 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation into the Use of Image Captioning for Automated Software Documentation
Jan 03, 2023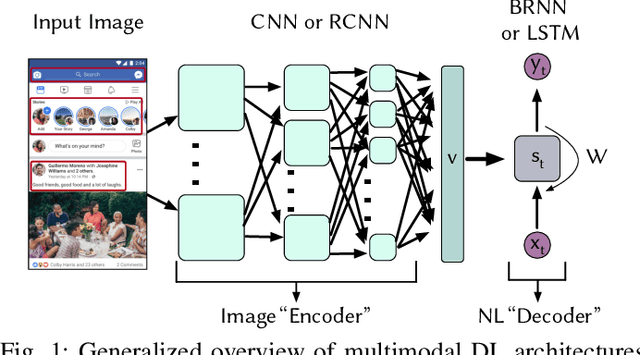
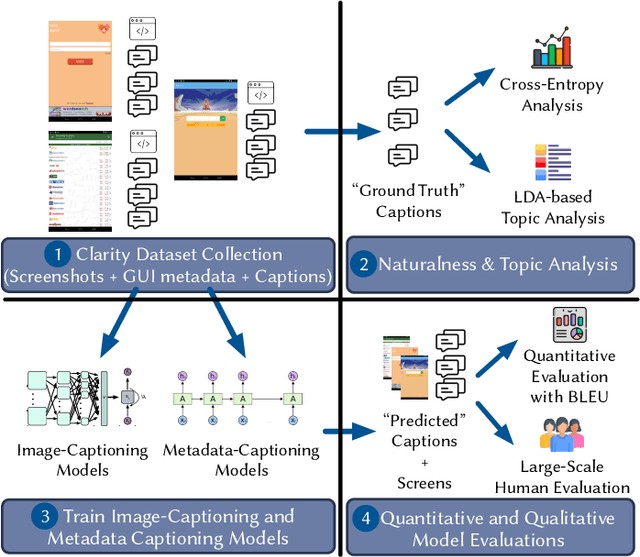
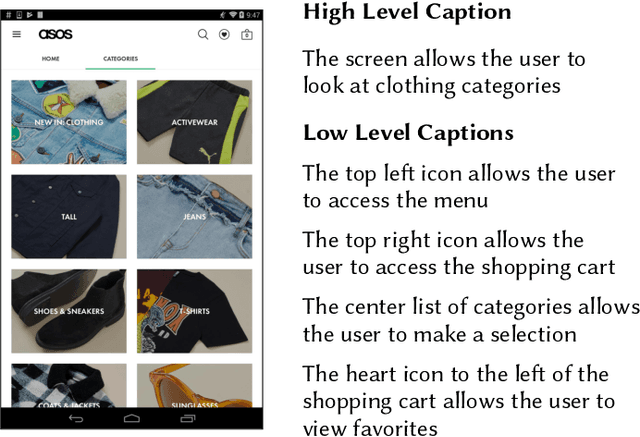
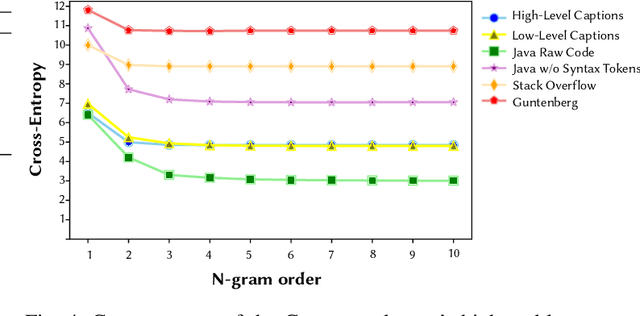
Existing automated techniques for software documentation typically attempt to reason between two main sources of information: code and natural language. However, this reasoning process is often complicated by the lexical gap between more abstract natural language and more structured programming languages. One potential bridge for this gap is the Graphical User Interface (GUI), as GUIs inherently encode salient information about underlying program functionality into rich, pixel-based data representations. This paper offers one of the first comprehensive empirical investigations into the connection between GUIs and functional, natural language descriptions of software. First, we collect, analyze, and open source a large dataset of functional GUI descriptions consisting of 45,998 descriptions for 10,204 screenshots from popular Android applications. The descriptions were obtained from human labelers and underwent several quality control mechanisms. To gain insight into the representational potential of GUIs, we investigate the ability of four Neural Image Captioning models to predict natural language descriptions of varying granularity when provided a screenshot as input. We evaluate these models quantitatively, using common machine translation metrics, and qualitatively through a large-scale user study. Finally, we offer learned lessons and a discussion of the potential shown by multimodal models to enhance future techniques for automated software documentation.
It Takes Two to Tango: Combining Visual and Textual Information for Detecting Duplicate Video-Based Bug Reports
Feb 05, 2021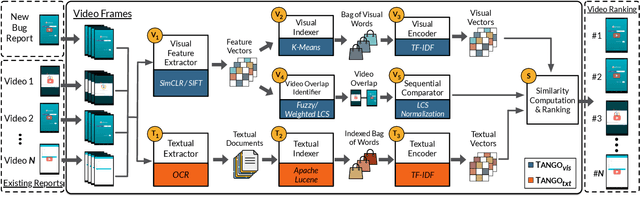
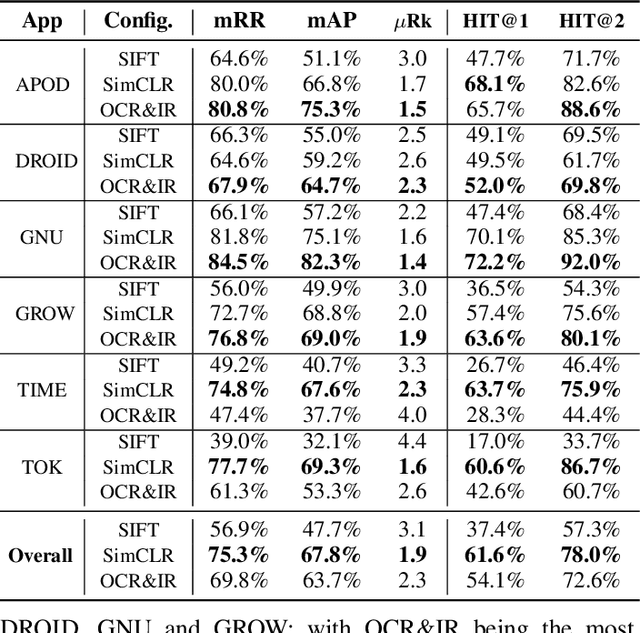

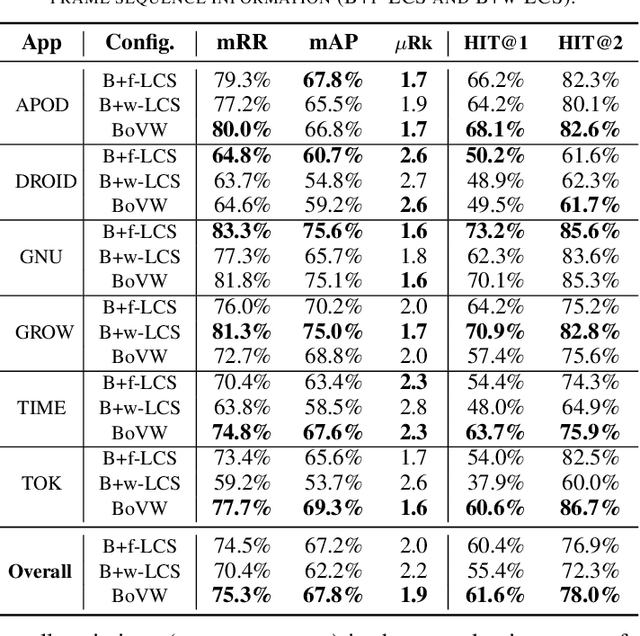
When a bug manifests in a user-facing application, it is likely to be exposed through the graphical user interface (GUI). Given the importance of visual information to the process of identifying and understanding such bugs, users are increasingly making use of screenshots and screen-recordings as a means to report issues to developers. However, when such information is reported en masse, such as during crowd-sourced testing, managing these artifacts can be a time-consuming process. As the reporting of screen-recordings in particular becomes more popular, developers are likely to face challenges related to manually identifying videos that depict duplicate bugs. Due to their graphical nature, screen-recordings present challenges for automated analysis that preclude the use of current duplicate bug report detection techniques. To overcome these challenges and aid developers in this task, this paper presents Tango, a duplicate detection technique that operates purely on video-based bug reports by leveraging both visual and textual information. Tango combines tailored computer vision techniques, optical character recognition, and text retrieval. We evaluated multiple configurations of Tango in a comprehensive empirical evaluation on 4,860 duplicate detection tasks that involved a total of 180 screen-recordings from six Android apps. Additionally, we conducted a user study investigating the effort required for developers to manually detect duplicate video-based bug reports and compared this to the effort required to use Tango. The results reveal that Tango's optimal configuration is highly effective at detecting duplicate video-based bug reports, accurately ranking target duplicate videos in the top-2 returned results in 83% of the tasks. Additionally, our user study shows that, on average, Tango can reduce developer effort by over 60%, illustrating its practicality.
Translating Video Recordings of Mobile App Usages into Replayable Scenarios
May 18, 2020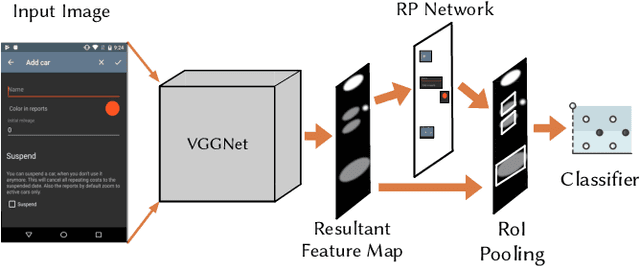
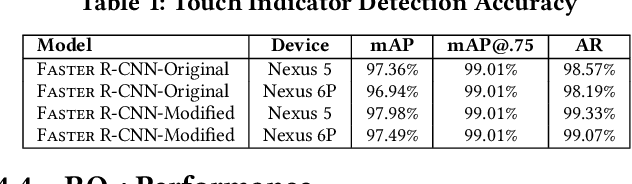


Screen recordings of mobile applications are easy to obtain and capture a wealth of information pertinent to software developers (e.g., bugs or feature requests), making them a popular mechanism for crowdsourced app feedback. Thus, these videos are becoming a common artifact that developers must manage. In light of unique mobile development constraints, including swift release cycles and rapidly evolving platforms, automated techniques for analyzing all types of rich software artifacts provide benefit to mobile developers. Unfortunately, automatically analyzing screen recordings presents serious challenges, due to their graphical nature, compared to other types of (textual) artifacts. To address these challenges, this paper introduces V2S, a lightweight, automated approach for translating video recordings of Android app usages into replayable scenarios. V2S is based primarily on computer vision techniques and adapts recent solutions for object detection and image classification to detect and classify user actions captured in a video, and convert these into a replayable test scenario. We performed an extensive evaluation of V2S involving 175 videos depicting 3,534 GUI-based actions collected from users exercising features and reproducing bugs from over 80 popular Android apps. Our results illustrate that V2S can accurately replay scenarios from screen recordings, and is capable of reproducing $\approx$ 89% of our collected videos with minimal overhead. A case study with three industrial partners illustrates the potential usefulness of V2S from the viewpoint of developers.
Improving the Effectiveness of Traceability Link Recovery using Hierarchical Bayesian Networks
May 18, 2020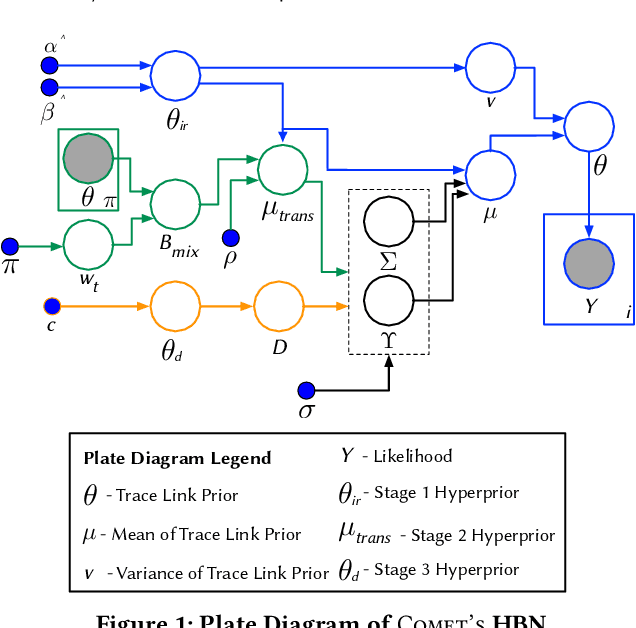
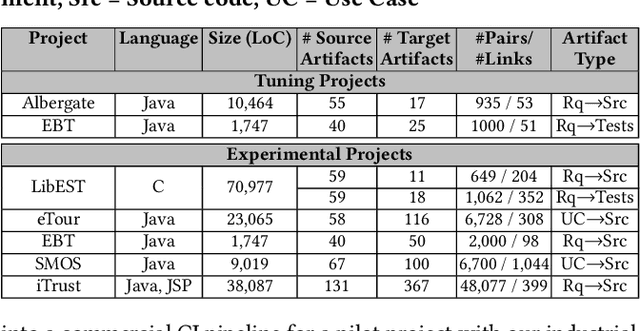
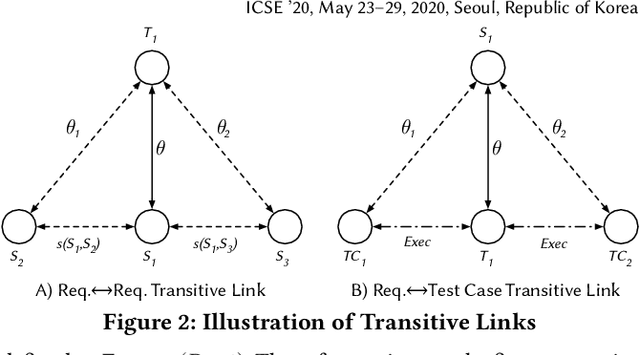
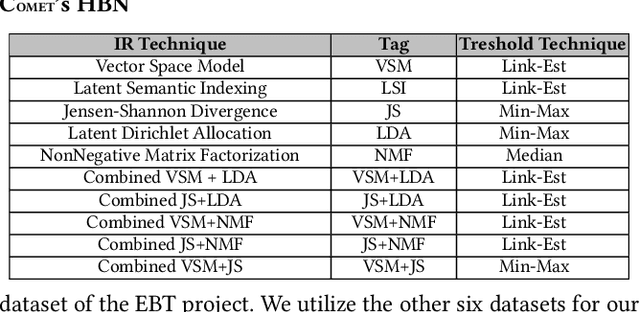
Traceability is a fundamental component of the modern software development process that helps to ensure properly functioning, secure programs. Due to the high cost of manually establishing trace links, researchers have developed automated approaches that draw relationships between pairs of textual software artifacts using similarity measures. However, the effectiveness of such techniques are often limited as they only utilize a single measure of artifact similarity and cannot simultaneously model (implicit and explicit) relationships across groups of diverse development artifacts. In this paper, we illustrate how these limitations can be overcome through the use