 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointSplat: Efficient Geometry-Driven Pruning and Transformer Refinement for 3D Gaussian Splatting
Apr 10, 20263D Gaussian Splatting (3DGS) has recently unlocked real-time, high-fidelity novel view synthesis by representing scenes using explicit 3D primitives. However, traditional methods often require millions of Gaussians to capture complex scenes, leading to significant memory and storage demands. Recent approaches have addressed this issue through pruning and per-scene fine-tuning of Gaussian parameters, thereby reducing the model size while maintaining visual quality. These strategies typically rely on 2D images to compute important scores followed by scene-specific optimization. In this work, we introduce PointSplat, 3D geometry-driven prune-and-refine framework that bridges previously disjoint directions of gaussian pruning and transformer refinement. Our method includes two key components: (1) an efficient geometry-driven strategy that ranks Gaussians based solely on their 3D attributes, removing reliance on 2D images during pruning stage, and (2) a dual-branch encoder that separates, re-weights geometric and appearance to avoid feature imbalance. Extensive experiments on ScanNet++ and Replica across varying sparsity levels demonstrate that PointSplat consistently achieves competitive rendering quality and superior efficiency without additional per-scene optimization.
Toward Phonology-Guided Sign Language Motion Generation: A Diffusion Baseline and Conditioning Analysis
Mar 18, 2026Generating natural, correct, and visually smooth 3D avatar sign language motion conditioned on the text inputs continues to be very challenging. In this work, we train a generative model of 3D body motion and explore the role of phonological attribute conditioning for sign language motion generation, using ASL-LEX 2.0 annotations such as hand shape, hand location and movement. We first establish a strong diffusion baseline using an Human Motion MDM-style diffusion model with SMPL-X representation, which outperforms SignAvatar, a state-of-the-art CVAE method, on gloss discriminability metrics. We then systematically study the role of text conditioning using different text encoders (CLIP vs. T5), conditioning modes (gloss-only vs. gloss+phonological attributes), and attribute notation format (symbolic vs. natural language). Our analysis reveals that translating symbolic ASL-LEX notations to natural language is a necessary condition for effective CLIP-based attribute conditioning, while T5 is largely unaffected by this translation. Furthermore, our best-performing variant (CLIP with mapped attributes) outperforms SignAvatar across all metrics. These findings highlight input representation as a critical factor for text-encoder-based attribute conditioning, and motivate structured conditioning approaches where gloss and phonological attributes are encoded through independent pathways.
Gesture-Aware Pretraining and Token Fusion for 3D Hand Pose Estimation
Mar 18, 2026Estimating 3D hand pose from monocular RGB images is fundamental for applications in AR/VR, human-computer interaction, and sign language understanding. In this work we focus on a scenario where a discrete set of gesture labels is available and show that gesture semantics can serve as a powerful inductive bias for 3D pose estimation. We present a two-stage framework: gesture-aware pretraining that learns an informative embedding space using coarse and fine gesture labels from InterHand2.6M, followed by a per-joint token Transformer guided by gesture embeddings as intermediate representations for final regression of MANO hand parameters. Training is driven by a layered objective over parameters, joints, and structural constraints. Experiments on InterHand2.6M demonstrate that gesture-aware pretraining consistently improves single-hand accuracy over the state-of-the-art EANet baseline, and that the benefit transfers across architectures without any modification.
VarSplat: Uncertainty-aware 3D Gaussian Splatting for Robust RGB-D SLAM
Mar 10, 2026Simultaneous Localization and Mapping (SLAM) with 3D Gaussian Splatting (3DGS) enables fast, differentiable rendering and high-fidelity reconstruction across diverse real-world scenes. However, existing 3DGS-SLAM approaches handle measurement reliability implicitly, making pose estimation and global alignment susceptible to drift in low-texture regions, transparent surfaces, or areas with complex reflectance properties. To this end, we introduce VarSplat, an uncertainty-aware 3DGS-SLAM system that explicitly learns per-splat appearance variance. By using the law of total variance with alpha compositing, we then render differentiable per-pixel uncertainty map via efficient, single-pass rasterization. This map guides tracking, submap registration, and loop detection toward focusing on reliable regions and contributes to more stable optimization. Experimental results on Replica (synthetic) and TUM-RGBD, ScanNet, and ScanNet++ (real-world) show that VarSplat improves robustness and achieves competitive or superior tracking, mapping, and novel view synthesis rendering compared to existing studies for dense RGB-D SLAM.
