 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
2M-BELEBELE: Highly Multilingual Speech and American Sign Language Comprehension Dataset
Dec 11, 2024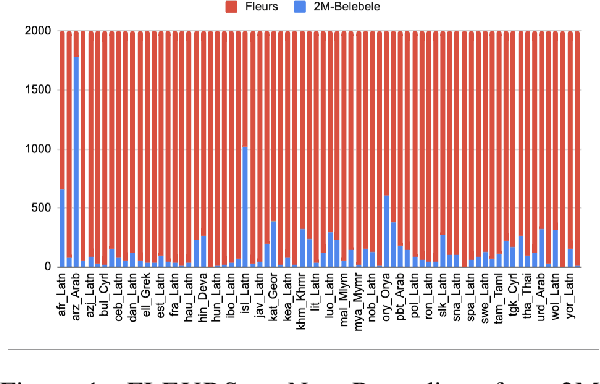

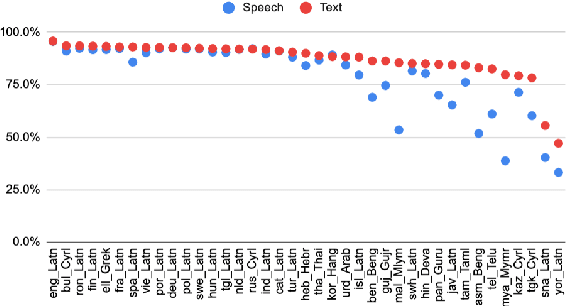
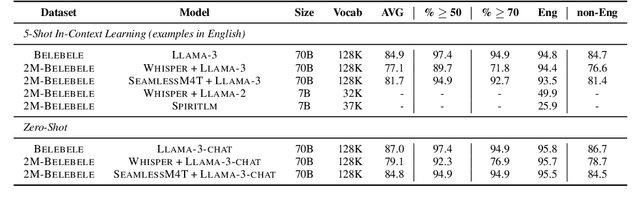
We introduce the first highly multilingual speech and American Sign Language (ASL) comprehension dataset by extending BELEBELE. Our dataset covers 74 spoken languages at the intersection of BELEBELE and FLEURS, and one sign language (ASL). We evaluate 2M-BELEBELE dataset for both 5-shot and zero-shot settings and across languages, the speech comprehension accuracy is ~ 8% average lower compared to reading comprehension.
Towards Massive Multilingual Holistic Bias
Jun 29, 2024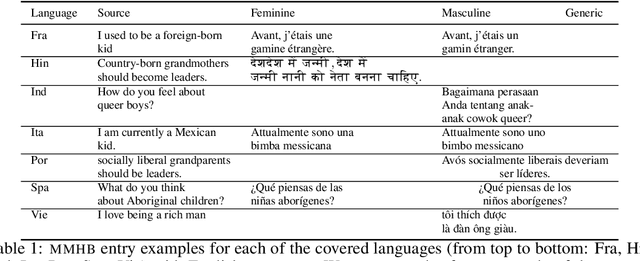
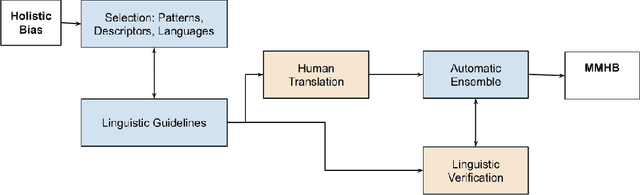
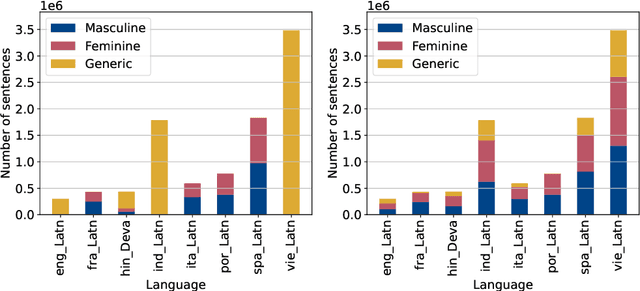
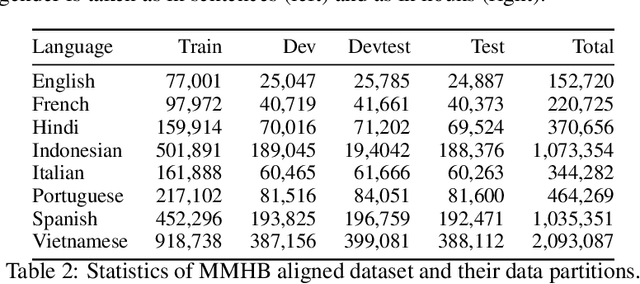
In the current landscape of automatic language generation, there is a need to understand, evaluate, and mitigate demographic biases as existing models are becoming increasingly multilingual. To address this, we present the initial eight languages from the MASSIVE MULTILINGUAL HOLISTICBIAS (MMHB) dataset and benchmark consisting of approximately 6 million sentences representing 13 demographic axes. We propose an automatic construction methodology to further scale up MMHB sentences in terms of both language coverage and size, leveraging limited human annotation. Our approach utilizes placeholders in multilingual sentence construction and employs a systematic method to independently translate sentence patterns, nouns, and descriptors. Combined with human translation, this technique carefully designs placeholders to dynamically generate multiple sentence variations and significantly reduces the human translation workload. The translation process has been meticulously conducted to avoid an English-centric perspective and include all necessary morphological variations for languages that require them, improving from the original English HOLISTICBIAS. Finally, we utilize MMHB to report results on gender bias and added toxicity in machine translation tasks. On the gender analysis, MMHB unveils: (1) a lack of gender robustness showing almost +4 chrf points in average for masculine semantic sentences compared to feminine ones and (2) a preference to overgeneralize to masculine forms by reporting more than +12 chrf points in average when evaluating with masculine compared to feminine references. MMHB triggers added toxicity up to 2.3%.
SpiRit-LM: Interleaved Spoken and Written Language Model
Feb 08, 2024We introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Added Toxicity Mitigation at Inference Time for Multimodal and Massively Multilingual Translation
Nov 11, 2023



Added toxicity in the context of translation refers to the fact of producing a translation output with more toxicity than there exists in the input. In this paper, we present MinTox which is a novel pipeline to identify added toxicity and mitigate this issue which works at inference time. MinTox uses a toxicity detection classifier which is multimodal (speech and text) and works in languages at scale. The mitigation method is applied to languages at scale and directly in text outputs. MinTox is applied to SEAMLESSM4T, which is the latest multimodal and massively multilingual machine translation system. For this system, MinTox achieves significant added toxicity mitigation across domains, modalities and language directions. MinTox manages to approximately filter out from 25% to 95% of added toxicity (depending on the modality and domain) while keeping translation quality.
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication