 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Language and App UI Analysis for the Automated Assessment of Bug Reproduction Steps
Feb 06, 2025



Bug reports are essential for developers to confirm software problems, investigate their causes, and validate fixes. Unfortunately, reports often miss important information or are written unclearly, which can cause delays, increased issue resolution effort, or even the inability to solve issues. One of the most common components of reports that are problematic is the steps to reproduce the bug(s) (S2Rs), which are essential to replicate the described program failures and reason about fixes. Given the proclivity for deficiencies in reported S2Rs, prior work has proposed techniques that assist reporters in writing or assessing the quality of S2Rs. However, automated understanding of S2Rs is challenging, and requires linking nuanced natural language phrases with specific, semantically related program information. Prior techniques often struggle to form such language to program connections - due to issues in language variability and limitations of information gleaned from program analyses. To more effectively tackle the problem of S2R quality annotation, we propose a new technique called AstroBR, which leverages the language understanding capabilities of LLMs to identify and extract the S2Rs from bug reports and map them to GUI interactions in a program state model derived via dynamic analysis. We compared AstroBR to a related state-of-the-art approach and we found that AstroBR annotates S2Rs 25.2% better (in terms of F1 score) than the baseline. Additionally, AstroBR suggests more accurate missing S2Rs than the baseline (by 71.4% in terms of F1 score).
Toward Rapid Bug Resolution for Android Apps
Dec 23, 2023Bug reports document unexpected behaviors in software, enabling developers to understand, validate, and fix bugs. Unfortunately, a significant portion of bug reports is of low quality, which poses challenges for developers in terms of addressing these issues. Prior research has delved into the information needed for documenting high-quality bug reports and expediting bug report management. Furthermore, researchers have explored the challenges associated with bug report management and proposed various automated techniques. Nevertheless, these techniques exhibit several limitations, including a lexical gap between developers and reporters, difficulties in bug reproduction, and identifying bug locations. Therefore, there is a pressing need for additional efforts to effectively manage bug reports and enhance the quality of both desktop and mobile applications. In this paper, we describe the existing limitations of bug reports and identify potential strategies for addressing them. Our vision encompasses a future where the alleviation of these limitations and successful execution of our proposed new research directions can benefit both reporters and developers, ultimately making the entire software maintenance faster.
On Using GUI Interaction Data to Improve Text Retrieval-based Bug Localization
Oct 12, 2023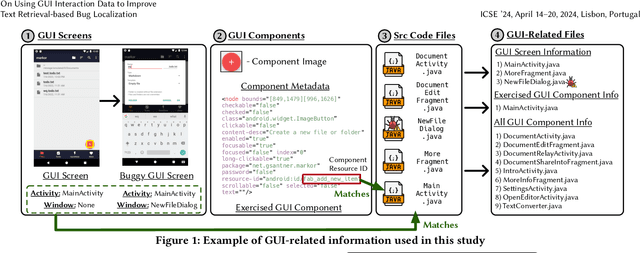



