 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Code Language Models to Detect Cross-Language Bugs
Jul 29, 2025Multilingual programming, which involves using multiple programming languages (PLs) in a single project, is increasingly common due to its benefits. However, it introduces cross-language bugs (CLBs), which arise from interactions between different PLs and are difficult to detect by single-language bug detection tools. This paper investigates the potential of pre-trained code language models (CodeLMs) in CLB detection. We developed CLCFinder, a cross-language code identification tool, and constructed a CLB dataset involving three PL combinations (Python-C/C++, Java-C/C++, and Python-Java) with nine interaction types. We fine-tuned 13 CodeLMs on this dataset and evaluated their performance, analyzing the effects of dataset size, token sequence length, and code comments. Results show that all CodeLMs performed poorly before fine-tuning, but exhibited varying degrees of performance improvement after fine-tuning, with UniXcoder-base achieving the best F1 score (0.7407). Notably, small fine-tuned CodeLMs tended to performe better than large ones. CodeLMs fine-tuned on single-language bug datasets performed poorly on CLB detection, demonstrating the distinction between CLBs and single-language bugs. Additionally, increasing the fine-tuning dataset size significantly improved performance, while longer token sequences did not necessarily improve the model performance. The impact of code comments varied across models. Some fine-tuned CodeLMs' performance was improved, while others showed degraded performance.
RepText: Rendering Visual Text via Replicating
Apr 28, 2025Although contemporary text-to-image generation models have achieved remarkable breakthroughs in producing visually appealing images, their capacity to generate precise and flexible typographic elements, especially non-Latin alphabets, remains constrained. To address these limitations, we start from an naive assumption that text understanding is only a sufficient condition for text rendering, but not a necessary condition. Based on this, we present RepText, which aims to empower pre-trained monolingual text-to-image generation models with the ability to accurately render, or more precisely, replicate, multilingual visual text in user-specified fonts, without the need to really understand them. Specifically, we adopt the setting from ControlNet and additionally integrate language agnostic glyph and position of rendered text to enable generating harmonized visual text, allowing users to customize text content, font and position on their needs. To improve accuracy, a text perceptual loss is employed along with the diffusion loss. Furthermore, to stabilize rendering process, at the inference phase, we directly initialize with noisy glyph latent instead of random initialization, and adopt region masks to restrict the feature injection to only the text region to avoid distortion of the background. We conducted extensive experiments to verify the effectiveness of our RepText relative to existing works, our approach outperforms existing open-source methods and achieves comparable results to native multi-language closed-source models. To be more fair, we also exhaustively discuss its limitations in the end.
Connecting the Unconnectable through Feedback
Jan 04, 2025



Reliable uplink connectivity remains a persistent challenge for IoT devices, particularly those at the cell edge, due to their limited transmit power and single-antenna configurations. This paper introduces a novel framework aimed at connecting the unconnectable, leveraging real-time feedback from access points (APs) to enhance uplink coverage without increasing the energy consumption of IoT devices. At the core of this approach are feedback channel codes, which enable IoT devices to dynamically adapt their transmission strategies based on AP decoding feedback, thereby reducing the critical uplink SNR required for successful communication. Analytical models are developed to quantify the coverage probability and the number of connectable APs, providing a comprehensive understanding of the system's performance. Numerical results validate the proposed method, demonstrating substantial improvements in coverage range and connectivity, particularly for devices at the cell edge, with up to a 51% boost in connectable APs. Our approach offers a robust and energy-efficient solution to overcoming uplink coverage limitations, enabling IoT networks to connect devices in challenging environments.
Flexible Active Safety Motion Control for Robotic Obstacle Avoidance: A CBF-Guided MPC Approach
May 20, 2024



A flexible active safety motion (FASM) control approach is proposed for the avoidance of dynamic obstacles and the reference tracking in robot manipulators. The distinctive feature of the proposed method lies in its utilization of control barrier functions (CBF) to design flexible CBF-guided safety criteria (CBFSC) with dynamically optimized decay rates, thereby offering flexibility and active safety for robot manipulators in dynamic environments. First, discrete-time CBFs are employed to formulate the novel flexible CBFSC with dynamic decay rates for robot manipulators. Following that, the model predictive control (MPC) philosophy is applied, integrating flexible CBFSC as safety constraints into the receding-horizon optimization problem. Significantly, the decay rates of the designed CBFSC are incorporated as decision variables in the optimization problem, facilitating the dynamic enhancement of flexibility during the obstacle avoidance process. In particular, a novel cost function that integrates a penalty term is designed to dynamically adjust the safety margins of the CBFSC. Finally, experiments are conducted in various scenarios using a Universal Robots 5 (UR5) manipulator to validate the effectiveness of the proposed approach.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Comparison of Model-Free and Model-Based Learning-Informed Planning for PointGoal Navigation
Dec 17, 2022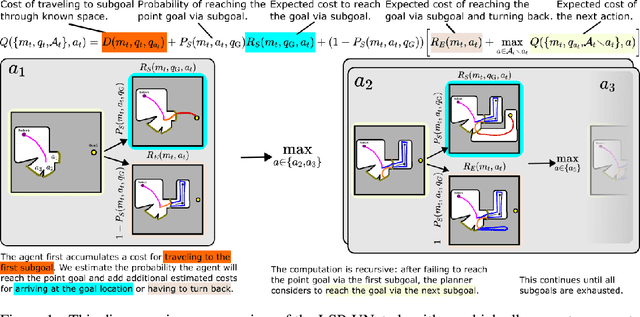


