 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Control for Text-to-Image Generation via Learning Viewpoint Tokens
Apr 21, 2026Current text-to-image models struggle to provide precise camera control using natural language alone. In this work, we present a framework for precise camera control with global scene understanding in text-to-image generation by learning parametric camera tokens. We fine-tune image generation models for viewpoint-conditioned text-to-image generation on a curated dataset that combines 3D-rendered images for geometric supervision and photorealistic augmentations for appearance and background diversity. Qualitative and quantitative experiments demonstrate that our method achieves state-of-the-art accuracy while preserving image quality and prompt fidelity. Unlike prior methods that overfit to object-specific appearance correlations, our viewpoint tokens learn factorized geometric representations that transfer to unseen object categories. Our work shows that text-vision latent spaces can be endowed with explicit 3D camera structure, offering a pathway toward geometrically-aware prompts for text-to-image generation. Project page: https://randdl.github.io/viewtoken_control/
Learning from Models and Data for Visual Grounding
Mar 20, 2024



We introduce SynGround, a novel framework that combines data-driven learning and knowledge transfer from various large-scale pretrained models to enhance the visual grounding capabilities of a pretrained vision-and-language model. The knowledge transfer from the models initiates the generation of image descriptions through an image description generator. These descriptions serve dual purposes: they act as prompts for synthesizing images through a text-to-image generator, and as queries for synthesizing text, from which phrases are extracted using a large language model. Finally, we leverage an open-vocabulary object detector to generate synthetic bounding boxes for the synthetic images and texts. We finetune a pretrained vision-and-language model on this dataset by optimizing a mask-attention consistency objective that aligns region annotations with gradient-based model explanations. The resulting model improves the grounding capabilities of an off-the-shelf vision-and-language model. Particularly, SynGround improves the pointing game accuracy of ALBEF on the Flickr30k dataset from 79.38% to 87.26%, and on RefCOCO+ Test A from 69.35% to 79.06% and on RefCOCO+ Test B from 53.77% to 63.67%.
Improved Visual Grounding through Self-Consistent Explanations
Dec 07, 2023Vision-and-language models trained to match images with text can be combined with visual explanation methods to point to the locations of specific objects in an image. Our work shows that the localization --"grounding"-- abilities of these models can be further improved by finetuning for self-consistent visual explanations. We propose a strategy for augmenting existing text-image datasets with paraphrases using a large language model, and SelfEQ, a weakly-supervised strategy on visual explanation maps for paraphrases that encourages self-consistency. Specifically, for an input textual phrase, we attempt to generate a paraphrase and finetune the model so that the phrase and paraphrase map to the same region in the image. We posit that this both expands the vocabulary that the model is able to handle, and improves the quality of the object locations highlighted by gradient-based visual explanation methods (e.g. GradCAM). We demonstrate that SelfEQ improves performance on Flickr30k, ReferIt, and RefCOCO+ over a strong baseline method and several prior works. Particularly, comparing to other methods that do not use any type of box annotations, we obtain 84.07% on Flickr30k (an absolute improvement of 4.69%), 67.40% on ReferIt (an absolute improvement of 7.68%), and 75.10%, 55.49% on RefCOCO+ test sets A and B respectively (an absolute improvement of 3.74% on average).
Joint Depth Prediction and Semantic Segmentation with Multi-View SAM
Oct 31, 2023



Multi-task approaches to joint depth and segmentation prediction are well-studied for monocular images. Yet, predictions from a single-view are inherently limited, while multiple views are available in many robotics applications. On the other end of the spectrum, video-based and full 3D methods require numerous frames to perform reconstruction and segmentation. With this work we propose a Multi-View Stereo (MVS) technique for depth prediction that benefits from rich semantic features of the Segment Anything Model (SAM). This enhanced depth prediction, in turn, serves as a prompt to our Transformer-based semantic segmentation decoder. We report the mutual benefit that both tasks enjoy in our quantitative and qualitative studies on the ScanNet dataset. Our approach consistently outperforms single-task MVS and segmentation models, along with multi-task monocular methods.
Segment Anything
Apr 05, 2023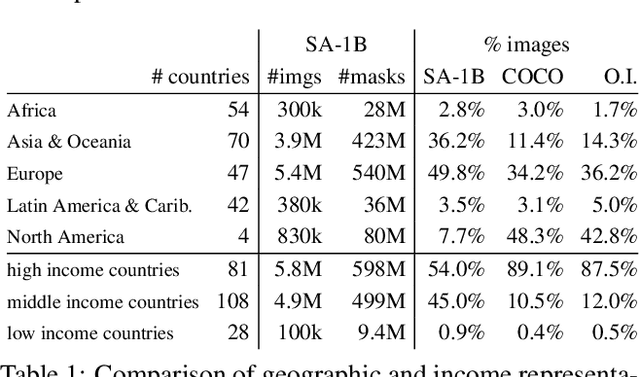