One of the most important tasks related to managing bug reports is localizing the fault so that a fix can be applied. As such, prior work has aimed to automate this task of bug localization by formulating it as an information retrieval problem, where potentially buggy files are retrieved and ranked according to their textual similarity with a given bug report. However, there is often a notable semantic gap between the information contained in bug reports and identifiers or natural language contained within source code files. For user-facing software, there is currently a key source of information that could aid in bug localization, but has not been thoroughly investigated - information from the GUI. We investigate the hypothesis that, for end user-facing applications, connecting information in a bug report with information from the GUI, and using this to aid in retrieving potentially buggy files, can improve upon existing techniques for bug localization. To examine this phenomenon, we conduct a comprehensive empirical study that augments four baseline techniques for bug localization with GUI interaction information from a reproduction scenario to (i) filter out potentially irrelevant files, (ii) boost potentially relevant files, and (iii) reformulate text-retrieval queries. To carry out our study, we source the current largest dataset of fully-localized and reproducible real bugs for Android apps, with corresponding bug reports, consisting of 80 bug reports from 39 popular open-source apps. Our results illustrate that augmenting traditional techniques with GUI information leads to a marked increase in effectiveness across multiple metrics, including a relative increase in Hits@10 of 13-18%. Additionally, through further analysis, we find that our studied augmentations largely complement existing techniques.
An Empirical Investigation into the Use of Image Captioning for Automated Software Documentation
Jan 03, 2023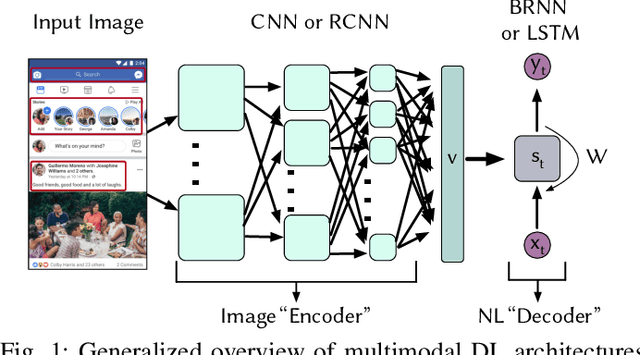
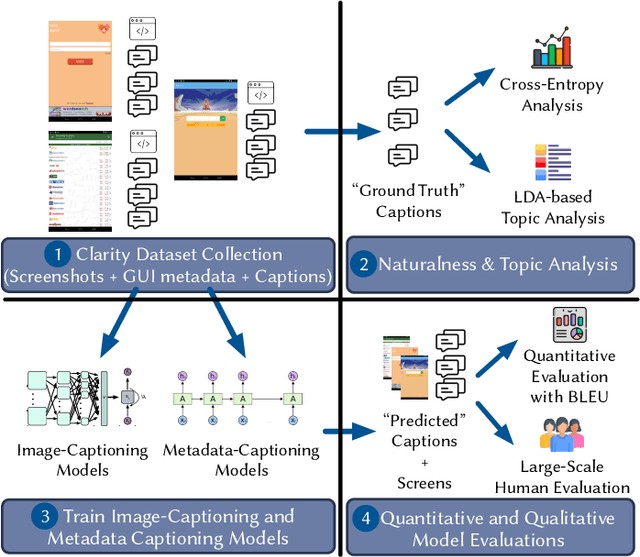
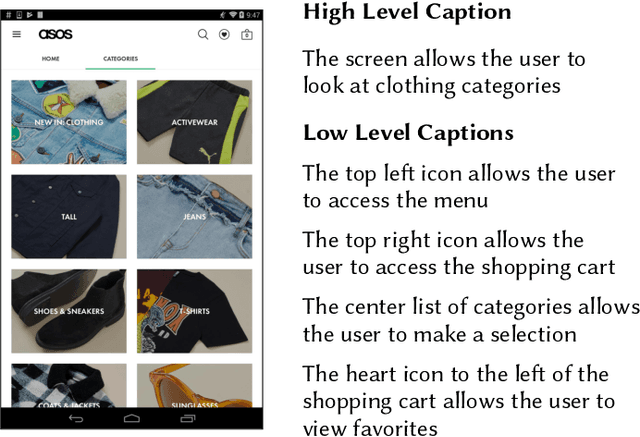
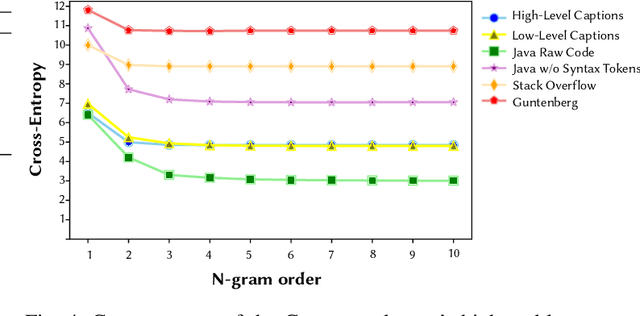
Existing automated techniques for software documentation typically attempt to reason between two main sources of information: code and natural language. However, this reasoning process is often complicated by the lexical gap between more abstract natural language and more structured programming languages. One potential bridge for this gap is the Graphical User Interface (GUI), as GUIs inherently encode salient information about underlying program functionality into rich, pixel-based data representations. This paper offers one of the first comprehensive empirical investigations into the connection between GUIs and functional, natural language descriptions of software. First, we collect, analyze, and open source a large dataset of functional GUI descriptions consisting of 45,998 descriptions for 10,204 screenshots from popular Android applications. The descriptions were obtained from human labelers and underwent several quality control mechanisms. To gain insight into the representational potential of GUIs, we investigate the ability of four Neural Image Captioning models to predict natural language descriptions of varying granularity when provided a screenshot as input. We evaluate these models quantitatively, using common machine translation metrics, and qualitatively through a large-scale user study. Finally, we offer learned lessons and a discussion of the potential shown by multimodal models to enhance future techniques for automated software documentation.
Code to Comment Translation: A Comparative Study on Model Effectiveness & Errors
Jun 15, 2021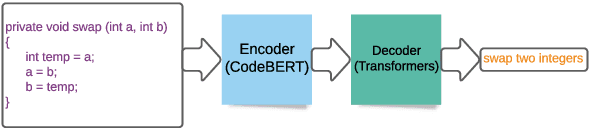
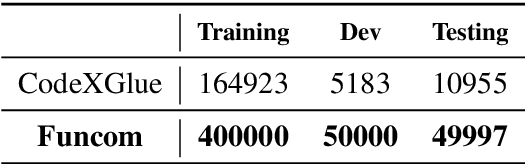


Automated source code summarization is a popular software engineering research topic wherein machine translation models are employed to "translate" code snippets into relevant natural language descriptions. Most evaluations of such models are conducted using automatic reference-based metrics. However, given the relatively large semantic gap between programming languages and natural language, we argue that this line of research would benefit from a qualitative investigation into the various error modes of current state-of-the-art models. Therefore, in this work, we perform both a quantitative and qualitative comparison of three recently proposed source code summarization models. In our quantitative evaluation, we compare the models based on the smoothed BLEU-4, METEOR, and ROUGE-L machine translation metrics, and in our qualitative evaluation, we perform a manual open-coding of the most common errors committed by the models when compared to ground truth captions. Our investigation reveals new insights into the relationship between metric-based performance and model prediction errors grounded in an empirically derived error taxonomy that can be used to drive future research efforts