 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Model-Free and Model-Based Learning-Informed Planning for PointGoal Navigation
Paper and Code
Dec 17, 2022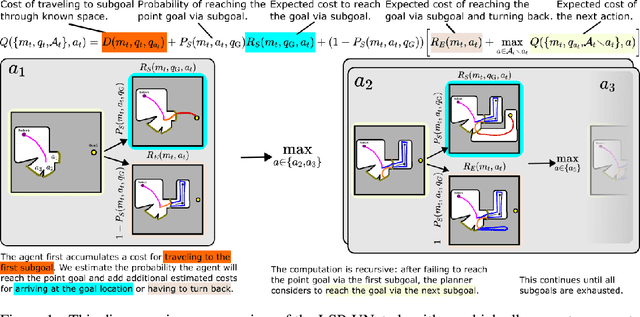


In recent years several learning approaches to point goal navigation in previously unseen environments have been proposed. They vary in the representations of the environments, problem decomposition, and experimental evaluation. In this work, we compare the state-of-the-art Deep Reinforcement Learning based approaches with Partially Observable Markov Decision Process (POMDP) formulation of the point goal navigation problem. We adapt the (POMDP) sub-goal framework proposed by [1] and modify the component that estimates frontier properties by using partial semantic maps of indoor scenes built from images' semantic segmentation. In addition to the well-known completeness of the model-based approach, we demonstrate that it is robust and efficient in that it leverages informative, learned properties of the frontiers compared to an optimistic frontier-based planner. We also demonstrate its data efficiency compared to the end-to-end deep reinforcement learning approaches. We compare our results against an optimistic planner, ANS and DD-PPO on Matterport3D dataset using the Habitat Simulator. We show comparable, though slightly worse performance than the SOTA DD-PPO approach, yet with far fewer data.