 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Contextual Information for Sentence-level Morpheme Segmentation
Mar 15, 2024Recent advancements in morpheme segmentation primarily emphasize word-level segmentation, often neglecting the contextual relevance within the sentence. In this study, we redefine the morpheme segmentation task as a sequence-to-sequence problem, treating the entire sentence as input rather than isolating individual words. Our findings reveal that the multilingual model consistently exhibits superior performance compared to monolingual counterparts. While our model did not surpass the performance of the current state-of-the-art, it demonstrated comparable efficacy with high-resource languages while revealing limitations in low-resource language scenarios.
Prompting in Autoregressive Large Language Models
Nov 28, 2023



Autoregressive Large Language Models have transformed the landscape of Natural Language Processing. Pre-train and prompt paradigm has replaced the conventional approach of pre-training and fine-tuning for many downstream NLP tasks. This shift has been possible largely due to LLMs and innovative prompting techniques. LLMs have shown great promise for a variety of downstream tasks owing to their vast parameters and huge datasets that they are pre-trained on. However, in order to fully realize their potential, their outputs must be guided towards the desired outcomes. Prompting, in which a specific input or instruction is provided to guide the LLMs toward the intended output, has become a tool for achieving this goal. In this paper, we discuss the various prompting techniques that have been applied to fully harness the power of LLMs. We present a taxonomy of existing literature on prompting techniques and provide a concise survey based on this taxonomy. Further, we identify some open problems in the realm of prompting in autoregressive LLMs which could serve as a direction for future research.
Are Large Language Models Geospatially Knowledgeable?
Oct 09, 2023Despite the impressive performance of Large Language Models (LLM) for various natural language processing tasks, little is known about their comprehension of geographic data and related ability to facilitate informed geospatial decision-making. This paper investigates the extent of geospatial knowledge, awareness, and reasoning abilities encoded within such pretrained LLMs. With a focus on autoregressive language models, we devise experimental approaches related to (i) probing LLMs for geo-coordinates to assess geospatial knowledge, (ii) using geospatial and non-geospatial prepositions to gauge their geospatial awareness, and (iii) utilizing a multidimensional scaling (MDS) experiment to assess the models' geospatial reasoning capabilities and to determine locations of cities based on prompting. Our results confirm that it does not only take larger, but also more sophisticated LLMs to synthesize geospatial knowledge from textual information. As such, this research contributes to understanding the potential and limitations of LLMs in dealing with geospatial information.
Trustworthiness of Children Stories Generated by Large Language Models
Jul 25, 2023Large Language Models (LLMs) have shown a tremendous capacity for generating literary text. However, their effectiveness in generating children's stories has yet to be thoroughly examined. In this study, we evaluate the trustworthiness of children's stories generated by LLMs using various measures, and we compare and contrast our results with both old and new children's stories to better assess their significance. Our findings suggest that LLMs still struggle to generate children's stories at the level of quality and nuance found in actual stories
Estimation of Vehicular Velocity based on Non-Intrusive stereo camera
Apr 11, 2023
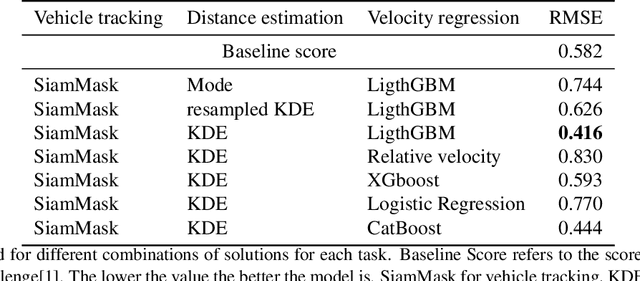

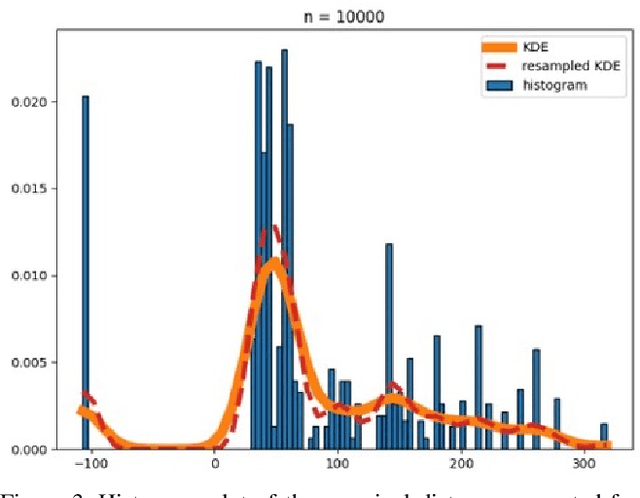
The paper presents a modular approach for the estimation of a leading vehicle's velocity based on a non-intrusive stereo camera where SiamMask is used for leading vehicle tracking, Kernel Density estimate (KDE) is used to smooth the distance prediction from a disparity map, and LightGBM is used for leading vehicle velocity estimation. Our approach yields an RMSE of 0.416 which outperforms the baseline RMSE of 0.582 for the SUBARU Image Recognition Challenge