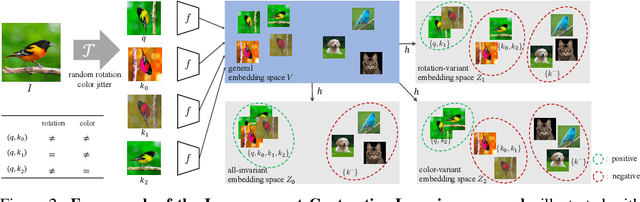
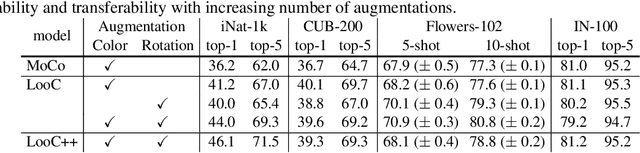
Recent self-supervised contrastive methods have been able to produce impressive transferable visual representations by learning to be invariant to different data augmentations. However, these methods implicitly assume a particular set of representational invariances (e.g., invariance to color), and can perform poorly when a downstream task violates this assumption (e.g., distinguishing red vs. yellow cars). We introduce a contrastive learning framework which does not require prior knowledge of specific, task-dependent invariances. Our model learns to capture varying and invariant factors for visual representations by constructing separate embedding spaces, each of which is invariant to all but one augmentation. We use a multi-head network with a shared backbone which captures information across each augmentation and alone outperforms all baselines on downstream tasks. We further find that the concatenation of the invariant and varying spaces performs best across all tasks we investigate, including coarse-grained, fine-grained, and few-shot downstream classification tasks, and various data corruptions.
Reducing Class Collapse in Metric Learning with Easy Positive Sampling
Jun 09, 2020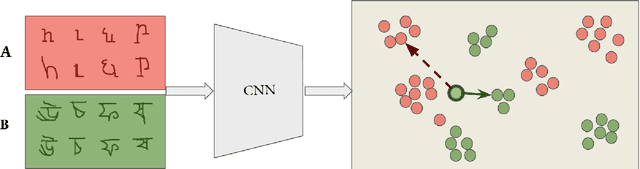

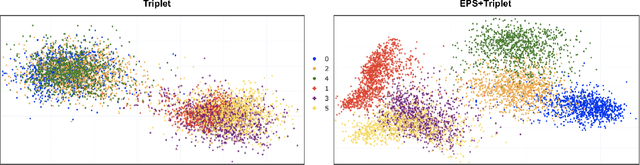
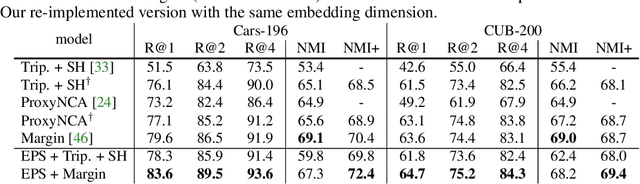
Metric learning seeks perceptual embeddings where visually similar instances are close and dissimilar instances are apart, but learn representation can be sub-optimal when the distribution of intra-class samples is diverse and distinct sub-clusters are present. We theoretically prove and empirically show that under reasonable noise assumptions, prevalent embedding losses in metric learning, e.g., triplet loss, tend to project all samples of a class with various modes onto a single point in the embedding space, resulting in class collapse that usually renders the space ill-sorted for classification or retrieval. To address this problem, we propose a simple modification to the embedding losses such that each sample selects its nearest same-class counterpart in a batch as the positive element in the tuple. This allows for the presence of multiple sub-clusters within each class. The adaptation can be integrated into a wide range of metric learning losses. Our method demonstrates clear benefits on various fine-grained image retrieval datasets over a variety of existing losses; qualitative retrieval results show that samples with similar visual patterns are indeed closer in the embedding space.
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
Dec 20, 2019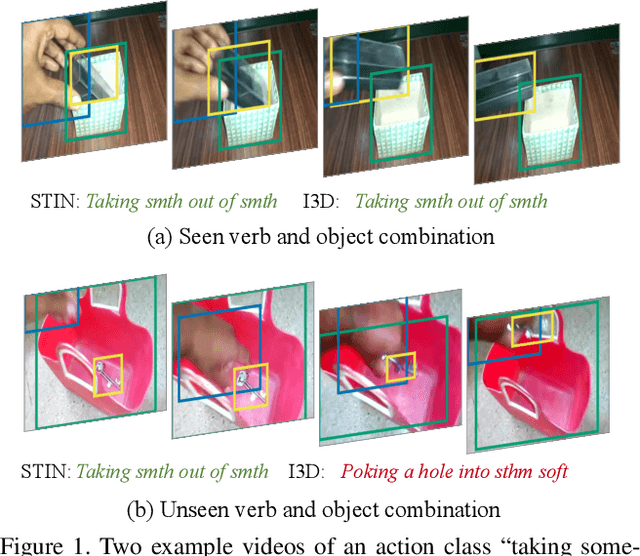
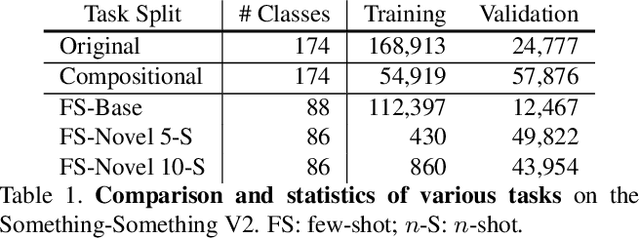
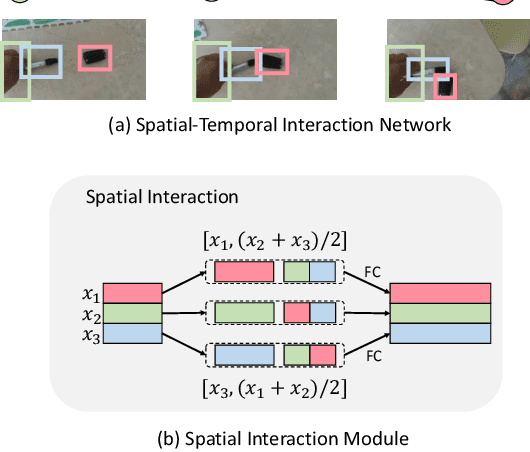
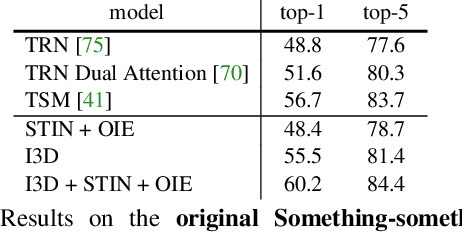
Human action is naturally compositional: humans can easily recognize and perform actions with objects that are different from those used in training demonstrations. In this paper, we study the compositionality of action by looking into the dynamics of subject-object interactions. We propose a novel model which can explicitly reason about the geometric relations between constituent objects and an agent performing an action. To train our model, we collect dense object box annotations on the Something-Something dataset. We propose a novel compositional action recognition task where the training combinations of verbs and nouns do not overlap with the test set. The novel aspects of our model are applicable to activities with prominent object interaction dynamics and to objects which can be tracked using state-of-the-art approaches; for activities without clearly defined spatial object-agent interactions, we rely on baseline scene-level spatio-temporal representations. We show the effectiveness of our approach not only on the proposed compositional action recognition task, but also in a few-shot compositional setting which requires the model to generalize across both object appearance and action category.