In recent years several learning approaches to point goal navigation in previously unseen environments have been proposed. They vary in the representations of the environments, problem decomposition, and experimental evaluation. In this work, we compare the state-of-the-art Deep Reinforcement Learning based approaches with Partially Observable Markov Decision Process (POMDP) formulation of the point goal navigation problem. We adapt the (POMDP) sub-goal framework proposed by [1] and modify the component that estimates frontier properties by using partial semantic maps of indoor scenes built from images' semantic segmentation. In addition to the well-known completeness of the model-based approach, we demonstrate that it is robust and efficient in that it leverages informative, learned properties of the frontiers compared to an optimistic frontier-based planner. We also demonstrate its data efficiency compared to the end-to-end deep reinforcement learning approaches. We compare our results against an optimistic planner, ANS and DD-PPO on Matterport3D dataset using the Habitat Simulator. We show comparable, though slightly worse performance than the SOTA DD-PPO approach, yet with far fewer data.
Learning-Augmented Model-Based Planning for Visual Exploration
Nov 15, 2022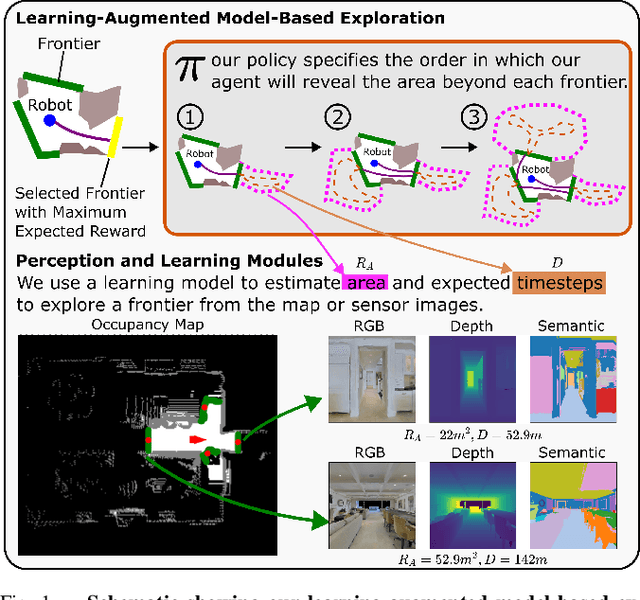



We consider the problem of time-limited robotic exploration in previously unseen environments where exploration is limited by a predefined amount of time. We propose a novel exploration approach using learning-augmented model-based planning. We generate a set of subgoals associated with frontiers on the current map and derive a Bellman Equation for exploration with these subgoals. Visual sensing and advances in semantic mapping of indoor scenes are exploited for training a deep convolutional neural network to estimate properties associated with each frontier: the expected unobserved area beyond the frontier and the expected timesteps (discretized actions) required to explore it. The proposed model-based planner is guaranteed to explore the whole scene if time permits. We thoroughly evaluate our approach on a large-scale pseudo-realistic indoor dataset (Matterport3D) with the Habitat simulator. We compare our approach with classical and more recent RL-based exploration methods, demonstrating its clear advantages in several settings.
Self-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Oct 04, 2022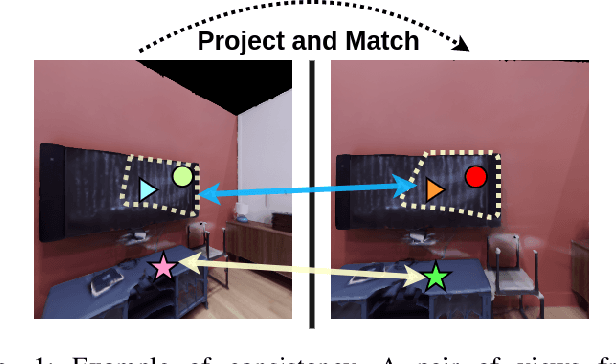
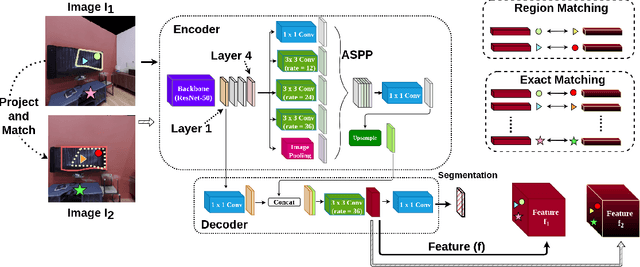

