 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncPatch Diffusion: spatially-flexible image generation
Jun 05, 2026Standard diffusion models corrupt an entire sample with a single shared noise level, forcing all spatial regions to follow the same denoising trajectory. We introduce AsyncPatch Diffusion, a joint-diffusion framework that assigns distinct noise levels to different input dimensions, such as image pixels, or latent tokens. We show how this asynchronous corruption defines a valid generative process while supporting a richer family of spatially heterogeneous denoising trajectories, and prove the first valid ELBO for this process. We show that a single pretrained model can perform spatially adaptive generation, where different regions are denoised on different schedules. A key challenge is training: naive independent noise-level sampling overemphasizes highly heterogeneous configurations and underrepresents homogeneous noise levels, that are crucial during sampling. We address this with a controlled noise-level sampler that regulates both the average corruption level and its spatial variability. AsyncPatch achieves generation quality comparable to conventional diffusion on ImageNet 256 and LSUN, while being natively suited for inpainting without task-specific fine-tuning. We further introduce input guidance, which uses clean or partially corrupted regions to guide the generation of unknown regions, improving local consistency and texture matching. Finally, we demonstrate adaptive generation strategies including uncertainty-guided acceleration and autoregressive sampling.
Evaluating Skill and Stability of ArchesWeather and ArchesWeatherGen under Multi-Decadal Climate Simulations
May 28, 2026We evaluate the climate simulation capabilities of ArchesWeather and ArchesWeatherGen, two machine learning models originally trained for weather forecasting and evaluated up to a 10-day lead time. ArchesWeather is a deterministic model, while ArchesWeatherGen is a probabilistic flow-matching model leveraging ArchesWeather's forecasts, enabling ensemble-based uncertainty quantification. In this work, we adapt these models to act as forced atmospheric models by using additional conditioning on the monthly mean sea surface temperature (SST) and sea ice cover (SIC) as boundary conditions. In particular, we follow the AI Model Intercomparison Project (AIMIP) Phase 1 protocol, which, analogous to the Atmospheric Model Intercomparison Project (AMIP), proposes a standardized experimental setup to evaluate the climate skill of ML-based forced atmospheric models. We present a comprehensive evaluation of both models under these conditions, including comparison against numerical climate models, ablation studies that examine key design choices in the extension, and an analysis of forced versus unforced configurations. Despite being originally developed for weather forecasting, we demonstrate that forced configurations of ArchesWeather and ArchesWeatherGen produce stable long-term climate simulations, have a stable annual cycle, and capture the drift of many climate variables. The models faithfully reproduce ERA5's climatology, large-scale circulations and interannual variability, and they capture the tails of the distributions.
ArchesClimate: Probabilistic Decadal Ensemble Generation With Flow Matching
Sep 19, 2025Climate projections have uncertainties related to components of the climate system and their interactions. A typical approach to quantifying these uncertainties is to use climate models to create ensembles of repeated simulations under different initial conditions. Due to the complexity of these simulations, generating such ensembles of projections is computationally expensive. In this work, we present ArchesClimate, a deep learning-based climate model emulator that aims to reduce this cost. ArchesClimate is trained on decadal hindcasts of the IPSL-CM6A-LR climate model at a spatial resolution of approximately 2.5x1.25 degrees. We train a flow matching model following ArchesWeatherGen, which we adapt to predict near-term climate. Once trained, the model generates states at a one-month lead time and can be used to auto-regressively emulate climate model simulations of any length. We show that for up to 10 years, these generations are stable and physically consistent. We also show that for several important climate variables, ArchesClimate generates simulations that are interchangeable with the IPSL model. This work suggests that climate model emulators could significantly reduce the cost of climate model simulations.
