 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mask-RCNN Baseline for Probabilistic Object Detection
Aug 09, 2019


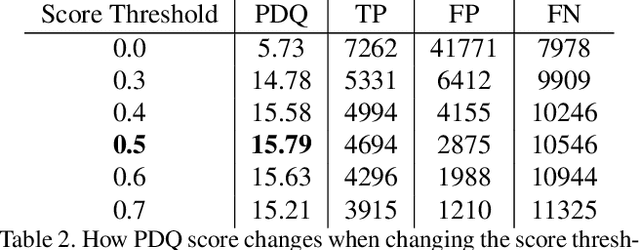
The Probabilistic Object Detection Challenge evaluates object detection methods using a new evaluation measure, Probability-based Detection Quality (PDQ), on a new synthetic image dataset. We present our submission to the challenge, a fine-tuned version of Mask-RCNN with some additional post-processing. Our method, submitted under username pammirato, is currently second on the leaderboard with a score of 21.432, while also achieving the highest spatial quality and average overall quality of detections. We hope this method can provide some insight into how detectors designed for mean average precision (mAP) evaluation behave under PDQ, as well as a strong baseline for future work.
Target Driven Instance Detection
Jul 17, 2018
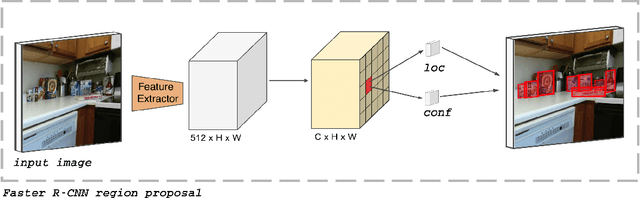
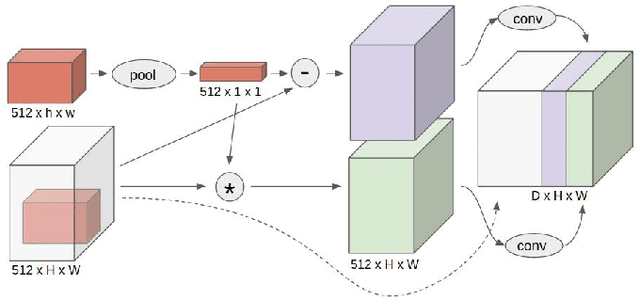

While state-of-the-art general object detectors are getting better and better, there are not many systems specifically designed to take advantage of the instance detection problem. For many applications, such as household robotics, a system may need to recognize a few very specific instances at a time. Speed can be critical in these applications, as can the need to recognize previously unseen instances. We introduce a Target Driven Instance Detector(TDID), which modifies existing general object detectors for the instance recognition setting. TDID not only improves performance on instances seen during training, with a fast runtime, but is also able to generalize to detect novel instances.
A Dataset for Developing and Benchmarking Active Vision
Mar 03, 2017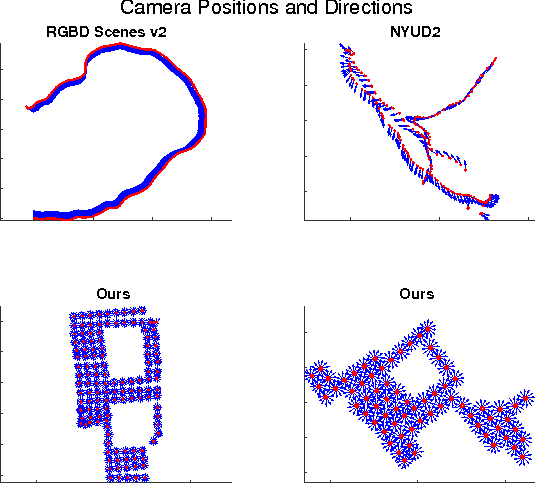


