 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Flash Attention Stable?
May 05, 2024



Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
The Faiss library
Jan 16, 2024
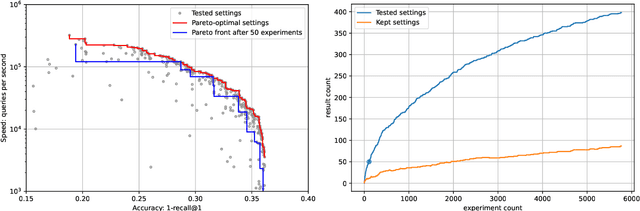

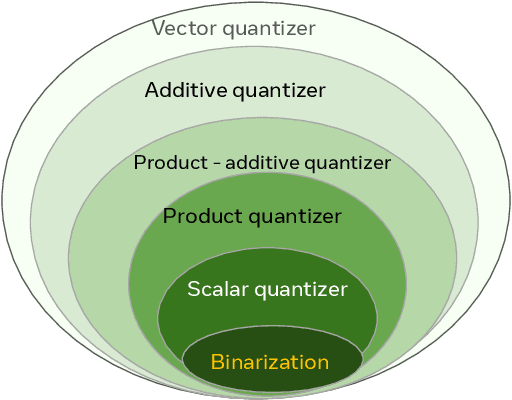
Vector databases manage large collections of embedding vectors. As AI applications are growing rapidly, so are the number of embeddings that need to be stored and indexed. The Faiss library is dedicated to vector similarity search, a core functionality of vector databases. Faiss is a toolkit of indexing methods and related primitives used to search, cluster, compress and transform vectors. This paper first describes the tradeoff space of vector search, then the design principles of Faiss in terms of structure, approach to optimization and interfacing. We benchmark key features of the library and discuss a few selected applications to highlight its broad applicability.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023



As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Improving the Effectiveness of Traceability Link Recovery using Hierarchical Bayesian Networks
May 18, 2020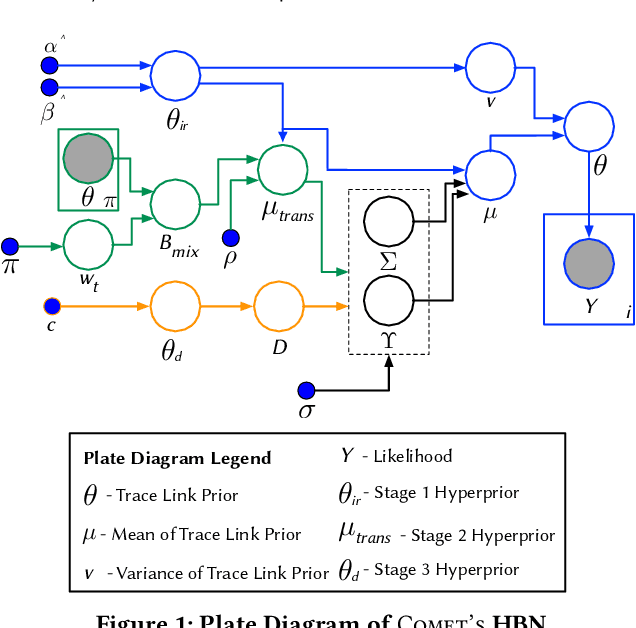
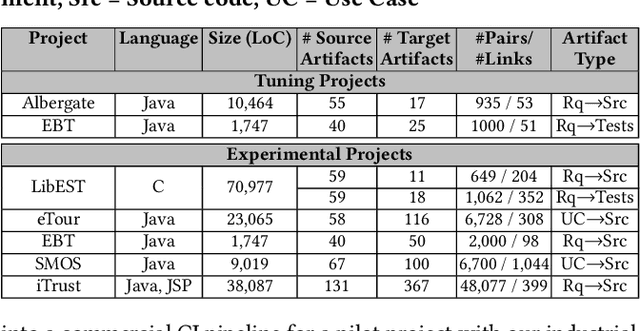
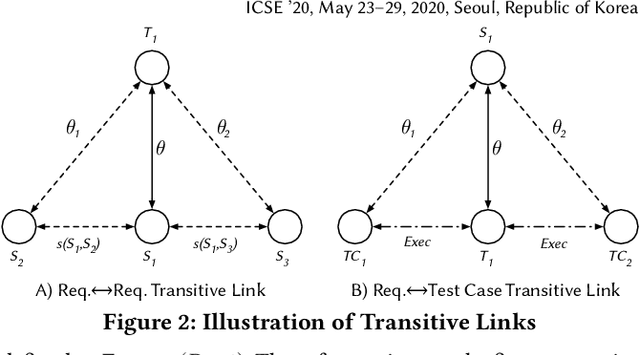
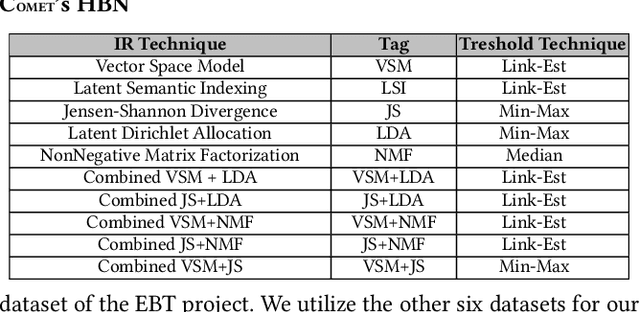
Traceability is a fundamental component of the modern software development process that helps to ensure properly functioning, secure programs. Due to the high cost of manually establishing trace links, researchers have developed automated approaches that draw relationships between pairs of textual software artifacts using similarity measures. However, the effectiveness of such techniques are often limited as they only utilize a single measure of artifact similarity and cannot simultaneously model (implicit and explicit) relationships across groups of diverse development artifacts. In this paper, we illustrate how these limitations can be overcome through the use of a tailored probabilistic model. To this end, we design and implement a HierarchiCal PrObabilistic Model for SoftwarE Traceability (Comet) that is able to infer candidate trace links. Comet is capable of modeling relationships between artifacts by combining the complementary observational prowess of multiple measures of textual similarity. Additionally, our model can holistically incorporate information from a diverse set of sources, including developer feedback and transitive (often implicit) relationships among groups of software artifacts, to improve inference accuracy. We conduct a comprehensive empirical evaluation of Comet that illustrates an improvement over a set of optimally configured baselines of $\approx$14% in the best case and $\approx$5% across all subjects in terms of average precision. The comparative effectiveness of Comet in practice, where optimal configuration is typically not possible, is likely to be higher. Finally, we illustrate Comets potential for practical applicability in a survey with developers from Cisco Systems who used a prototype Comet Jenkins plugin.
Rethinking floating point for deep learning
Nov 01, 2018