ArchesWeather & ArchesWeatherGen: a deterministic and generative model for efficient ML weather forecasting
Dec 17, 2024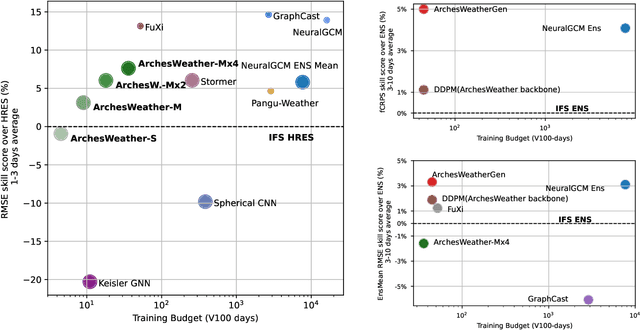

Weather forecasting plays a vital role in today's society, from agriculture and logistics to predicting the output of renewable energies, and preparing for extreme weather events. Deep learning weather forecasting models trained with the next state prediction objective on ERA5 have shown great success compared to numerical global circulation models. However, for a wide range of applications, being able to provide representative samples from the distribution of possible future weather states is critical. In this paper, we propose a methodology to leverage deterministic weather models in the design of probabilistic weather models, leading to improved performance and reduced computing costs. We first introduce \textbf{ArchesWeather}, a transformer-based deterministic model that improves upon Pangu-Weather by removing overrestrictive inductive priors. We then design a probabilistic weather model called \textbf{ArchesWeatherGen} based on flow matching, a modern variant of diffusion models, that is trained to project ArchesWeather's predictions to the distribution of ERA5 weather states. ArchesWeatherGen is a true stochastic emulator of ERA5 and surpasses IFS ENS and NeuralGCM on all WeatherBench headline variables (except for NeuralGCM's geopotential). Our work also aims to democratize the use of deterministic and generative machine learning models in weather forecasting research, with academic computing resources. All models are trained at 1.5{\deg} resolution, with a training budget of $\sim$9 V100 days for ArchesWeather and $\sim$45 V100 days for ArchesWeatherGen. For inference, ArchesWeatherGen generates 15-day weather trajectories at a rate of 1 minute per ensemble member on a A100 GPU card. To make our work fully reproducible, our code and models are open source, including the complete pipeline for data preparation, training, and evaluation, at https://github.com/INRIA/geoarches .
Large Concept Models: Language Modeling in a Sentence Representation Space
Dec 11, 2024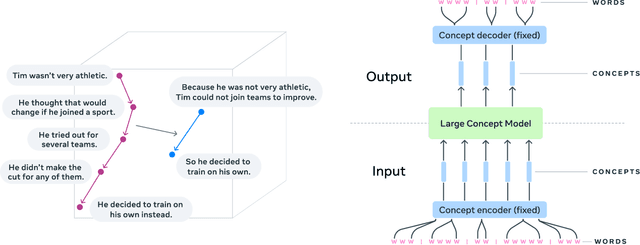
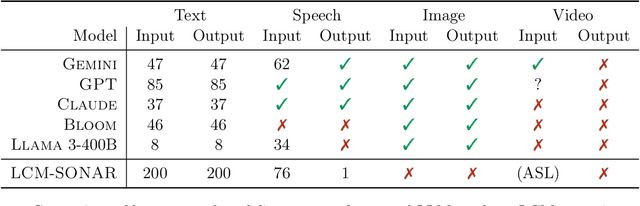
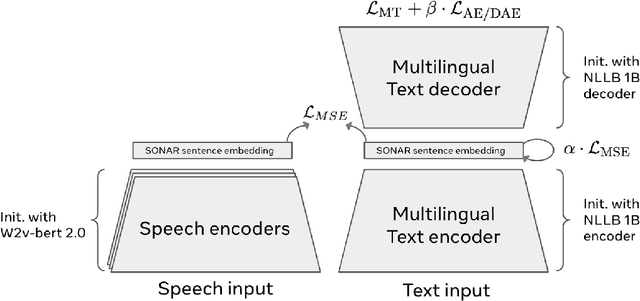
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a "Large Concept Model". In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities. The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.
