 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEHME: A Vision-Language Model For Evaluating Handwritten Mathematics Expressions
Oct 26, 2025Automatically assessing handwritten mathematical solutions is an important problem in educational technology with practical applications, but it remains a significant challenge due to the diverse formats, unstructured layouts, and symbolic complexity of student work. To address this challenge, we introduce VEHME-a Vision-Language Model for Evaluating Handwritten Mathematics Expressions-designed to assess open-form handwritten math responses with high accuracy and interpretable reasoning traces. VEHME integrates a two-phase training pipeline: (i) supervised fine-tuning using structured reasoning data, and (ii) reinforcement learning that aligns model outputs with multi-dimensional grading objectives, including correctness, reasoning depth, and error localization. To enhance spatial understanding, we propose an Expression-Aware Visual Prompting Module, trained on our synthesized multi-line math expressions dataset to robustly guide attention in visually heterogeneous inputs. Evaluated on AIHub and FERMAT datasets, VEHME achieves state-of-the-art performance among open-source models and approaches the accuracy of proprietary systems, demonstrating its potential as a scalable and accessible tool for automated math assessment. Our training and experiment code is publicly available at our GitHub repository.
Anticipatory Task and Motion Planning
Jul 18, 2024



We consider a sequential task and motion planning (tamp) setting in which a robot is assigned continuous-space rearrangement-style tasks one-at-a-time in an environment that persists between each. Lacking advance knowledge of future tasks, existing (myopic) planning strategies unwittingly introduce side effects that impede completion of subsequent tasks: e.g., by blocking future access or manipulation. We present anticipatory task and motion planning, in which estimates of expected future cost from a learned model inform selection of plans generated by a model-based tamp planner so as to avoid such side effects, choosing configurations of the environment that both complete the task and minimize overall cost. Simulated multi-task deployments in navigation-among-movable-obstacles and cabinet-loading domains yield improvements of 32.7% and 16.7% average per-task cost respectively. When given time in advance to prepare the environment, our learning-augmented planning approach yields improvements of 83.1% and 22.3%. Both showcase the value of our approach. Finally, we also demonstrate anticipatory tamp on a real-world Fetch mobile manipulator.
Human-Robot Co-Transportation with Human Uncertainty-Aware MPC and Pose Optimization
Mar 31, 2024



This paper proposes a new control algorithm for human-robot co-transportation based on a robot manipulator equipped with a mobile base and a robotic arm. The primary focus is to adapt to human uncertainties through the robot's whole-body dynamics and pose optimization. We introduce an augmented Model Predictive Control (MPC) formulation that explicitly models human uncertainties and contains extra variables than regular MPC to optimize the pose of the robotic arm. The core of our methodology involves a two-step iterative design: At each planning horizon, we select the best pose of the robotic arm (joint angle combination) from a candidate set, aiming to achieve the lowest estimated control cost. This selection is based on solving an uncertainty-aware Discrete Algebraic Ricatti Equation (DARE), which also informs the optimal control inputs for both the mobile base and the robotic arm. To validate the effectiveness of the proposed approach, we provide theoretical derivation for the uncertainty-aware DARE and perform simulated and proof-of-concept hardware experiments using a Fetch robot under varying conditions, including different nominal trajectories and noise levels. The results reveal that our proposed approach outperforms baseline algorithms, maintaining similar execution time with that do not consider human uncertainty or do not perform pose optimization.
Toward Human-Like Social Robot Navigation: A Large-Scale, Multi-Modal, Social Human Navigation Dataset
Mar 27, 2023

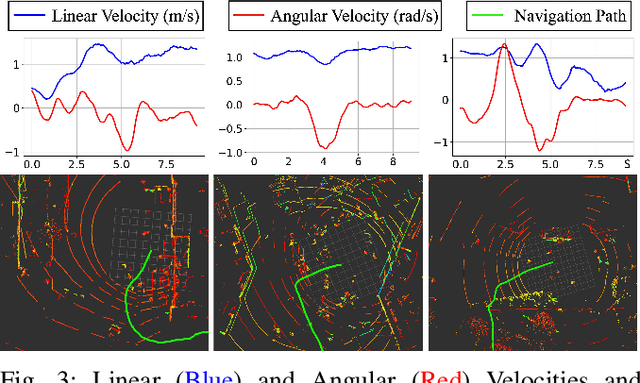

Humans are well-adept at navigating public spaces shared with others, where current autonomous mobile robots still struggle: while safely and efficiently reaching their goals, humans communicate their intentions and conform to unwritten social norms on a daily basis; conversely, robots become clumsy in those daily social scenarios, getting stuck in dense crowds, surprising nearby pedestrians, or even causing collisions. While recent research on robot learning has shown promises in data-driven social robot navigation, good-quality training data is still difficult to acquire through either trial and error or expert demonstrations. In this work, we propose to utilize the body of rich, widely available, social human navigation data in many natural human-inhabited public spaces for robots to learn similar, human-like, socially compliant navigation behaviors. To be specific, we design an open-source egocentric data collection sensor suite wearable by walking humans to provide multi-modal robot perception data; we collect a large-scale (~50 km, 10 hours, 150 trials, 7 humans) dataset in a variety of public spaces which contain numerous natural social navigation interactions; we analyze our dataset, demonstrate its usability, and point out future research directions and use cases.