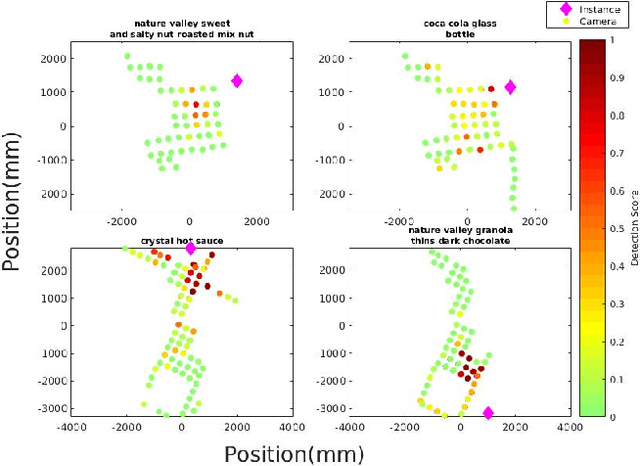
We present a new public dataset with a focus on simulating robotic vision tasks in everyday indoor environments using real imagery. The dataset includes 20,000+ RGB-D images and 50,000+ 2D bounding boxes of object instances densely captured in 9 unique scenes. We train a fast object category detector for instance detection on our data. Using the dataset we show that, although increasingly accurate and fast, the state of the art for object detection is still severely impacted by object scale, occlusion, and viewing direction all of which matter for robotics applications. We next validate the dataset for simulating active vision, and use the dataset to develop and evaluate a deep-network-based system for next best move prediction for object classification using reinforcement learning. Our dataset is available for download at cs.unc.edu/~ammirato/active_vision_dataset_website/.
Fast Single Shot Detection and Pose Estimation
Sep 19, 2016
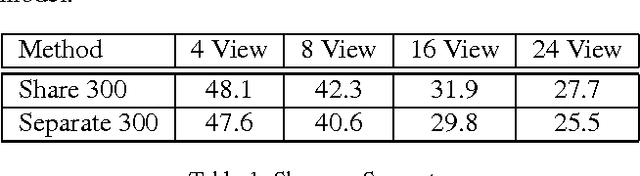
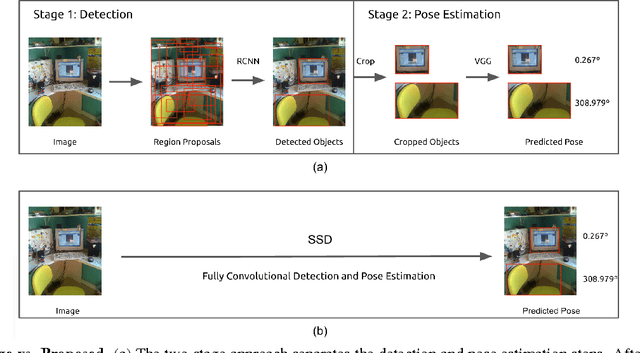
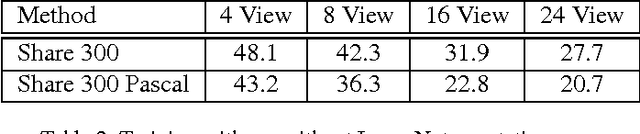
For applications in navigation and robotics, estimating the 3D pose of objects is as important as detection. Many approaches to pose estimation rely on detecting or tracking parts or keypoints [11, 21]. In this paper we build on a recent state-of-the-art convolutional network for slidingwindow detection [10] to provide detection and rough pose estimation in a single shot, without intermediate stages of detecting parts or initial bounding boxes. While not the first system to treat pose estimation as a categorization problem, this is the first attempt to combine detection and pose estimation at the same level using a deep learning approach. The key to the architecture is a deep convolutional network where scores for the presence of an object category, the offset for its location, and the approximate pose are all estimated on a regular grid of locations in the image. The resulting system is as accurate as recent work on pose estimation (42.4% 8 View mAVP on Pascal 3D+ [21] ) and significantly faster (46 frames per second (FPS) on a TITAN X GPU). This approach to detection and rough pose estimation is fast and accurate enough to be widely applied as a pre-processing step for tasks including high-accuracy pose estimation, object tracking and localization, and vSLAM.