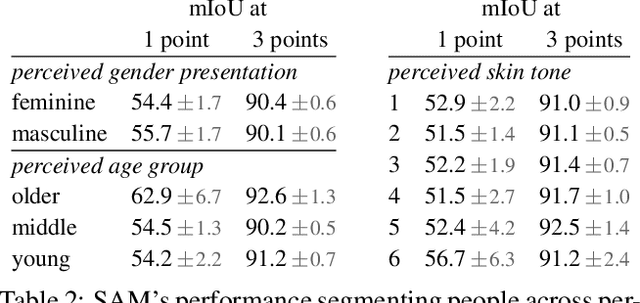

We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
Point-Level Region Contrast for Object Detection Pre-Training
Feb 09, 2022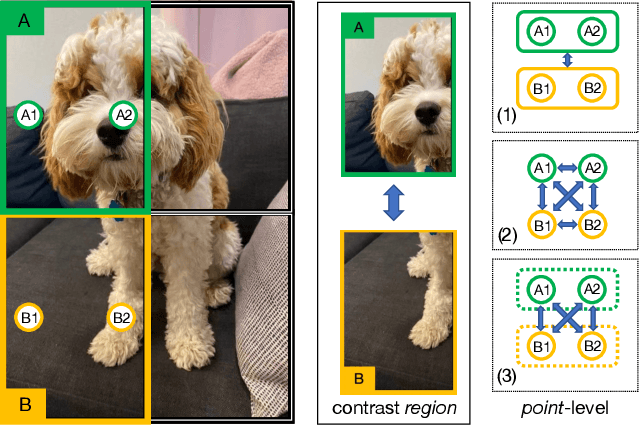
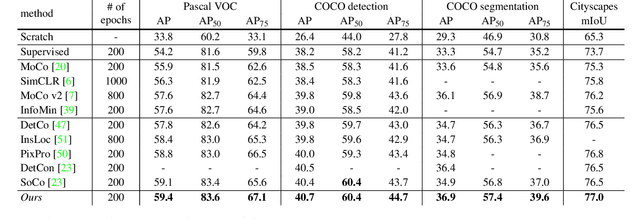
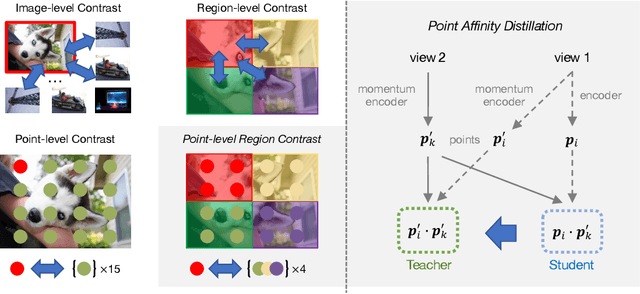

