 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Search in Partially-Known Environments via LLM-informed Model-based Planning and Prompt Selection
Mar 25, 2026We present a novel LLM-informed model-based planning framework, and a novel prompt selection method, for object search in partially-known environments. Our approach uses an LLM to estimate statistics about the likelihood of finding the target object when searching various locations throughout the scene that, combined with travel costs extracted from the environment map, are used to instantiate a model, thus using the LLM to inform planning and achieve effective search performance. Moreover, the abstraction upon which our approach relies is amenable to deployment-time model selection via the recent offline replay approach, an insight we leverage to enable fast prompt and LLM selection during deployment. Simulation experiments demonstrate that our LLM-informed model-based planning approach outperforms the baseline planning strategy that fully relies on LLM and optimistic strategy with as much as 11.8% and 39.2% improvements respectively, and our bandit-like selection approach enables quick selection of best prompts and LLMs resulting in 6.5% lower average cost and 33.8% lower average cumulative regret over baseline UCB bandit selection. Real-robot experiments in an apartment demonstrate similar improvements and so further validate our approach.
Multi-Robot Learning-Informed Task Planning Under Uncertainty
Mar 20, 2026We want a multi-robot team to complete complex tasks in minimum time where the locations of task-relevant objects are not known. Effective task completion requires reasoning over long horizons about the likely locations of task-relevant objects, how individual actions contribute to overall progress, and how to coordinate team efforts. Planning in this setting is extremely challenging: even when task-relevant information is partially known, coordinating which robot performs which action and when is difficult, and uncertainty introduces a multiplicity of possible outcomes for each action, which further complicates long-horizon decision-making and coordination. To address this, we propose a multi-robot planning abstraction that integrates learning to estimate uncertain aspects of the environment with model-based planning for long-horizon coordination. We demonstrate the efficient multi-stage task planning of our approach for 1, 2, and 3 robot teams over competitive baselines in large ProcTHOR household environments. Additionally, we demonstrate the effectiveness of our approach with a team of two LoCoBot mobile robots in real household settings.
Effective Task Planning with Missing Objects using Learning-Informed Object Search
Feb 13, 2026Task planning for mobile robots often assumes full environment knowledge and so popular approaches, like planning via the PDDL, cannot plan when the locations of task-critical objects are unknown. Recent learning-driven object search approaches are effective, but operate as standalone tools and so are not straightforwardly incorporated into full task planners, which must additionally determine both what objects are necessary and when in the plan they should be sought out. To address this limitation, we develop a planning framework centered around novel model-based LIOS actions: each a policy that aims to find and retrieve a single object. High-level planning treats LIOS actions as deterministic and so -- informed by model-based calculations of the expected cost of each -- generates plans that interleave search and execution for effective, sound, and complete learning-informed task planning despite uncertainty. Our work effectively reasons about uncertainty while maintaining compatibility with existing full-knowledge solvers. In simulated ProcTHOR homes and in the real world, our approach outperforms non-learned and learned baselines on tasks including retrieval and meal prep.
Using Contextual Information for Sentence-level Morpheme Segmentation
Mar 15, 2024Recent advancements in morpheme segmentation primarily emphasize word-level segmentation, often neglecting the contextual relevance within the sentence. In this study, we redefine the morpheme segmentation task as a sequence-to-sequence problem, treating the entire sentence as input rather than isolating individual words. Our findings reveal that the multilingual model consistently exhibits superior performance compared to monolingual counterparts. While our model did not surpass the performance of the current state-of-the-art, it demonstrated comparable efficacy with high-resource languages while revealing limitations in low-resource language scenarios.
Data-Efficient Policy Selection for Navigation in Partial Maps via Subgoal-Based Abstraction
Apr 03, 2023

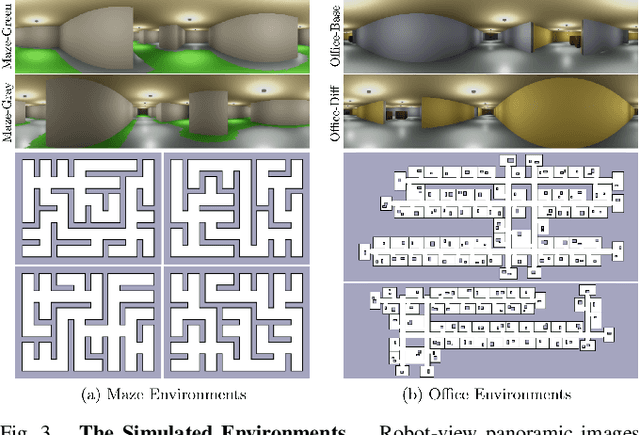
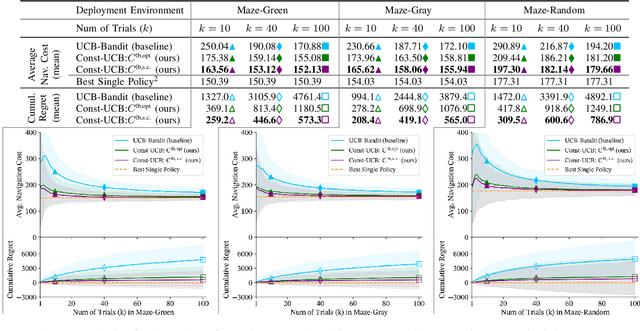
We present a novel approach for fast and reliable policy selection for navigation in partial maps. Leveraging the recent learning-augmented model-based Learning over Subgoals Planning (LSP) abstraction to plan, our robot reuses data collected during navigation to evaluate how well other alternative policies could have performed via a procedure we call offline alt-policy replay. Costs from offline alt-policy replay constrain policy selection among the LSP-based policies during deployment, allowing for improvements in convergence speed, cumulative regret and average navigation cost. With only limited prior knowledge about the nature of unseen environments, we achieve at least 67% and as much as 96% improvements on cumulative regret over the baseline bandit approach in our experiments in simulated maze and office-like environments.
Motion Primitives based Path Planning with Rapidly-exploring Random Tree
Oct 27, 2022We present an approach that generates kinodynamically feasible paths for robots using Rapidly-exploring Random Tree (RRT). We leverage motion primitives as a way to capture the dynamics of the robot and use these motion primitives to build branches of the tree with RRT. Since every branch is built using the robot's motion primitives that doesn't lead to collision with obstacles, the resulting path is guaranteed to satisfy the robot's kinodynamic constraints and thus be feasible for navigation without any post-processing on the generated trajectory. We demonstrate the effectiveness of our approach in simulated 2D environments using simple robot models with a variety of motion primitives.
Learning for Robot Decision Making under Distribution Shift: A Survey
Mar 14, 2022