Multi-temporal Adaptive Red-Green-Blue and Long-Wave Infrared Fusion for You Only Look Once-Based Landmine Detection from Unmanned Aerial Systems
Dec 23, 2025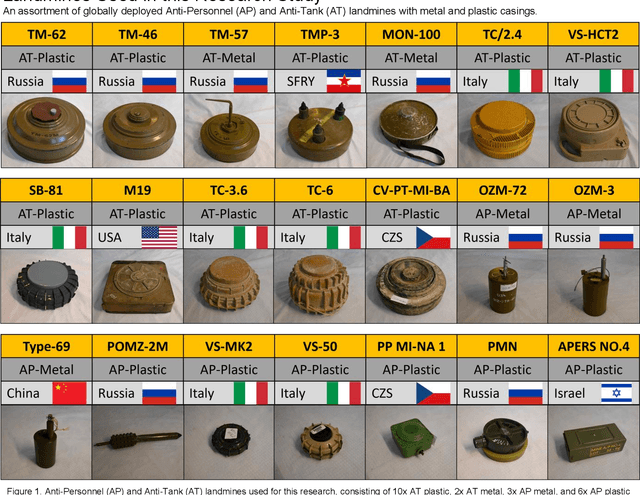

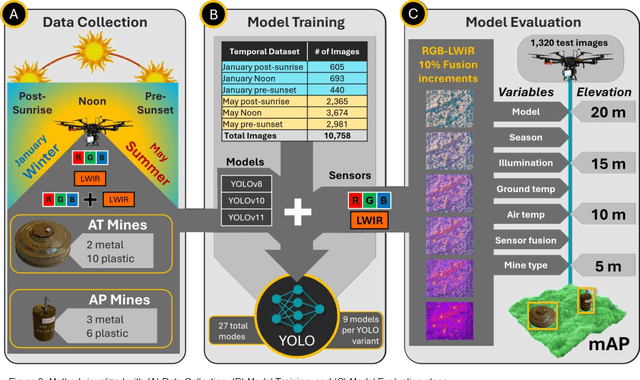
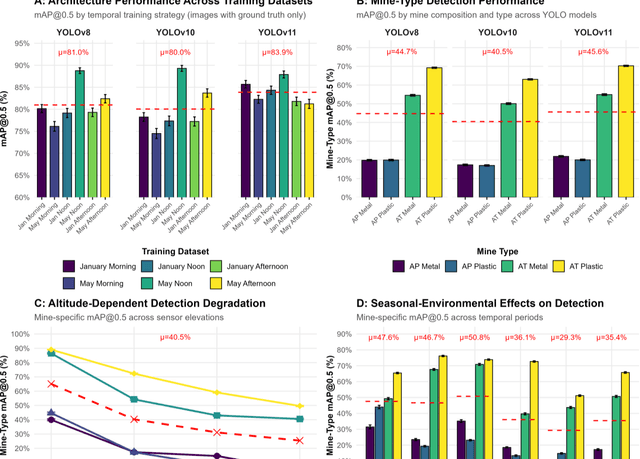
Landmines remain a persistent humanitarian threat, with 110 million actively deployed mines across 60 countries, claiming 26,000 casualties annually. This research evaluates adaptive Red-Green-Blue (RGB) and Long-Wave Infrared (LWIR) fusion for Unmanned Aerial Systems (UAS)-based detection of surface-laid landmines, leveraging the thermal contrast between the ordnance and the surrounding soil to enhance feature extraction. Using You Only Look Once (YOLO) architectures (v8, v10, v11) across 114 test images, generating 35,640 model-condition evaluations, YOLOv11 achieved optimal performance (86.8% mAP), with 10 to 30% thermal fusion at 5 to 10m altitude identified as the optimal detection parameters. A complementary architectural comparison revealed that while RF-DETR achieved the highest accuracy (69.2% mAP), followed by Faster R-CNN (67.6%), YOLOv11 (64.2%), and RetinaNet (50.2%), YOLOv11 trained 17.7 times faster than the transformer-based RF-DETR (41 minutes versus 12 hours), presenting a critical accuracy-efficiency tradeoff for operational deployment. Aggregated multi-temporal training datasets outperformed season-specific approaches by 1.8 to 9.6%, suggesting that models benefit from exposure to diverse thermal conditions. Anti-Tank (AT) mines achieved 61.9% detection accuracy, compared with 19.2% for Anti-Personnel (AP) mines, reflecting both the size differential and thermal-mass differences between these ordnance classes. As this research examined surface-laid mines where thermal contrast is maximized, future research should quantify thermal contrast effects for mines buried at varying depths across heterogeneous soil types.
