 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
BOUQuET: dataset, Benchmark and Open initiative for Universal Quality Evaluation in Translation
Feb 06, 2025



This paper presents BOUQuET, a multicentric and multi-register/domain dataset and benchmark, and its broader collaborative extension initiative. This dataset is handcrafted in non-English languages first, each of these source languages being represented among the 23 languages commonly used by half of the world's population and therefore having the potential to serve as pivot languages that will enable more accurate translations. The dataset is specially designed to avoid contamination and be multicentric, so as to enforce representation of multilingual language features. In addition, the dataset goes beyond the sentence level, as it is organized in paragraphs of various lengths. Compared with related machine translation (MT) datasets, we show that BOUQuET has a broader representation of domains while simplifying the translation task for non-experts. Therefore, BOUQuET is specially suitable for the open initiative and call for translation participation that we are launching to extend it to a multi-way parallel corpus to any written language.
LCFO: Long Context and Long Form Output Dataset and Benchmarking
Dec 12, 2024



This paper presents the Long Context and Form Output (LCFO) benchmark, a novel evaluation framework for assessing gradual summarization and summary expansion capabilities across diverse domains. LCFO consists of long input documents (5k words average length), each of which comes with three summaries of different lengths (20%, 10%, and 5% of the input text), as well as approximately 15 questions and answers (QA) related to the input content. Notably, LCFO also provides alignments between specific QA pairs and corresponding summaries in 7 domains. The primary motivation behind providing summaries of different lengths is to establish a controllable framework for generating long texts from shorter inputs, i.e. summary expansion. To establish an evaluation metric framework for summarization and summary expansion, we provide human evaluation scores for human-generated outputs, as well as results from various state-of-the-art large language models (LLMs). GPT-4o-mini achieves best human scores among automatic systems in both summarization and summary expansion tasks (~ +10% and +20%, respectively). It even surpasses human output quality in the case of short summaries (~ +7%). Overall automatic metrics achieve low correlations with human evaluation scores (~ 0.4) but moderate correlation on specific evaluation aspects such as fluency and attribution (~ 0.6). The LCFO benchmark offers a standardized platform for evaluating summarization and summary expansion performance, as well as corresponding automatic metrics, thereby providing an important evaluation framework to advance generative AI.
2M-BELEBELE: Highly Multilingual Speech and American Sign Language Comprehension Dataset
Dec 11, 2024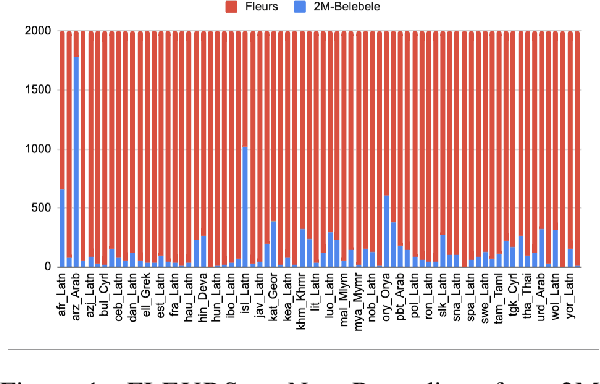

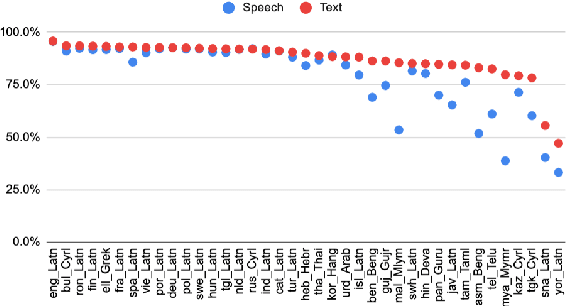
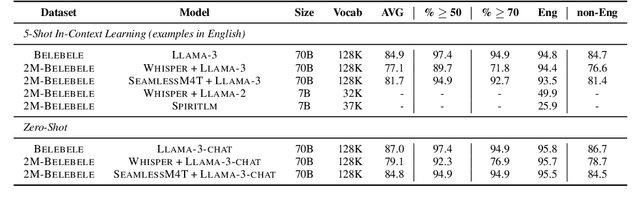
We introduce the first highly multilingual speech and American Sign Language (ASL) comprehension dataset by extending BELEBELE. Our dataset covers 74 spoken languages at the intersection of BELEBELE and FLEURS, and one sign language (ASL). We evaluate 2M-BELEBELE dataset for both 5-shot and zero-shot settings and across languages, the speech comprehension accuracy is ~ 8% average lower compared to reading comprehension.
