 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Search in Partially-Known Environments via LLM-informed Model-based Planning and Prompt Selection
Mar 25, 2026We present a novel LLM-informed model-based planning framework, and a novel prompt selection method, for object search in partially-known environments. Our approach uses an LLM to estimate statistics about the likelihood of finding the target object when searching various locations throughout the scene that, combined with travel costs extracted from the environment map, are used to instantiate a model, thus using the LLM to inform planning and achieve effective search performance. Moreover, the abstraction upon which our approach relies is amenable to deployment-time model selection via the recent offline replay approach, an insight we leverage to enable fast prompt and LLM selection during deployment. Simulation experiments demonstrate that our LLM-informed model-based planning approach outperforms the baseline planning strategy that fully relies on LLM and optimistic strategy with as much as 11.8% and 39.2% improvements respectively, and our bandit-like selection approach enables quick selection of best prompts and LLMs resulting in 6.5% lower average cost and 33.8% lower average cumulative regret over baseline UCB bandit selection. Real-robot experiments in an apartment demonstrate similar improvements and so further validate our approach.
Multi-Robot Learning-Informed Task Planning Under Uncertainty
Mar 20, 2026We want a multi-robot team to complete complex tasks in minimum time where the locations of task-relevant objects are not known. Effective task completion requires reasoning over long horizons about the likely locations of task-relevant objects, how individual actions contribute to overall progress, and how to coordinate team efforts. Planning in this setting is extremely challenging: even when task-relevant information is partially known, coordinating which robot performs which action and when is difficult, and uncertainty introduces a multiplicity of possible outcomes for each action, which further complicates long-horizon decision-making and coordination. To address this, we propose a multi-robot planning abstraction that integrates learning to estimate uncertain aspects of the environment with model-based planning for long-horizon coordination. We demonstrate the efficient multi-stage task planning of our approach for 1, 2, and 3 robot teams over competitive baselines in large ProcTHOR household environments. Additionally, we demonstrate the effectiveness of our approach with a team of two LoCoBot mobile robots in real household settings.
Why Do LLM-based Web Agents Fail? A Hierarchical Planning Perspective
Mar 15, 2026Large language model (LLM) web agents are increasingly used for web navigation but remain far from human reliability on realistic, long-horizon tasks. Existing evaluations focus primarily on end-to-end success, offering limited insight into where failures arise. We propose a hierarchical planning framework to analyze web agents across three layers (i.e., high-level planning, low-level execution, and replanning), enabling process-based evaluation of reasoning, grounding, and recovery. Our experiments show that structured Planning Domain Definition Language (PDDL) plans produce more concise and goal-directed strategies than natural language (NL) plans, but low-level execution remains the dominant bottleneck. These results indicate that improving perceptual grounding and adaptive control, not only high-level reasoning, is critical for achieving human-level reliability. This hierarchical perspective provides a principled foundation for diagnosing and advancing LLM web agents.
Effective Task Planning with Missing Objects using Learning-Informed Object Search
Feb 13, 2026Task planning for mobile robots often assumes full environment knowledge and so popular approaches, like planning via the PDDL, cannot plan when the locations of task-critical objects are unknown. Recent learning-driven object search approaches are effective, but operate as standalone tools and so are not straightforwardly incorporated into full task planners, which must additionally determine both what objects are necessary and when in the plan they should be sought out. To address this limitation, we develop a planning framework centered around novel model-based LIOS actions: each a policy that aims to find and retrieve a single object. High-level planning treats LIOS actions as deterministic and so -- informed by model-based calculations of the expected cost of each -- generates plans that interleave search and execution for effective, sound, and complete learning-informed task planning despite uncertainty. Our work effectively reasons about uncertainty while maintaining compatibility with existing full-knowledge solvers. In simulated ProcTHOR homes and in the real world, our approach outperforms non-learned and learned baselines on tasks including retrieval and meal prep.
