 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURORA: Navigating UI Tarpits via Automated Neural Screen Understanding
Apr 01, 2024Nearly a decade of research in software engineering has focused on automating mobile app testing to help engineers in overcoming the unique challenges associated with the software platform. Much of this work has come in the form of Automated Input Generation tools (AIG tools) that dynamically explore app screens. However, such tools have repeatedly been demonstrated to achieve lower-than-expected code coverage - particularly on sophisticated proprietary apps. Prior work has illustrated that a primary cause of these coverage deficiencies is related to so-called tarpits, or complex screens that are difficult to navigate. In this paper, we take a critical step toward enabling AIG tools to effectively navigate tarpits during app exploration through a new form of automated semantic screen understanding. We introduce AURORA, a technique that learns from the visual and textual patterns that exist in mobile app UIs to automatically detect common screen designs and navigate them accordingly. The key idea of AURORA is that there are a finite number of mobile app screen designs, albeit with subtle variations, such that the general patterns of different categories of UI designs can be learned. As such, AURORA employs a multi-modal, neural screen classifier that is able to recognize the most common types of UI screen designs. After recognizing a given screen, it then applies a set of flexible and generalizable heuristics to properly navigate the screen. We evaluated AURORA both on a set of 12 apps with known tarpits from prior work, and on a new set of five of the most popular apps from the Google Play store. Our results indicate that AURORA is able to effectively navigate tarpit screens, outperforming prior approaches that avoid tarpits by 19.6% in terms of method coverage. The improvements can be attributed to AURORA's UI design classification and heuristic navigation techniques.
On Using GUI Interaction Data to Improve Text Retrieval-based Bug Localization
Oct 12, 2023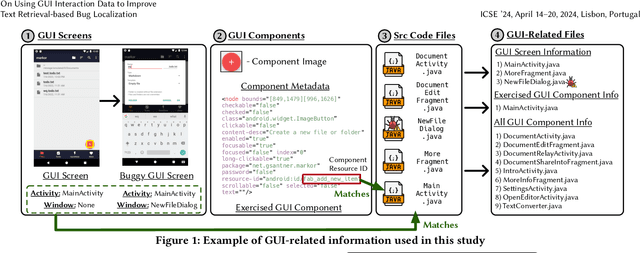



One of the most important tasks related to managing bug reports is localizing the fault so that a fix can be applied. As such, prior work has aimed to automate this task of bug localization by formulating it as an information retrieval problem, where potentially buggy files are retrieved and ranked according to their textual similarity with a given bug report. However, there is often a notable semantic gap between the information contained in bug reports and identifiers or natural language contained within source code files. For user-facing software, there is currently a key source of information that could aid in bug localization, but has not been thoroughly investigated - information from the GUI. We investigate the hypothesis that, for end user-facing applications, connecting information in a bug report with information from the GUI, and using this to aid in retrieving potentially buggy files, can improve upon existing techniques for bug localization. To examine this phenomenon, we conduct a comprehensive empirical study that augments four baseline techniques for bug localization with GUI interaction information from a reproduction scenario to (i) filter out potentially irrelevant files, (ii) boost potentially relevant files, and (iii) reformulate text-retrieval queries. To carry out our study, we source the current largest dataset of fully-localized and reproducible real bugs for Android apps, with corresponding bug reports, consisting of 80 bug reports from 39 popular open-source apps. Our results illustrate that augmenting traditional techniques with GUI information leads to a marked increase in effectiveness across multiple metrics, including a relative increase in Hits@10 of 13-18%. Additionally, through further analysis, we find that our studied augmentations largely complement existing techniques.