 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pruned Key-Value Attention: Learning When to Write by Predicting Future Utility
May 13, 2026Under modern test-time compute and agentic paradigms, language models process ever-longer sequences. Efficient text generation with transformer architectures is increasingly constrained by the Key-Value cache memory footprint and bandwidth. To address this limitation, we introduce Self-Pruned Key-Value Attention (SP-KV), a mechanism designed to predict future KV utility in order to reduce the size of the long-term KV cache. This strategy operates at a fine granularity: a lightweight utility predictor scores each key-value pair, and while recent KVs are always available via a local window, older pairs are written in the cache and used in global attention only if their predicted utility surpasses a given threshold. The LLM and the utility predictor are trained jointly end-to-end exclusively through next-token prediction loss, and are adapted from pretrained LLM checkpoints. Rather than enforcing a fixed compression ratio, SP-KV performs dynamic sparsification: the mechanism adapts to the input and typically reduces the KV cache size by a factor of $3$ to $10\times$, longer sequences often being more compressible. This leads to vast improvements in memory usage and decoding speed, with little to no degradation of validation loss nor performance on a broad set of downstream tasks. Beyond serving as an effective KV-cache reduction mechanism, our method reveals structured layer- and head-specific sparsity patterns that we can use to guide the design of hybrid local-global attention architectures.
Revisiting [CLS] and Patch Token Interaction in Vision Transformers
Feb 09, 2026Vision Transformers have emerged as powerful, scalable and versatile representation learners. To capture both global and local features, a learnable [CLS] class token is typically prepended to the input sequence of patch tokens. Despite their distinct nature, both token types are processed identically throughout the model. In this work, we investigate the friction between global and local feature learning under different pre-training strategies by analyzing the interactions between class and patch tokens. Our analysis reveals that standard normalization layers introduce an implicit differentiation between these token types. Building on this insight, we propose specialized processing paths that selectively disentangle the computational flow of class and patch tokens, particularly within normalization layers and early query-key-value projections. This targeted specialization leads to significantly improved patch representation quality for dense prediction tasks. Our experiments demonstrate segmentation performance gains of over 2 mIoU points on standard benchmarks, while maintaining strong classification accuracy. The proposed modifications introduce only an 8% increase in parameters, with no additional computational overhead. Through comprehensive ablations, we provide insights into which architectural components benefit most from specialization and how our approach generalizes across model scales and learning frameworks.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025



Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
May 24, 2024Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
The Faiss library
Jan 16, 2024
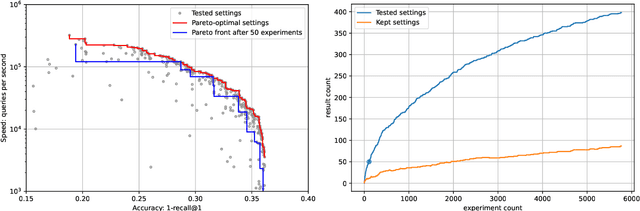

Vector databases manage large collections of embedding vectors. As AI applications are growing rapidly, so are the number of embeddings that need to be stored and indexed. The Faiss library is dedicated to vector similarity search, a core functionality of vector databases. Faiss is a toolkit of indexing methods and related primitives used to search, cluster, compress and transform vectors. This paper first describes the tradeoff space of vector search, then the design principles of Faiss in terms of structure, approach to optimization and interfacing. We benchmark key features of the library and discuss a few selected applications to highlight its broad applicability.
The Stable Signature: Rooting Watermarks in Latent Diffusion Models
Mar 27, 2023Generative image modeling enables a wide range of applications but raises ethical concerns about responsible deployment. This paper introduces an active strategy combining image watermarking and Latent Diffusion Models. The goal is for all generated images to conceal an invisible watermark allowing for future detection and/or identification. The method quickly fine-tunes the latent decoder of the image generator, conditioned on a binary signature. A pre-trained watermark extractor recovers the hidden signature from any generated image and a statistical test then determines whether it comes from the generative model. We evaluate the invisibility and robustness of the watermarks on a variety of generation tasks, showing that Stable Signature works even after the images are modified. For instance, it detects the origin of an image generated from a text prompt, then cropped to keep $10\%$ of the content, with $90$+$\%$ accuracy at a false positive rate below 10$^{-6}$.
Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models
Jan 28, 2023



Lossy image compression aims to represent images in as few bits as possible while maintaining fidelity to the original. Theoretical results indicate that optimizing distortion metrics such as PSNR or MS-SSIM necessarily leads to a discrepancy in the statistics of original images from those of reconstructions, in particular at low bitrates, often manifested by the blurring of the compressed images. Previous work has leveraged adversarial discriminators to improve statistical fidelity. Yet these binary discriminators adopted from generative modeling tasks may not be ideal for image compression. In this paper, we introduce a non-binary discriminator that is conditioned on quantized local image representations obtained via VQ-VAE autoencoders. Our evaluations on the CLIC2020, DIV2K and Kodak datasets show that our discriminator is more effective for jointly optimizing distortion (e.g., PSNR) and statistical fidelity (e.g., FID) than the state-of-the-art HiFiC model. On the CLIC2020 test set, we obtain the same FID as HiFiC with 30-40% fewer bits.
Image Compression with Product Quantized Masked Image Modeling
Dec 14, 2022


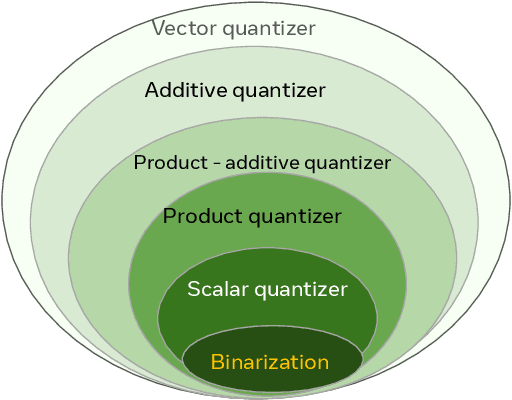
Recent neural compression methods have been based on the popular hyperprior framework. It relies on Scalar Quantization and offers a very strong compression performance. This contrasts from recent advances in image generation and representation learning, where Vector Quantization is more commonly employed. In this work, we attempt to bring these lines of research closer by revisiting vector quantization for image compression. We build upon the VQ-VAE framework and introduce several modifications. First, we replace the vanilla vector quantizer by a product quantizer. This intermediate solution between vector and scalar quantization allows for a much wider set of rate-distortion points: It implicitly defines high-quality quantizers that would otherwise require intractably large codebooks. Second, inspired by the success of Masked Image Modeling (MIM) in the context of self-supervised learning and generative image models, we propose a novel conditional entropy model which improves entropy coding by modelling the co-dependencies of the quantized latent codes. The resulting PQ-MIM model is surprisingly effective: its compression performance on par with recent hyperprior methods. It also outperforms HiFiC in terms of FID and KID metrics when optimized with perceptual losses (e.g. adversarial). Finally, since PQ-MIM is compatible with image generation frameworks, we show qualitatively that it can operate under a hybrid mode between compression and generation, with no further training or finetuning. As a result, we explore the extreme compression regime where an image is compressed into 200 bytes, i.e., less than a tweet.