Learning-Augmented Model-Based Multi-Robot Planning for Time-Critical Search and Inspection Under Uncertainty
Jul 08, 2025In disaster response or surveillance operations, quickly identifying areas needing urgent attention is critical, but deploying response teams to every location is inefficient or often impossible. Effective performance in this domain requires coordinating a multi-robot inspection team to prioritize inspecting locations more likely to need immediate response, while also minimizing travel time. This is particularly challenging because robots must directly observe the locations to determine which ones require additional attention. This work introduces a multi-robot planning framework for coordinated time-critical multi-robot search under uncertainty. Our approach uses a graph neural network to estimate the likelihood of PoIs needing attention from noisy sensor data and then uses those predictions to guide a multi-robot model-based planner to determine the cost-effective plan. Simulated experiments demonstrate that our planner improves performance at least by 16.3\%, 26.7\%, and 26.2\% for 1, 3, and 5 robots, respectively, compared to non-learned and learned baselines. We also validate our approach on real-world platforms using quad-copters.
Anticipatory Planning for Performant Long-Lived Robot in Large-Scale Home-Like Environments
Nov 19, 2024We consider the setting where a robot must complete a sequence of tasks in a persistent large-scale environment, given one at a time. Existing task planners often operate myopically, focusing solely on immediate goals without considering the impact of current actions on future tasks. Anticipatory planning, which reduces the joint objective of the immediate planning cost of the current task and the expected cost associated with future subsequent tasks, offers an approach for improving long-lived task planning. However, applying anticipatory planning in large-scale environments presents significant challenges due to the sheer number of assets involved, which strains the scalability of learning and planning. In this research, we introduce a model-based anticipatory task planning framework designed to scale to large-scale realistic environments. Our framework uses a GNN in particular via a representation inspired by a 3D Scene Graph to learn the essential properties of the environment crucial to estimating the state's expected cost and a sampling-based procedure for practical large-scale anticipatory planning. Our experimental results show that our planner reduces the cost of task sequence by 5.38% in home and 31.5% in restaurant settings. If given time to prepare in advance using our model reduces task sequence costs by 40.6% and 42.5%, respectively.
Anticipatory Task and Motion Planning
Jul 18, 2024



We consider a sequential task and motion planning (tamp) setting in which a robot is assigned continuous-space rearrangement-style tasks one-at-a-time in an environment that persists between each. Lacking advance knowledge of future tasks, existing (myopic) planning strategies unwittingly introduce side effects that impede completion of subsequent tasks: e.g., by blocking future access or manipulation. We present anticipatory task and motion planning, in which estimates of expected future cost from a learned model inform selection of plans generated by a model-based tamp planner so as to avoid such side effects, choosing configurations of the environment that both complete the task and minimize overall cost. Simulated multi-task deployments in navigation-among-movable-obstacles and cabinet-loading domains yield improvements of 32.7% and 16.7% average per-task cost respectively. When given time in advance to prepare the environment, our learning-augmented planning approach yields improvements of 83.1% and 22.3%. Both showcase the value of our approach. Finally, we also demonstrate anticipatory tamp on a real-world Fetch mobile manipulator.