Reducing hardware overhead of neural networks for faster or lower power inference and training is an active area of research. Uniform quantization using integer multiply-add has been thoroughly investigated, which requires learning many quantization parameters, fine-tuning training or other prerequisites. Little effort is made to improve floating point relative to this baseline; it remains energy inefficient, and word size reduction yields drastic loss in needed dynamic range. We improve floating point to be more energy efficient than equivalent bit width integer hardware on a 28 nm ASIC process while retaining accuracy in 8 bits with a novel hybrid log multiply/linear add, Kulisch accumulation and tapered encodings from Gustafson's posit format. With no network retraining, and drop-in replacement of all math and float32 parameters via round-to-nearest-even only, this open-sourced 8-bit log float is within 0.9% top-1 and 0.2% top-5 accuracy of the original float32 ResNet-50 CNN model on ImageNet. Unlike int8 quantization, it is still a general purpose floating point arithmetic, interpretable out-of-the-box. Our 8/38-bit log float multiply-add is synthesized and power profiled at 28 nm at 0.96x the power and 1.12x the area of 8/32-bit integer multiply-add. In 16 bits, our log float multiply-add is 0.59x the power and 0.68x the area of IEEE 754 float16 fused multiply-add, maintaining the same signficand precision and dynamic range, proving useful for training ASICs as well.
An evaluation of large-scale methods for image instance and class discovery
Aug 09, 2017



This paper aims at discovering meaningful subsets of related images from large image collections without annotations. We search groups of images related at different levels of semantic, i.e., either instances or visual classes. While k-means is usually considered as the gold standard for this task, we evaluate and show the interest of diffusion methods that have been neglected by the state of the art, such as the Markov Clustering algorithm. We report results on the ImageNet and the Paris500k instance dataset, both enlarged with images from YFCC100M. We evaluate our methods with a labelling cost that reflects how much effort a human would require to correct the generated clusters. Our analysis highlights several properties. First, when powered with an efficient GPU implementation, the cost of the discovery process is small compared to computing the image descriptors, even for collections as large as 100 million images. Second, we show that descriptions selected for instance search improve the discovery of object classes. Third, the Markov Clustering technique consistently outperforms other methods; to our knowledge it has never been considered in this large scale scenario.
Billion-scale similarity search with GPUs
Feb 28, 2017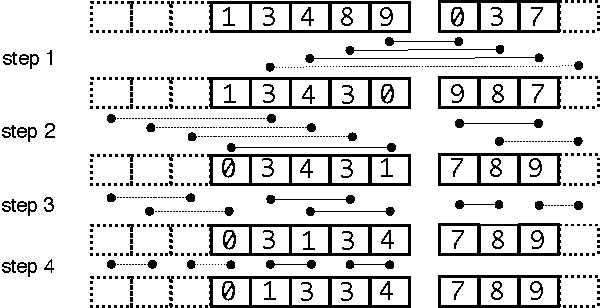