ArchesWeather: An efficient AI weather forecasting model at 1.5° resolution
May 23, 2024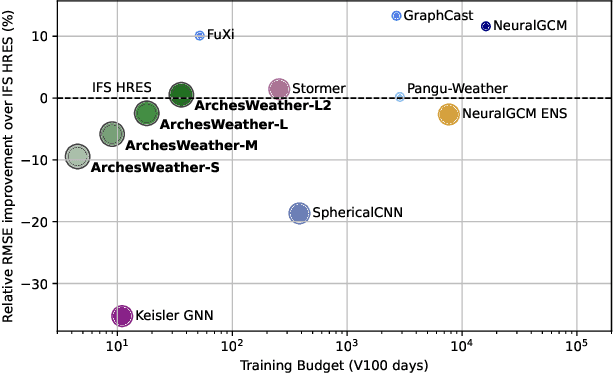
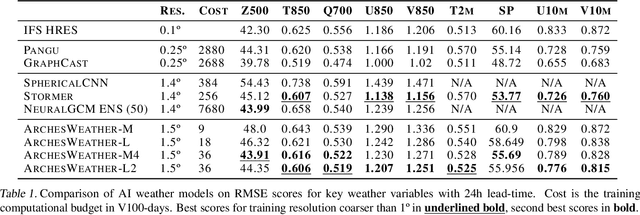
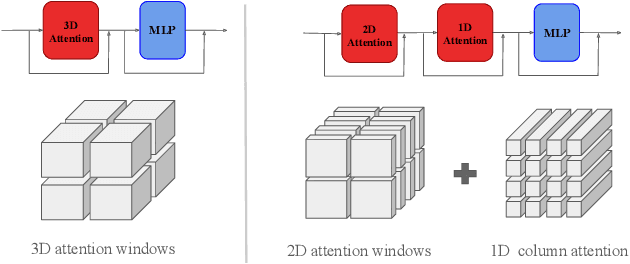
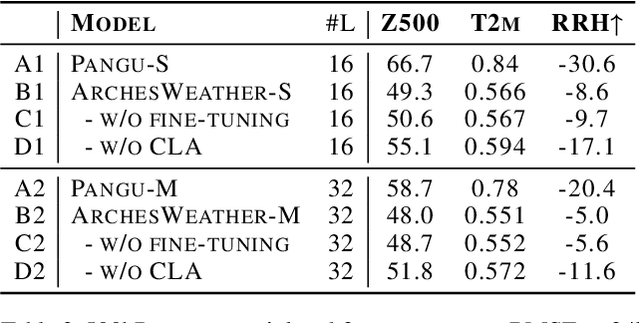
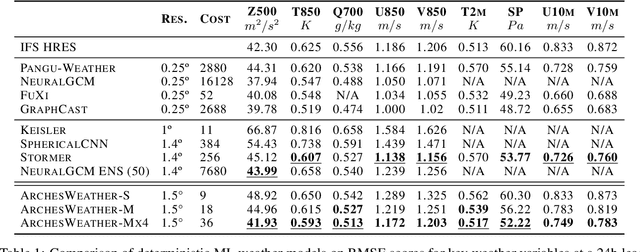
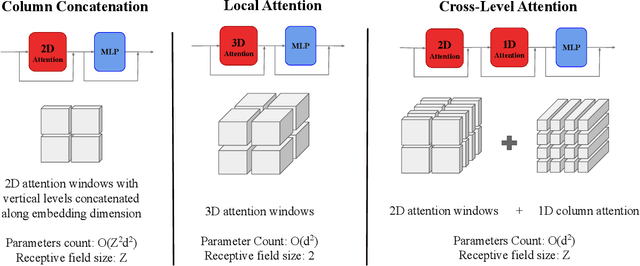
One of the guiding principles for designing AI-based weather forecasting systems is to embed physical constraints as inductive priors in the neural network architecture. A popular prior is locality, where the atmospheric data is processed with local neural interactions, like 3D convolutions or 3D local attention windows as in Pangu-Weather. On the other hand, some works have shown great success in weather forecasting without this locality principle, at the cost of a much higher parameter count. In this paper, we show that the 3D local processing in Pangu-Weather is computationally sub-optimal. We design ArchesWeather, a transformer model that combines 2D attention with a column-wise attention-based feature interaction module, and demonstrate that this design improves forecasting skill. ArchesWeather is trained at 1.5{\deg} resolution and 24h lead time, with a training budget of a few GPU-days and a lower inference cost than competing methods. An ensemble of two of our best models shows competitive RMSE scores with the IFS HRES and outperforms the 1.4{\deg} 50-members NeuralGCM ensemble for one day ahead forecasting. Code and models will be made publicly available at https://github.com/gcouairon/ArchesWeather.