Active Information Gathering for Long-Horizon Navigation Under Uncertainty by Learning the Value of Information
Mar 05, 2024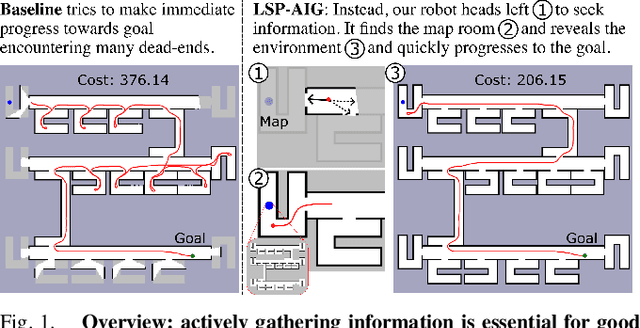

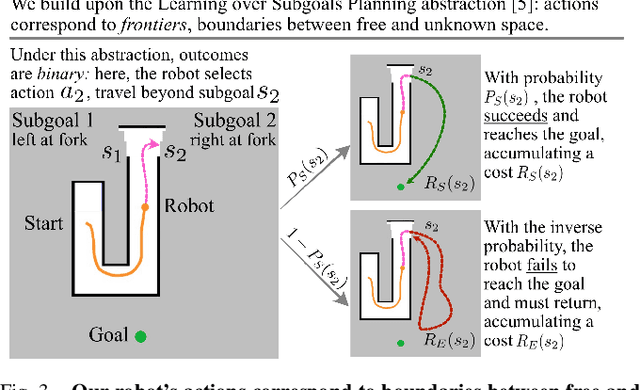
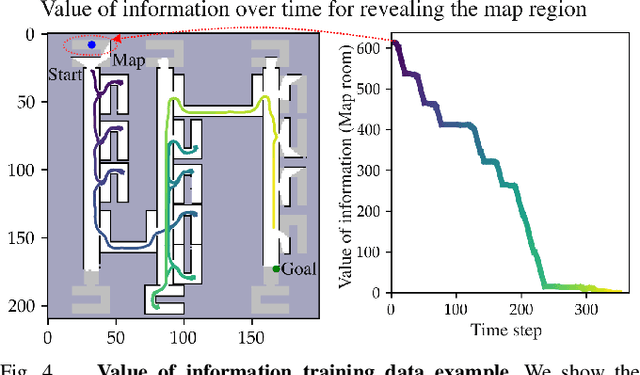
We address the task of long-horizon navigation in partially mapped environments for which active gathering of information about faraway unseen space is essential for good behavior. We present a novel planning strategy that, at training time, affords tractable computation of the value of information associated with revealing potentially informative regions of unseen space, data used to train a graph neural network to predict the goodness of temporally-extended exploratory actions. Our learning-augmented model-based planning approach predicts the expected value of information of revealing unseen space and is capable of using these predictions to actively seek information and so improve long-horizon navigation. Across two simulated office-like environments, our planner outperforms competitive learned and non-learned baseline navigation strategies, achieving improvements of up to 63.76% and 36.68%, demonstrating its capacity to actively seek performance-critical information.
Improving Reliable Navigation under Uncertainty via Predictions Informed by Non-Local Information
Jul 26, 2023We improve reliable, long-horizon, goal-directed navigation in partially-mapped environments by using non-locally available information to predict the goodness of temporally-extended actions that enter unseen space. Making predictions about where to navigate in general requires non-local information: any observations the robot has seen so far may provide information about the goodness of a particular direction of travel. Building on recent work in learning-augmented model-based planning under uncertainty, we present an approach that can both rely on non-local information to make predictions (via a graph neural network) and is reliable by design: it will always reach its goal, even when learning does not provide accurate predictions. We conduct experiments in three simulated environments in which non-local information is needed to perform well. In our large scale university building environment, generated from real-world floorplans to the scale, we demonstrate a 9.3\% reduction in cost-to-go compared to a non-learned baseline and a 14.9\% reduction compared to a learning-informed planner that can only use local information to inform its predictions.
Guided Sampling-Based Motion Planning with Dynamics in Unknown Environments
Jun 15, 2023Despite recent progress improving the efficiency and quality of motion planning, planning collision-free and dynamically-feasible trajectories in partially-mapped environments remains challenging, since constantly replanning as unseen obstacles are revealed during navigation both incurs significant computational expense and can introduce problematic oscillatory behavior. To improve the quality of motion planning in partial maps, this paper develops a framework that augments sampling-based motion planning to leverage a high-level discrete layer and prior solutions to guide motion-tree expansion during replanning, affording both (i) faster planning and (ii) improved solution coherence. Our framework shows significant improvements in runtime and solution distance when compared with other sampling-based motion planners.