 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyMam: A Mamba-Based Generator for Artistic Style Transfer
Jan 19, 2026Image style transfer aims to integrate the visual patterns of a specific artistic style into a content image while preserving its content structure. Existing methods mainly rely on the generative adversarial network (GAN) or stable diffusion (SD). GAN-based approaches using CNNs or Transformers struggle to jointly capture local and global dependencies, leading to artifacts and disharmonious patterns. SD-based methods reduce such issues but often fail to preserve content structures and suffer from slow inference. To address these issues, we revisit GAN and propose a mamba-based generator, termed as StyMam, to produce high-quality stylized images without introducing artifacts and disharmonious patterns. Specifically, we introduce a mamba-based generator with a residual dual-path strip scanning mechanism and a channel-reweighted spatial attention module. The former efficiently captures local texture features, while the latter models global dependencies. Finally, extensive qualitative and quantitative experiments demonstrate that the proposed method outperforms state-of-the-art algorithms in both quality and speed.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
Jan 27, 2025



State Space Models (SSMs) have emerged as efficient alternatives to Transformers for sequential modeling, but their inability to leverage modality-specific features limits their performance in multi-modal pretraining. Here, we propose Mixture-of-Mamba, a novel SSM architecture that introduces modality-aware sparsity through modality-specific parameterization of the Mamba block. Building on Mixture-of-Transformers (W. Liang et al. arXiv:2411.04996; 2024), we extend the benefits of modality-aware sparsity to SSMs while preserving their computational efficiency. We evaluate Mixture-of-Mamba across three multi-modal pretraining settings: Transfusion (interleaved text and continuous image tokens with diffusion loss), Chameleon (interleaved text and discrete image tokens), and an extended three-modality framework incorporating speech. Mixture-of-Mamba consistently reaches the same loss values at earlier training steps with significantly reduced computational costs. In the Transfusion setting, Mixture-of-Mamba achieves equivalent image loss using only 34.76% of the training FLOPs at the 1.4B scale. In the Chameleon setting, Mixture-of-Mamba reaches similar image loss with just 42.50% of the FLOPs at the 1.4B scale, and similar text loss with just 65.40% of the FLOPs. In the three-modality setting, MoM matches speech loss at 24.80% of the FLOPs at the 1.4B scale. Our ablation study highlights the synergistic effects of decoupling projection components, where joint decoupling yields greater gains than individual modifications. These results establish modality-aware sparsity as a versatile and effective design principle, extending its impact from Transformers to SSMs and setting new benchmarks in multi-modal pretraining. Our code can be accessed at https://github.com/Weixin-Liang/Mixture-of-Mamba
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Nov 07, 2024

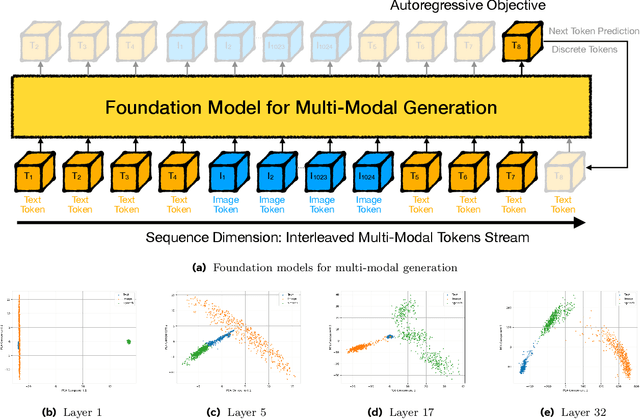

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Exploring Speech Enhancement for Low-resource Speech Synthesis
Sep 19, 2023



High-quality and intelligible speech is essential to text-to-speech (TTS) model training, however, obtaining high-quality data for low-resource languages is challenging and expensive. Applying speech enhancement on Automatic Speech Recognition (ASR) corpus mitigates the issue by augmenting the training data, while how the nonlinear speech distortion brought by speech enhancement models affects TTS training still needs to be investigated. In this paper, we train a TF-GridNet speech enhancement model and apply it to low-resource datasets that were collected for the ASR task, then train a discrete unit based TTS model on the enhanced speech. We use Arabic datasets as an example and show that the proposed pipeline significantly improves the low-resource TTS system compared with other baseline methods in terms of ASR WER metric. We also run empirical analysis on the correlation between speech enhancement and TTS performances.
CoLLD: Contrastive Layer-to-layer Distillation for Compressing Multilingual Pre-trained Speech Encoders
Sep 14, 2023Large-scale self-supervised pre-trained speech encoders outperform conventional approaches in speech recognition and translation tasks. Due to the high cost of developing these large models, building new encoders for new tasks and deploying them to on-device applications are infeasible. Prior studies propose model compression methods to address this issue, but those works focus on smaller models and less realistic tasks. Thus, we propose Contrastive Layer-to-layer Distillation (CoLLD), a novel knowledge distillation method to compress pre-trained speech encoders by leveraging masked prediction and contrastive learning to train student models to copy the behavior of a large teacher model. CoLLD outperforms prior methods and closes the gap between small and large models on multilingual speech-to-text translation and recognition benchmarks.
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Multilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023

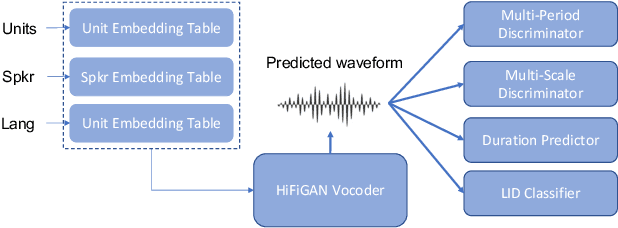

Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.