In this work we present point-level region contrast, a self-supervised pre-training approach for the task of object detection. This approach is motivated by the two key factors in detection: localization and recognition. While accurate localization favors models that operate at the pixel- or point-level, correct recognition typically relies on a more holistic, region-level view of objects. Incorporating this perspective in pre-training, our approach performs contrastive learning by directly sampling individual point pairs from different regions. Compared to an aggregated representation per region, our approach is more robust to the change in input region quality, and further enables us to implicitly improve initial region assignments via online knowledge distillation during training. Both advantages are important when dealing with imperfect regions encountered in the unsupervised setting. Experiments show point-level region contrast improves on state-of-the-art pre-training methods for object detection and segmentation across multiple tasks and datasets, and we provide extensive ablation studies and visualizations to aid understanding. Code will be made available.
Neural Pseudo-Label Optimism for the Bank Loan Problem
Dec 03, 2021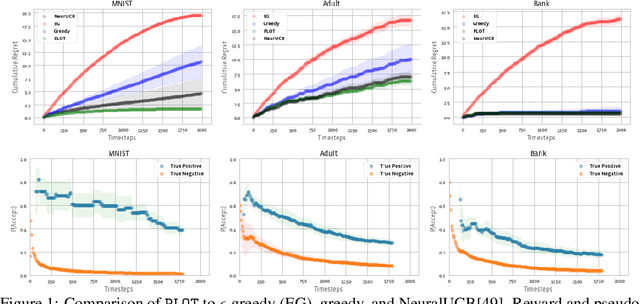
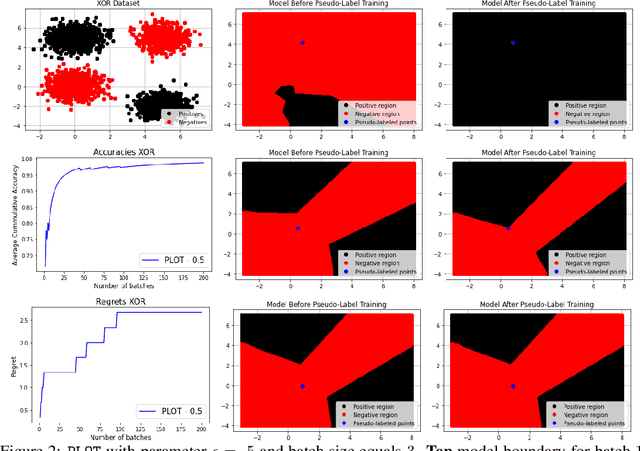
We study a class of classification problems best exemplified by the \emph{bank loan} problem, where a lender decides whether or not to issue a loan. The lender only observes whether a customer will repay a loan if the loan is issued to begin with, and thus modeled decisions affect what data is available to the lender for future decisions. As a result, it is possible for the lender's algorithm to ``get stuck'' with a self-fulfilling model. This model never corrects its false negatives, since it never sees the true label for rejected data, thus accumulating infinite regret. In the case of linear models, this issue can be addressed by adding optimism directly into the model predictions. However, there are few methods that extend to the function approximation case using Deep Neural Networks. We present Pseudo-Label Optimism (PLOT), a conceptually and computationally simple method for this setting applicable to DNNs. \PLOT{} adds an optimistic label to the subset of decision points the current model is deciding on, trains the model on all data so far (including these points along with their optimistic labels), and finally uses the resulting \emph{optimistic} model for decision making. \PLOT{} achieves competitive performance on a set of three challenging benchmark problems, requiring minimal hyperparameter tuning. We also show that \PLOT{} satisfies a logarithmic regret guarantee, under a Lipschitz and logistic mean label model, and under a separability condition on the data.
Boundary IoU: Improving Object-Centric Image Segmentation Evaluation
Mar 30, 2021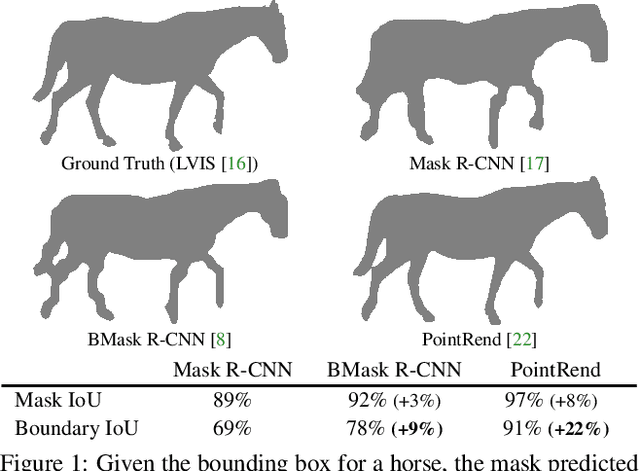
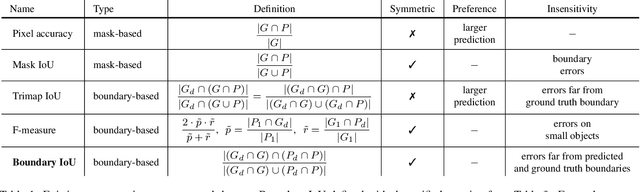