of a tailored probabilistic model. To this end, we design and implement a HierarchiCal PrObabilistic Model for SoftwarE Traceability (Comet) that is able to infer candidate trace links. Comet is capable of modeling relationships between artifacts by combining the complementary observational prowess of multiple measures of textual similarity. Additionally, our model can holistically incorporate information from a diverse set of sources, including developer feedback and transitive (often implicit) relationships among groups of software artifacts, to improve inference accuracy. We conduct a comprehensive empirical evaluation of Comet that illustrates an improvement over a set of optimally configured baselines of $\approx$14% in the best case and $\approx$5% across all subjects in terms of average precision. The comparative effectiveness of Comet in practice, where optimal configuration is typically not possible, is likely to be higher. Finally, we illustrate Comets potential for practical applicability in a survey with developers from Cisco Systems who used a prototype Comet Jenkins plugin.
Machine Learning-Based Prototyping of Graphical User Interfaces for Mobile Apps
Jun 05, 2018
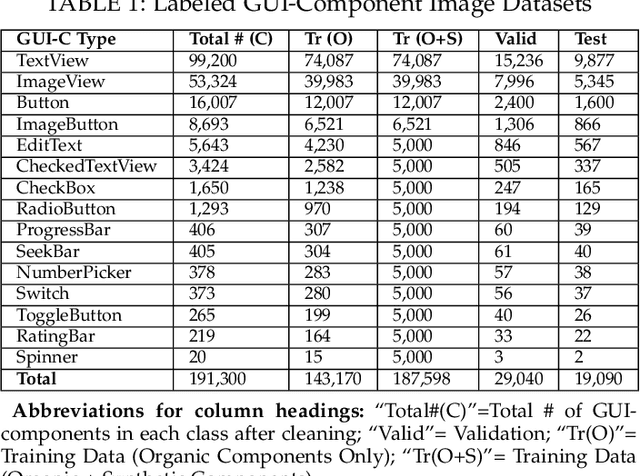
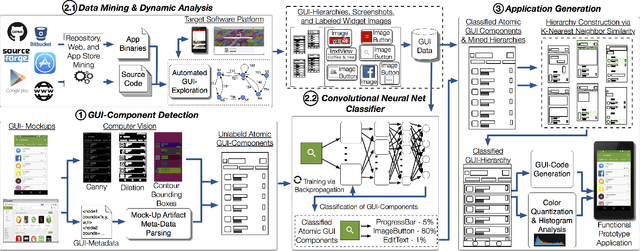

It is common practice for developers of user-facing software to transform a mock-up of a graphical user interface (GUI) into code. This process takes place both at an application's inception and in an evolutionary context as GUI changes keep pace with evolving features. Unfortunately, this practice is challenging and time-consuming. In this paper, we present an approach that automates this process by enabling accurate prototyping of GUIs via three tasks: detection, classification, and assembly. First, logical components of a GUI are detected from a mock-up artifact using either computer vision techniques or mock-up metadata. Then, software repository mining, automated dynamic analysis, and deep convolutional neural networks are utilized to accurately classify GUI-components into domain-specific types (e.g., toggle-button). Finally, a data-driven, K-nearest-neighbors algorithm generates a suitable hierarchical GUI structure from which a prototype application can be automatically assembled. We implemented this approach for Android in a system called ReDraw. Our evaluation illustrates that ReDraw achieves an average GUI-component classification accuracy of 91% and assembles prototype applications that closely mirror target mock-ups in terms of visual affinity while exhibiting reasonable code structure. Interviews with industrial practitioners illustrate ReDraw's potential to improve real development workflows.