 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipatory Planning for Performant Long-Lived Robot in Large-Scale Home-Like Environments
Nov 19, 2024We consider the setting where a robot must complete a sequence of tasks in a persistent large-scale environment, given one at a time. Existing task planners often operate myopically, focusing solely on immediate goals without considering the impact of current actions on future tasks. Anticipatory planning, which reduces the joint objective of the immediate planning cost of the current task and the expected cost associated with future subsequent tasks, offers an approach for improving long-lived task planning. However, applying anticipatory planning in large-scale environments presents significant challenges due to the sheer number of assets involved, which strains the scalability of learning and planning. In this research, we introduce a model-based anticipatory task planning framework designed to scale to large-scale realistic environments. Our framework uses a GNN in particular via a representation inspired by a 3D Scene Graph to learn the essential properties of the environment crucial to estimating the state's expected cost and a sampling-based procedure for practical large-scale anticipatory planning. Our experimental results show that our planner reduces the cost of task sequence by 5.38% in home and 31.5% in restaurant settings. If given time to prepare in advance using our model reduces task sequence costs by 40.6% and 42.5%, respectively.
Active Information Gathering for Long-Horizon Navigation Under Uncertainty by Learning the Value of Information
Mar 05, 2024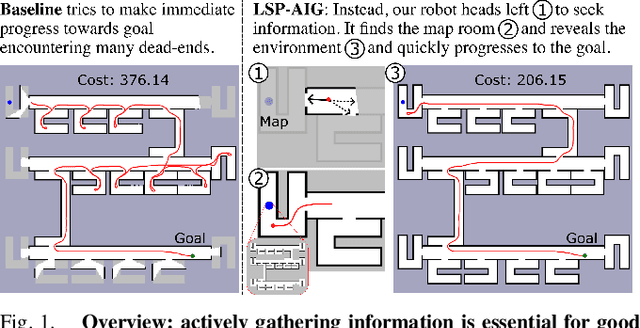

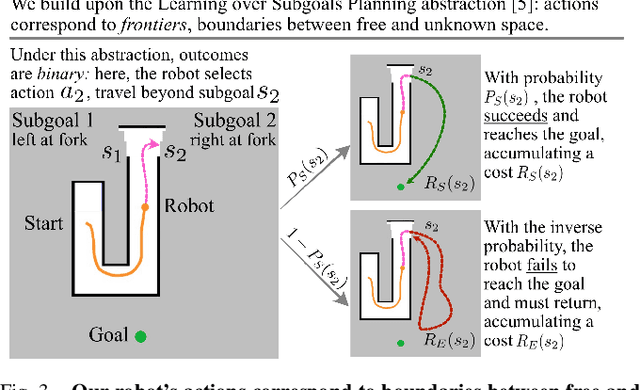
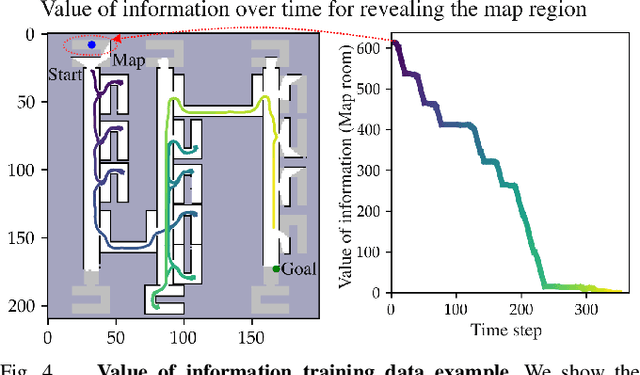
We address the task of long-horizon navigation in partially mapped environments for which active gathering of information about faraway unseen space is essential for good behavior. We present a novel planning strategy that, at training time, affords tractable computation of the value of information associated with revealing potentially informative regions of unseen space, data used to train a graph neural network to predict the goodness of temporally-extended exploratory actions. Our learning-augmented model-based planning approach predicts the expected value of information of revealing unseen space and is capable of using these predictions to actively seek information and so improve long-horizon navigation. Across two simulated office-like environments, our planner outperforms competitive learned and non-learned baseline navigation strategies, achieving improvements of up to 63.76% and 36.68%, demonstrating its capacity to actively seek performance-critical information.
Improving Reliable Navigation under Uncertainty via Predictions Informed by Non-Local Information
Jul 26, 2023We improve reliable, long-horizon, goal-directed navigation in partially-mapped environments by using non-locally available information to predict the goodness of temporally-extended actions that enter unseen space. Making predictions about where to navigate in general requires non-local information: any observations the robot has seen so far may provide information about the goodness of a particular direction of travel. Building on recent work in learning-augmented model-based planning under uncertainty, we present an approach that can both rely on non-local information to make predictions (via a graph neural network) and is reliable by design: it will always reach its goal, even when learning does not provide accurate predictions. We conduct experiments in three simulated environments in which non-local information is needed to perform well. In our large scale university building environment, generated from real-world floorplans to the scale, we demonstrate a 9.3\% reduction in cost-to-go compared to a non-learned baseline and a 14.9\% reduction compared to a learning-informed planner that can only use local information to inform its predictions.
Code to Comment Translation: A Comparative Study on Model Effectiveness & Errors
Jun 15, 2021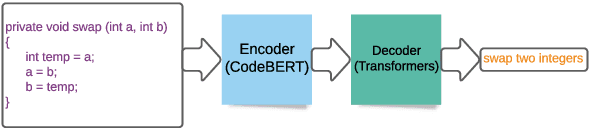
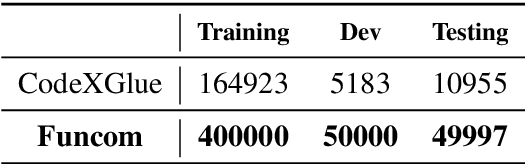


Automated source code summarization is a popular software engineering research topic wherein machine translation models are employed to "translate" code snippets into relevant natural language descriptions. Most evaluations of such models are conducted using automatic reference-based metrics. However, given the relatively large semantic gap between programming languages and natural language, we argue that this line of research would benefit from a qualitative investigation into the various error modes of current state-of-the-art models. Therefore, in this work, we perform both a quantitative and qualitative comparison of three recently proposed source code summarization models. In our quantitative evaluation, we compare the models based on the smoothed BLEU-4, METEOR, and ROUGE-L machine translation metrics, and in our qualitative evaluation, we perform a manual open-coding of the most common errors committed by the models when compared to ground truth captions. Our investigation reveals new insights into the relationship between metric-based performance and model prediction errors grounded in an empirically derived error taxonomy that can be used to drive future research efforts