TRAVEL: Training-Free Retrieval and Alignment for Vision-and-Language Navigation
Feb 11, 2025



In this work, we propose a modular approach for the Vision-Language Navigation (VLN) task by decomposing the problem into four sub-modules that use state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs) in a zero-shot setting. Given navigation instruction in natural language, we first prompt LLM to extract the landmarks and the order in which they are visited. Assuming the known model of the environment, we retrieve the top-k locations of the last landmark and generate $k$ path hypotheses from the starting location to the last landmark using the shortest path algorithm on the topological map of the environment. Each path hypothesis is represented by a sequence of panoramas. We then use dynamic programming to compute the alignment score between the sequence of panoramas and the sequence of landmark names, which match scores obtained from VLM. Finally, we compute the nDTW metric between the hypothesis that yields the highest alignment score to evaluate the path fidelity. We demonstrate superior performance compared to other approaches that use joint semantic maps like VLMaps \cite{vlmaps} on the complex R2R-Habitat \cite{r2r} instruction dataset and quantify in detail the effect of visual grounding on navigation performance.
Structured Spatial Reasoning with Open Vocabulary Object Detectors
Oct 09, 2024
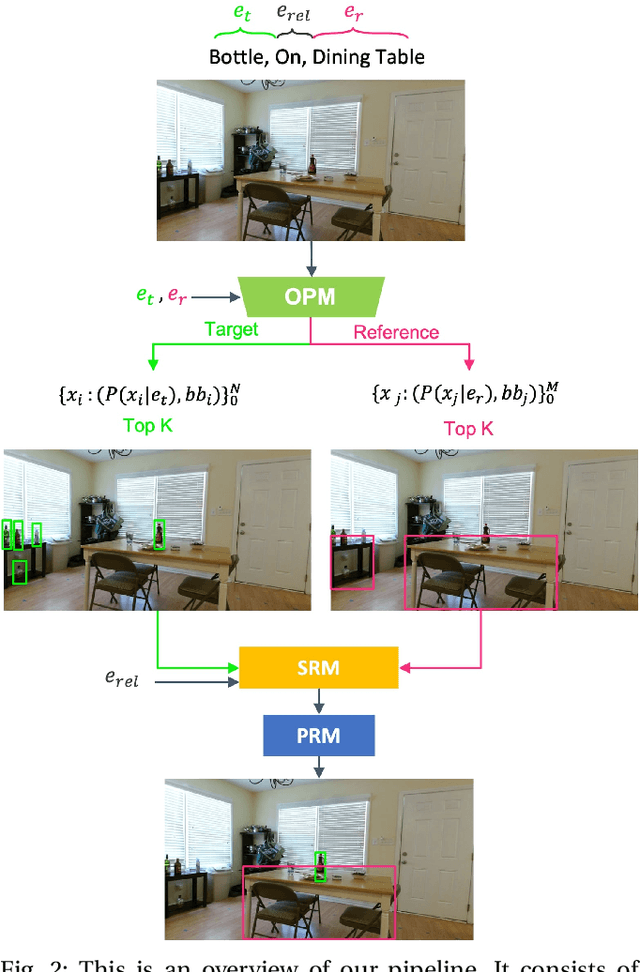
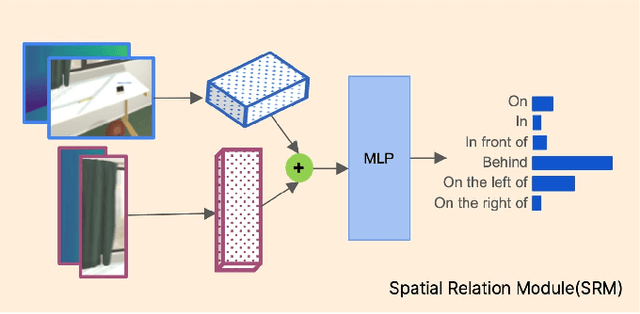

Reasoning about spatial relationships between objects is essential for many real-world robotic tasks, such as fetch-and-delivery, object rearrangement, and object search. The ability to detect and disambiguate different objects and identify their location is key to successful completion of these tasks. Several recent works have used powerful Vision and Language Models (VLMs) to unlock this capability in robotic agents. In this paper we introduce a structured probabilistic approach that integrates rich 3D geometric features