We present Boundary IoU (Intersection-over-Union), a new segmentation evaluation measure focused on boundary quality. We perform an extensive analysis across different error types and object sizes and show that Boundary IoU is significantly more sensitive than the standard Mask IoU measure to boundary errors for large objects and does not over-penalize errors on smaller objects. The new quality measure displays several desirable characteristics like symmetry w.r.t. prediction/ground truth pairs and balanced responsiveness across scales, which makes it more suitable for segmentation evaluation than other boundary-focused measures like Trimap IoU and F-measure. Based on Boundary IoU, we update the standard evaluation protocols for instance and panoptic segmentation tasks by proposing the Boundary AP (Average Precision) and Boundary PQ (Panoptic Quality) metrics, respectively. Our experiments show that the new evaluation metrics track boundary quality improvements that are generally overlooked by current Mask IoU-based evaluation metrics. We hope that the adoption of the new boundary-sensitive evaluation metrics will lead to rapid progress in segmentation methods that improve boundary quality.
Similarity Search for Efficient Active Learning and Search of Rare Concepts
Jun 30, 2020
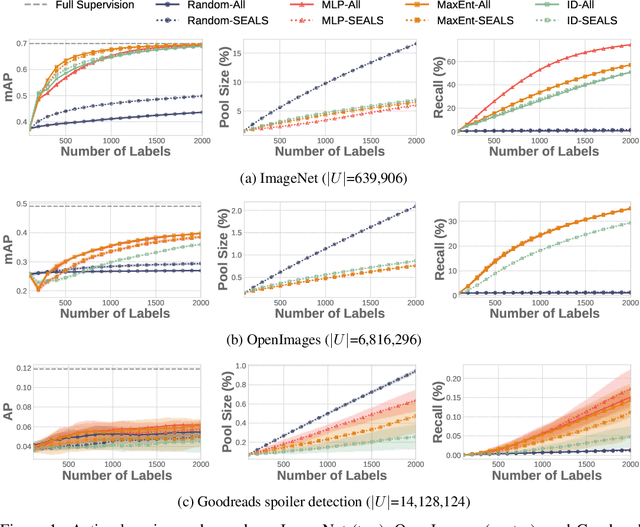

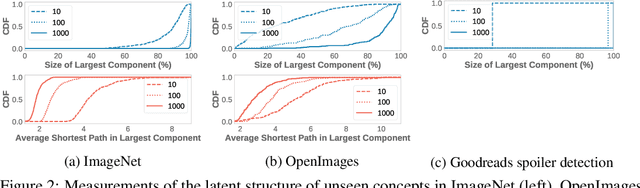
Many active learning and search approaches are intractable for industrial settings with billions of unlabeled examples. Existing approaches, such as uncertainty sampling or information density, search globally for the optimal examples to label, scaling linearly or even quadratically with the unlabeled data. However, in practice, data is often heavily skewed; only a small fraction of collected data will be relevant for a given learning task. For example, when identifying rare classes, detecting malicious content, or debugging model performance, the ratio of positive to negative examples can be 1 to 1,000 or more. In this work, we exploit this skew in large training datasets to reduce the number of unlabeled examples considered in each selection round by only looking at the nearest neighbors to the labeled examples. Empirically, we observe that learned representations effectively cluster unseen concepts, making active learning very effective and substantially reducing the number of viable unlabeled examples. We evaluate several active learning and search techniques in this setting on three large-scale datasets: ImageNet, Goodreads spoiler detection, and OpenImages. For rare classes, active learning methods need as little as 0.31% of the labeled data to match the average precision of full supervision. By limiting active learning methods to only consider the immediate neighbors of the labeled data as candidates for labeling, we need only process as little as 1% of the unlabeled data while achieving similar reductions in labeling costs as the traditional global approach. This process of expanding the candidate pool with the nearest neighbors of the labeled set can be done efficiently and reduces the computational complexity of selection by orders of magnitude.
A Mask-RCNN Baseline for Probabilistic Object Detection
Aug 09, 2019


The Probabilistic Object Detection Challenge evaluates object detection methods using a new evaluation measure, Probability-based Detection Quality (PDQ), on a new synthetic image dataset. We present our submission to the challenge, a fine-tuned version of Mask-RCNN with some additional post-processing. Our method, submitted under username pammirato, is currently second on the leaderboard with a score of 21.432, while also achieving the highest spatial quality and average overall quality of detections. We hope this method can provide some insight into how detectors designed for mean average precision (mAP) evaluation behave under PDQ, as well as a strong baseline for future work.