 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Language and App UI Analysis for the Automated Assessment of Bug Reproduction Steps
Feb 06, 2025



Bug reports are essential for developers to confirm software problems, investigate their causes, and validate fixes. Unfortunately, reports often miss important information or are written unclearly, which can cause delays, increased issue resolution effort, or even the inability to solve issues. One of the most common components of reports that are problematic is the steps to reproduce the bug(s) (S2Rs), which are essential to replicate the described program failures and reason about fixes. Given the proclivity for deficiencies in reported S2Rs, prior work has proposed techniques that assist reporters in writing or assessing the quality of S2Rs. However, automated understanding of S2Rs is challenging, and requires linking nuanced natural language phrases with specific, semantically related program information. Prior techniques often struggle to form such language to program connections - due to issues in language variability and limitations of information gleaned from program analyses. To more effectively tackle the problem of S2R quality annotation, we propose a new technique called AstroBR, which leverages the language understanding capabilities of LLMs to identify and extract the S2Rs from bug reports and map them to GUI interactions in a program state model derived via dynamic analysis. We compared AstroBR to a related state-of-the-art approach and we found that AstroBR annotates S2Rs 25.2% better (in terms of F1 score) than the baseline. Additionally, AstroBR suggests more accurate missing S2Rs than the baseline (by 71.4% in terms of F1 score).
On Using GUI Interaction Data to Improve Text Retrieval-based Bug Localization
Oct 12, 2023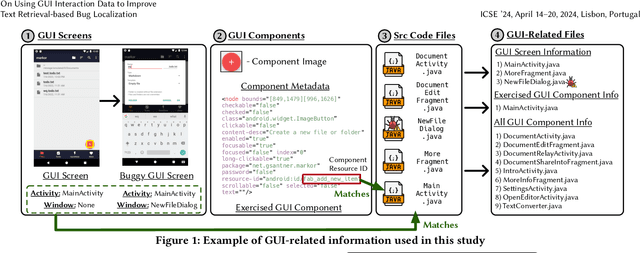



One of the most important tasks related to managing bug reports is localizing the fault so that a fix can be applied. As such, prior work has aimed to automate this task of bug localization by formulating it as an information retrieval problem, where potentially buggy files are retrieved and ranked according to their textual similarity with a given bug report. However, there is often a notable semantic gap between the information contained in bug reports and identifiers or natural language contained within source code files. For user-facing software, there is currently a key source of information that could aid in bug localization, but has not been thoroughly investigated - information from the GUI. We investigate the hypothesis that, for end user-facing applications, connecting information in a bug report with information from the GUI, and using this to aid in retrieving potentially buggy files, can improve upon existing techniques for bug localization. To examine this phenomenon, we conduct a comprehensive empirical study that augments four baseline techniques for bug localization with GUI interaction information from a reproduction scenario to (i) filter out potentially irrelevant files, (ii) boost potentially relevant files, and (iii) reformulate text-retrieval queries. To carry out our study, we source the current largest dataset of fully-localized and reproducible real bugs for Android apps, with corresponding bug reports, consisting of 80 bug reports from 39 popular open-source apps. Our results illustrate that augmenting traditional techniques with GUI information leads to a marked increase in effectiveness across multiple metrics, including a relative increase in Hits@10 of 13-18%. Additionally, through further analysis, we find that our studied augmentations largely complement existing techniques.
Translating Video Recordings of Mobile App Usages into Replayable Scenarios
May 18, 2020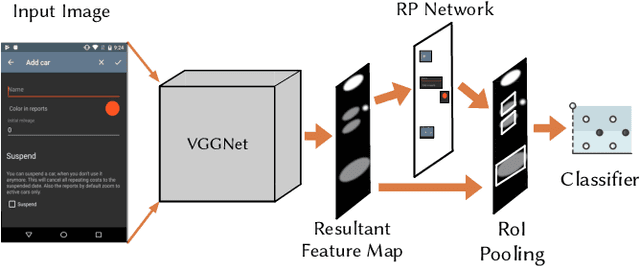
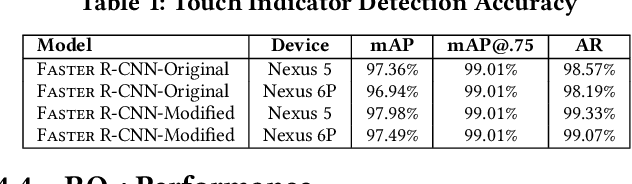


Screen recordings of mobile applications are easy to obtain and capture a wealth of information pertinent to software developers (e.g., bugs or feature requests), making them a popular mechanism for crowdsourced app feedback. Thus, these videos are becoming a common artifact that developers must manage. In light of unique mobile development constraints, including swift release cycles and rapidly evolving platforms, automated techniques for analyzing all types of rich software artifacts provide benefit to mobile developers. Unfortunately, automatically analyzing screen recordings presents serious challenges, due to their graphical nature, compared to other types of (textual) artifacts. To address these challenges, this paper introduces V2S, a lightweight, automated approach for translating video recordings of Android app usages into replayable scenarios. V2S is based primarily on computer vision techniques and adapts recent solutions for object detection and image classification to detect and classify user actions captured in a video, and convert these into a replayable test scenario. We performed an extensive evaluation of V2S involving 175 videos depicting 3,534 GUI-based actions collected from users exercising features and reproducing bugs from over 80 popular Android apps. Our results illustrate that V2S can accurately replay scenarios from screen recordings, and is capable of reproducing $\approx$ 89% of our collected videos with minimal overhead. A case study with three industrial partners illustrates the potential usefulness of V2S from the viewpoint of developers.