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Mar 29, 2024



Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Gradpaint: Gradient-Guided Inpainting with Diffusion Models
Sep 18, 2023Denoising Diffusion Probabilistic Models (DDPMs) have recently achieved remarkable results in conditional and unconditional image generation. The pre-trained models can be adapted without further training to different downstream tasks, by guiding their iterative denoising process at inference time to satisfy additional constraints. For the specific task of image inpainting, the current guiding mechanism relies on copying-and-pasting the known regions from the input image at each denoising step. However, diffusion models are strongly conditioned by the initial random noise, and therefore struggle to harmonize predictions inside the inpainting mask with the real parts of the input image, often producing results with unnatural artifacts. Our method, dubbed GradPaint, steers the generation towards a globally coherent image. At each step in the denoising process, we leverage the model's "denoised image estimation" by calculating a custom loss measuring its coherence with the masked input image. Our guiding mechanism uses the gradient obtained from backpropagating this loss through the diffusion model itself. GradPaint generalizes well to diffusion models trained on various datasets, improving upon current state-of-the-art supervised and unsupervised methods.
Zero-shot spatial layout conditioning for text-to-image diffusion models
Jun 23, 2023



Large-scale text-to-image diffusion models have significantly improved the state of the art in generative image modelling and allow for an intuitive and powerful user interface to drive the image generation process. Expressing spatial constraints, e.g. to position specific objects in particular locations, is cumbersome using text; and current text-based image generation models are not able to accurately follow such instructions. In this paper we consider image generation from text associated with segments on the image canvas, which combines an intuitive natural language interface with precise spatial control over the generated content. We propose ZestGuide, a zero-shot segmentation guidance approach that can be plugged into pre-trained text-to-image diffusion models, and does not require any additional training. It leverages implicit segmentation maps that can be extracted from cross-attention layers, and uses them to align the generation with input masks. Our experimental results combine high image quality with accurate alignment of generated content with input segmentations, and improve over prior work both quantitatively and qualitatively, including methods that require training on images with corresponding segmentations. Compared to Paint with Words, the previous state-of-the art in image generation with zero-shot segmentation conditioning, we improve by 5 to 10 mIoU points on the COCO dataset with similar FID scores.
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
Jun 07, 2023



Foundation models are first pre-trained on vast unsupervised datasets and then fine-tuned on labeled data. Reinforcement learning, notably from human feedback (RLHF), can further align the network with the intended usage. Yet the imperfections in the proxy reward may hinder the training and lead to suboptimal results; the diversity of objectives in real-world tasks and human opinions exacerbate the issue. This paper proposes embracing the heterogeneity of diverse rewards by following a multi-policy strategy. Rather than focusing on a single a priori reward, we aim for Pareto-optimal generalization across the entire space of preferences. To this end, we propose rewarded soup, first specializing multiple networks independently (one for each proxy reward) and then interpolating their weights linearly. This succeeds empirically because we show that the weights remain linearly connected when fine-tuned on diverse rewards from a shared pre-trained initialization. We demonstrate the effectiveness of our approach for text-to-text (summarization, Q&A, helpful assistant, review), text-image (image captioning, text-to-image generation, visual grounding, VQA), and control (locomotion) tasks. We hope to enhance the alignment of deep models, and how they interact with the world in all its diversity.