Similarity search finds application in specialized database systems handling complex data such as images or videos, which are typically represented by high-dimensional features and require specific indexing structures. This paper tackles the problem of better utilizing GPUs for this task. While GPUs excel at data-parallel tasks, prior approaches are bottlenecked by algorithms that expose less parallelism, such as k-min selection, or make poor use of the memory hierarchy. We propose a design for k-selection that operates at up to 55% of theoretical peak performance, enabling a nearest neighbor implementation that is 8.5x faster than prior GPU state of the art. We apply it in different similarity search scenarios, by proposing optimized design for brute-force, approximate and compressed-domain search based on product quantization. In all these setups, we outperform the state of the art by large margins. Our implementation enables the construction of a high accuracy k-NN graph on 95 million images from the Yfcc100M dataset in 35 minutes, and of a graph connecting 1 billion vectors in less than 12 hours on 4 Maxwell Titan X GPUs. We have open-sourced our approach for the sake of comparison and reproducibility.
Fast Convolutional Nets With fbfft: A GPU Performance Evaluation
Apr 10, 2015
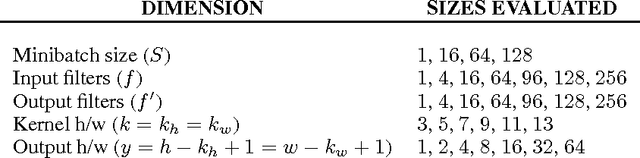
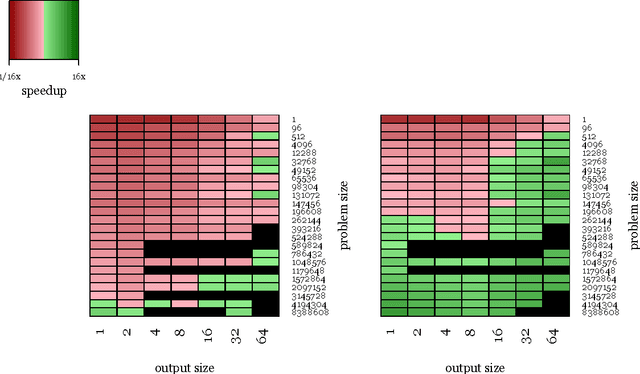
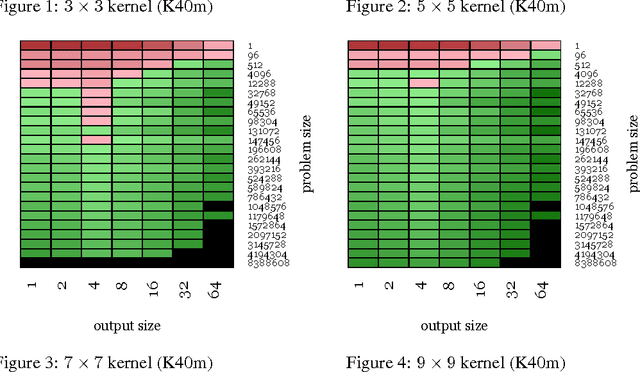
We examine the performance profile of Convolutional Neural Network training on the current generation of NVIDIA Graphics Processing Units. We introduce two new Fast Fourier Transform convolution implementations: one based on NVIDIA's cuFFT library, and another based on a Facebook authored FFT implementation, fbfft, that provides significant speedups over cuFFT (over 1.5x) for whole CNNs. Both of these convolution implementations are available in open source, and are faster than NVIDIA's cuDNN implementation for many common convolutional layers (up to 23.5x for some synthetic kernel configurations). We discuss different performance regimes of convolutions, comparing areas where straightforward time domain convolutions outperform Fourier frequency domain convolutions. Details on algorithmic applications of NVIDIA GPU hardware specifics in the implementation of fbfft are also provided.