Large Concept Models: Language Modeling in a Sentence Representation Space
Dec 11, 2024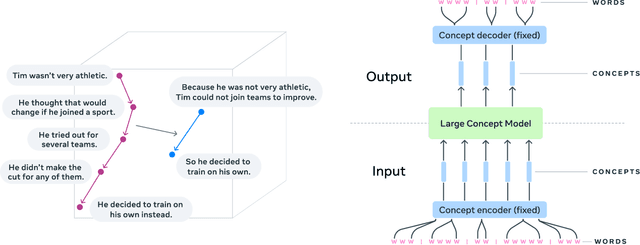
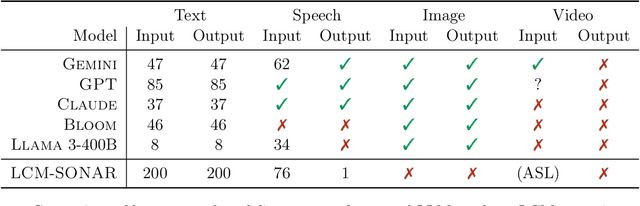
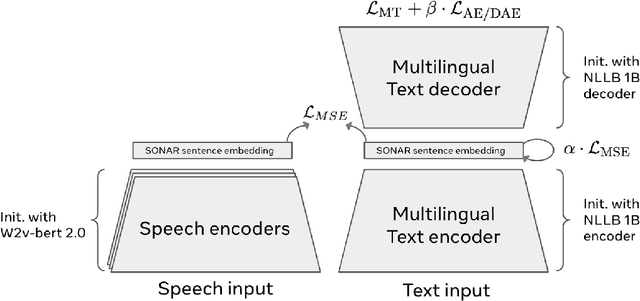
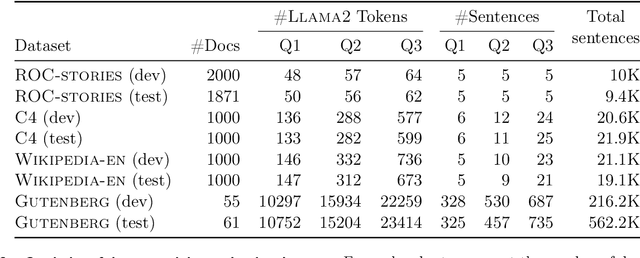
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a "Large Concept Model". In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities. The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.
Towards Red Teaming in Multimodal and Multilingual Translation
Jan 29, 2024Assessing performance in Natural Language Processing is becoming increasingly complex. One particular challenge is the potential for evaluation datasets to overlap with training data, either directly or indirectly, which can lead to skewed results and overestimation of model performance. As a consequence, human evaluation is gaining increasing interest as a means to assess the performance and reliability of models. One such method is the red teaming approach, which aims to generate edge cases where a model will produce critical errors. While this methodology is becoming standard practice for generative AI, its application to the realm of conditional AI remains largely unexplored. This paper presents the first study on human-based red teaming for Machine Translation (MT), marking a significant step towards understanding and improving the performance of translation models. We delve into both human-based red teaming and a study on automation, reporting lessons learned and providing recommendations for both translation models and red teaming drills. This pioneering work opens up new avenues for research and development in the field of MT.
MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Jan 10, 2024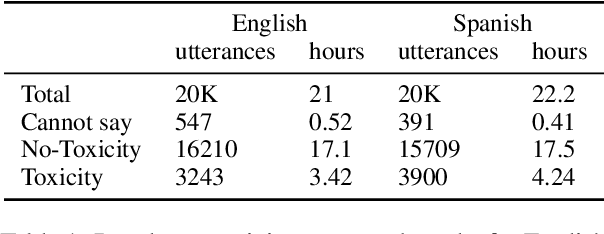
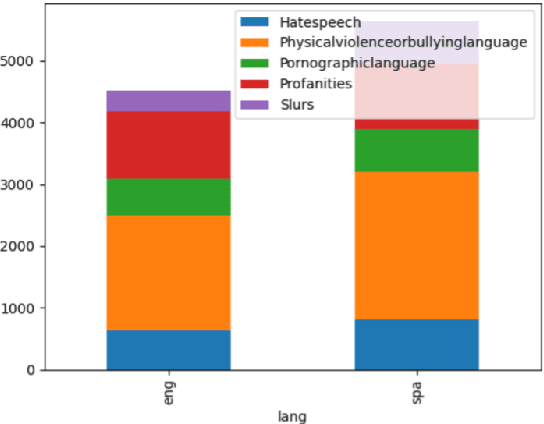
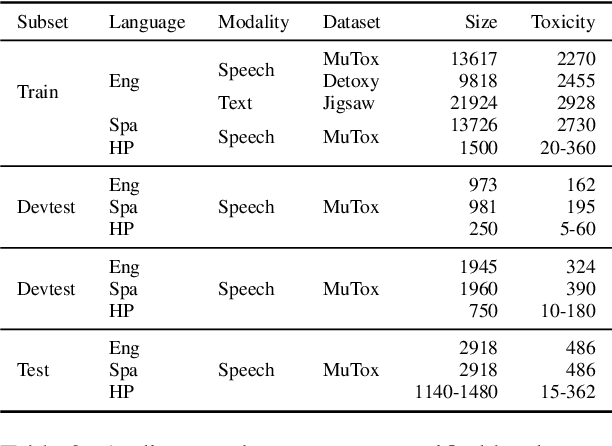
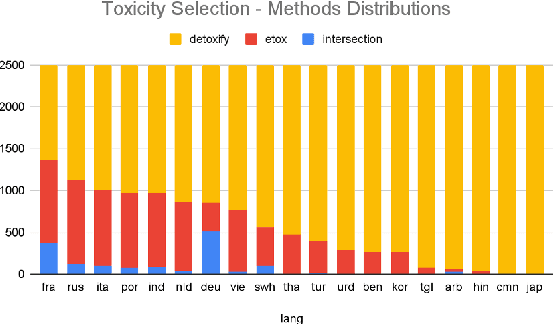
Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Gender-specific Machine Translation with Large Language Models
Sep 06, 2023

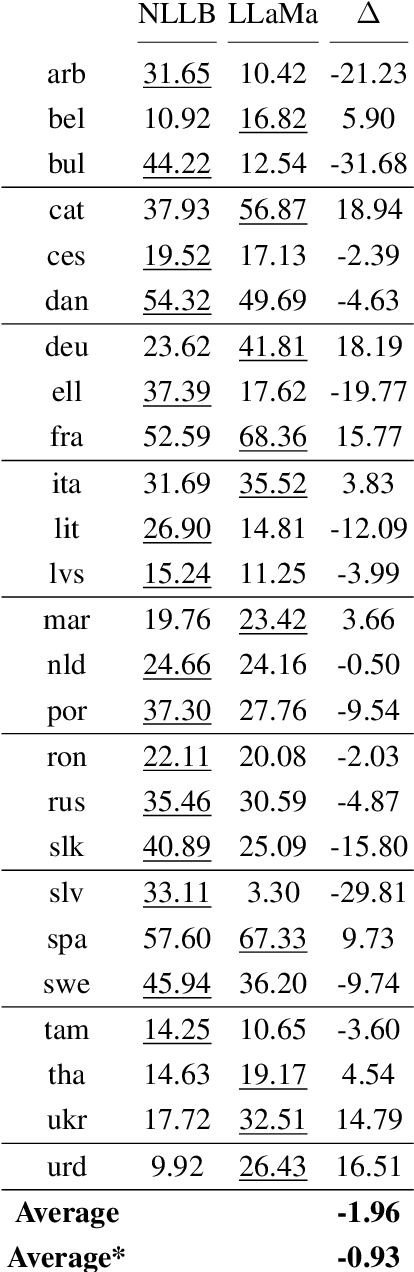
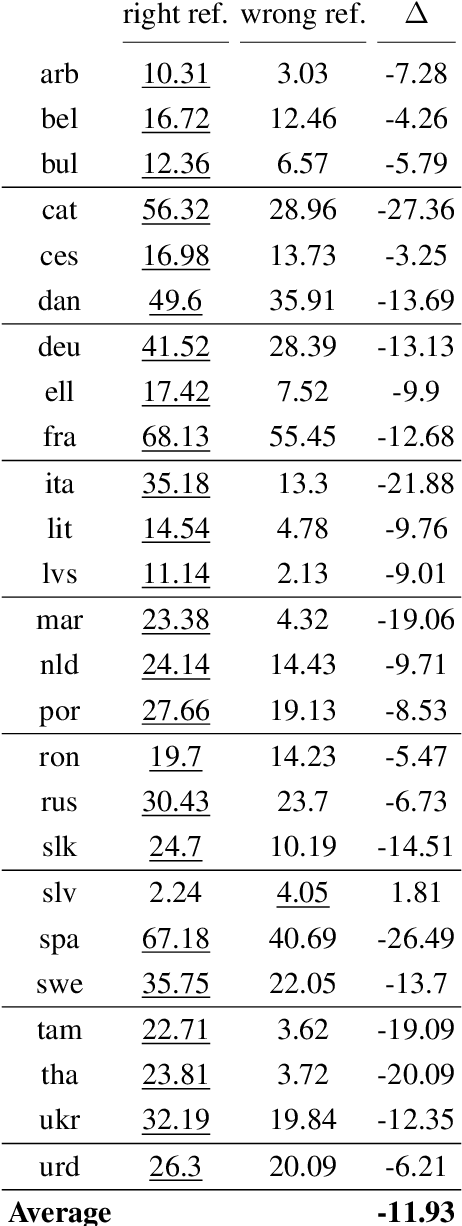
Decoder-only Large Language Models (LLMs) have demonstrated potential in machine translation (MT), albeit with performance slightly lagging behind traditional encoder-decoder Neural Machine Translation (NMT) systems. However, LLMs offer a unique advantage: the ability to control the properties of the output through prompts. In this study, we harness this flexibility to explore LLaMa's capability to produce gender-specific translations for languages with grammatical gender. Our results indicate that LLaMa can generate gender-specific translations with competitive accuracy and gender bias mitigation when compared to NLLB, a state-of-the-art multilingual NMT system. Furthermore, our experiments reveal that LLaMa's translations are robust, showing significant performance drops when evaluated against opposite-gender references in gender-ambiguous datasets but maintaining consistency in less ambiguous contexts. This research provides insights into the potential and challenges of using LLMs for gender-specific translations and highlights the importance of in-context learning to elicit new tasks in LLMs.