With the recent advances in the field of deep learning, learning-based methods are widely being implemented in various robotic systems that help robots understand their environment and make informed decisions to achieve a wide variety of tasks or goals. However, learning-based methods have repeatedly been shown to have poor generalization when they are presented with inputs that are different from those during training leading to the problem of distribution shift. Any robotic system that employs learning-based methods is prone to distribution shift which might lead the agents to make decisions that lead to degraded performance or even catastrophic failure. In this paper, we discuss various techniques that have been proposed in the literature to aid or improve decision making under distribution shift for robotic systems. We present a taxonomy of existing literature and present a survey of existing approaches in the area based on this taxonomy. Finally, we also identify a few open problems in the area that could serve as future directions for research.
Sophisticated Students in Boston Mechanism and Gale-Shapley Algorithm for School Choice Problem
Aug 12, 2021


We present our experimental results of simulating the school choice problem which deals with the assignment of students to schools based on each group's complete preference list for the other group using two algorithms: Boston mechanism and student-proposing Gale-Shapley algorithm. We compare the effects of sophisticated students altering their preference lists with regards to these two algorithms. Our simulation results show that sophisticated students can benefit more in Boston mechanism compared to Gale-Shapley algorithm based on multiple evaluation metrics.
Room Classification on Floor Plan Graphs using Graph Neural Networks
Aug 12, 2021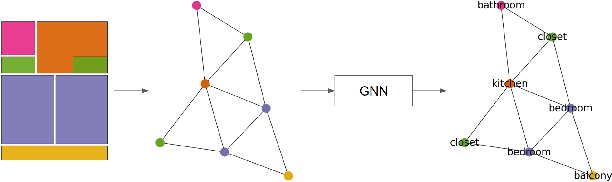
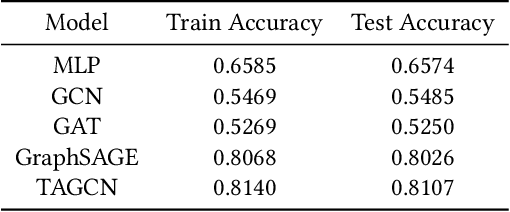
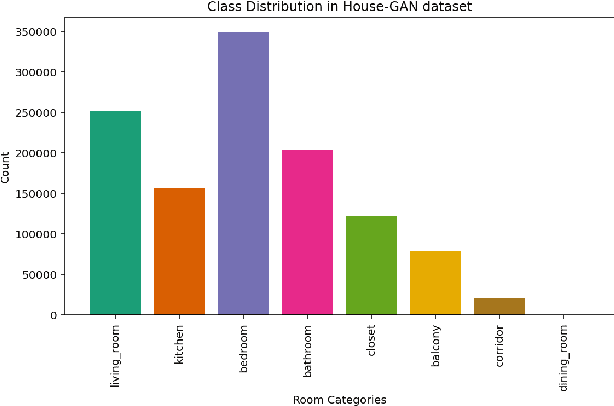
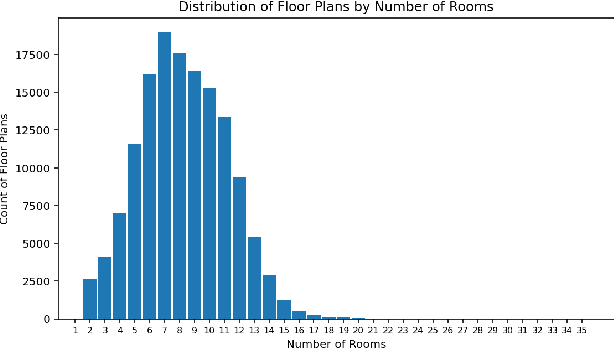
We present our approach to improve room classification task on floor plan maps of buildings by representing floor plans as undirected graphs and leveraging graph neural networks to predict the room categories. Rooms in the floor plans are represented as nodes in the graph with edges representing their adjacency in the map. We experiment with House-GAN dataset that consists of floor plan maps in vector format and train multilayer perceptron and graph neural networks. Our results show that graph neural networks, specifically GraphSAGE and Topology Adaptive GCN were able to achieve accuracy of 80% and 81% respectively outperforming baseline multilayer perceptron by more than 15% margin.