with state-of-the-art open-vocabulary object detectors to enhance spatial reasoning for robotic perception. The approach is evaluated and compared against zero-shot performance of the state-of-the-art Vision and Language Models (VLMs) on spatial reasoning tasks. To enable this comparison, we annotate spatial clauses in real-world RGB-D Active Vision Dataset [1] and conduct experiments on this and the synthetic Semantic Abstraction [2] dataset. Results demonstrate the effectiveness of the proposed method, showing superior performance of grounding spatial relations over state of the art open-source VLMs by more than 20%.
GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
Jun 19, 2024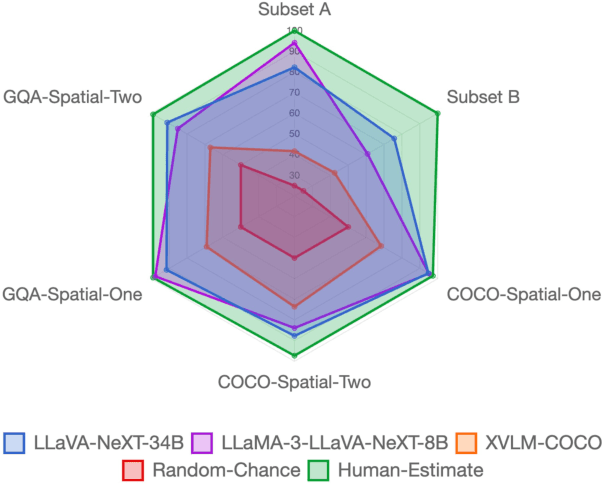

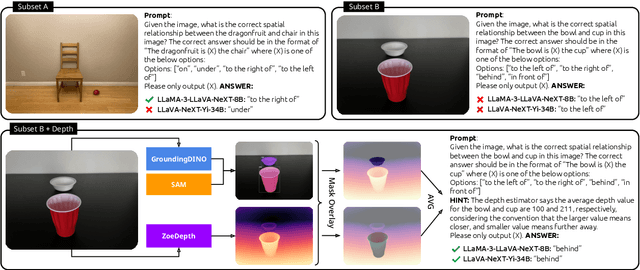

The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
Apr 29, 2024



Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
Fingerspelling PoseNet: Enhancing Fingerspelling Translation with Pose-Based Transformer Models
Nov 20, 2023We address the task of American Sign Language fingerspelling translation using videos in the wild. We exploit advances in more accurate hand pose estimation and propose a novel architecture that leverages the transformer based encoder-decoder model enabling seamless contextual word translation. The translation model is augmented by a novel loss term that accurately predicts the length of the finger-spelled word, benefiting both training and inference. We also propose a novel two-stage inference approach that re-ranks the hypotheses using the language model capabilities of the decoder. Through extensive experiments, we demonstrate that our proposed method outperforms the state-of-the-art models on ChicagoFSWild and ChicagoFSWild+ achieving more than 10% relative improvement in performance. Our findings highlight the effectiveness of our approach and its potential to advance fingerspelling recognition in sign language translation. Code is also available at https://github.com/pooyafayyaz/Fingerspelling-PoseNet.