The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.
Using Unmanned Aerial Systems (UAS) for Assessing and Monitoring Fall Hazard Prevention Systems in High-rise Building Projects
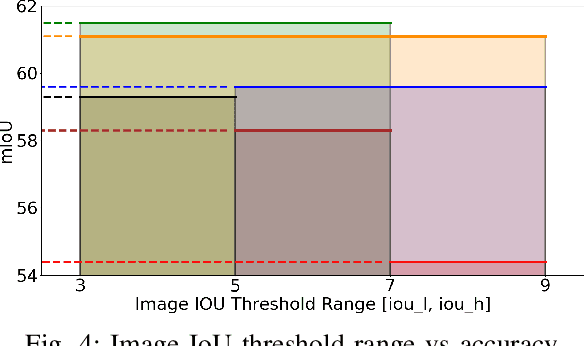
Sep 27, 2022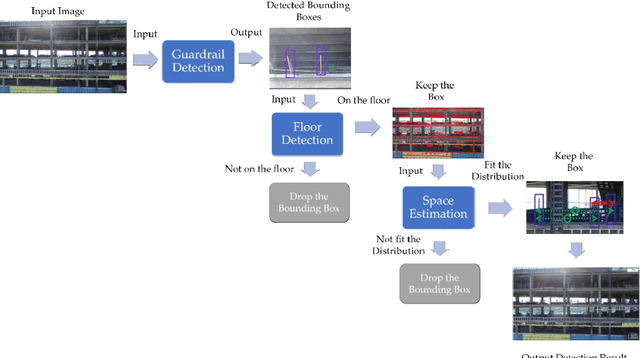


This study develops a framework for unmanned aerial systems (UASs) to monitor fall hazard prevention systems near unprotected edges and openings in high-rise building projects. A three-step machine-learning-based framework was developed and tested to detect guardrail posts from the images captured by UAS. First, a guardrail detector was trained to localize the candidate locations of posts supporting the guardrail. Since images were used in this process collected from an actual job site, several false detections were identified. Therefore, additional constraints were introduced in the following steps to filter out false detections. Second, the research team applied a horizontal line detector to the image to properly detect floors and remove the detections that were not close to the floors. Finally, since the guardrail posts are installed with approximately normal distribution between each post, the space between them was estimated and used to find the most likely distance between the two posts. The research team used various combinations of the developed approaches to monitor guardrail systems in the captured images from a high-rise building project. Comparing the precision and recall metrics indicated that the cascade classifier achieves better performance with floor detection and guardrail spacing estimation. The research outcomes illustrate that the proposed guardrail recognition system can improve the assessment of guardrails and facilitate the safety engineer's task of identifying fall hazards in high-rise building projects.
Uncertainty Aware Proposal Segmentation for Unknown Object Detection
Nov 25, 2021
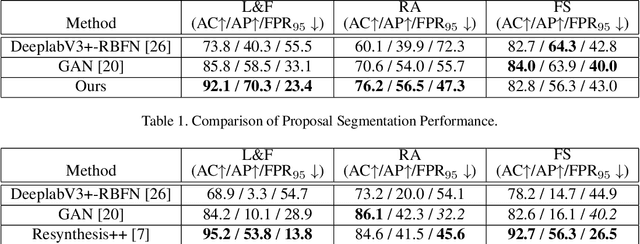

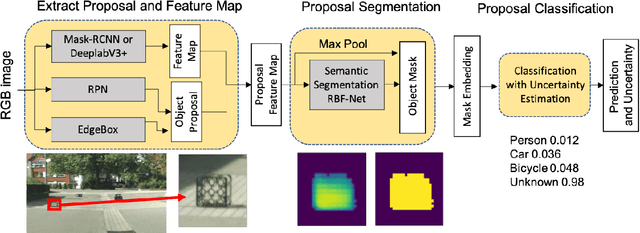
Recent efforts in deploying Deep Neural Networks for object detection in real world applications, such as autonomous driving, assume that all relevant object classes have been observed during training. Quantifying the performance of these models in settings when the test data is not represented in the training set has mostly focused on pixel-level uncertainty estimation techniques of models trained for semantic segmentation. This paper proposes to exploit additional predictions of semantic segmentation models and quantifying its confidences, followed by classification of object hypotheses as known vs. unknown, out of distribution objects. We use object proposals generated by Region Proposal Network (RPN) and adapt distance aware uncertainty estimation of semantic segmentation using Radial Basis Functions Networks (RBFN) for class agnostic object mask prediction. The augmented object proposals are then used to train a classifier for known vs. unknown objects categories. Experimental results demonstrate that the proposed method achieves parallel performance to state of the art methods for unknown object detection and can also be used effectively for reducing object detectors' false positive rate. Our method is well suited for applications where prediction of non-object background categories obtained by semantic segmentation is reliable.