 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoAction: Cross-task Correlation-aware Pareto Set Learning
May 03, 2026Pareto set learning (PSL) is an emerging paradigm in multi-objective optimization that trains neural networks to map preference vectors to Pareto optimal solutions. However, existing PSL methods primarily focus on solving a single multi-objective optimization problem at a time. This limitation not only increases computational costs in multi-objective multitask optimization scenarios by requiring a separate model for each task, but also fails to exploit the inter-task correlations across tasks. To address this, we propose a Cross-tAsk correlation-aware Pareto Set Learning (CoAction) framework, which leverages task-aware transformer to handle multiple tasks simultaneously. Specifically, by assigning task-specific embedding vectors to individual tasks, the model effectively distinguishes between tasks while facilitating knowledge sharing among them. We utilize a Transformer encoder as the backbone architecture to leverage its self-attention mechanism for capturing complex task dependencies. The proposed approach is evaluated on comprehensive multitask test suites covering both benchmark problems and real-world applications, demonstrating effectiveness and competitive performance in Hypervolume, Range, and Sparsity.
Can LLM-Generated Text Empower Surgical Vision-Language Pre-training?
Apr 20, 2026Recent advancements in self-supervised learning have led to powerful surgical vision encoders capable of spatiotemporal understanding. However, extending these visual foundations to multi-modal reasoning tasks is severely bottlenecked by the prohibitive cost of expert textual annotations. To overcome this scalability limitation, we introduce \textbf{LIME}, a large-scale multi-modal dataset derived from open-access surgical videos using human-free, Large Language Model (LLM)-generated narratives. While LIME offers immense scalability, unverified generated texts may contain errors, including hallucinations, that could potentially lead to catastrophically degraded pre-trained medical priors in standard contrastive pipelines. To mitigate this, we propose \textbf{SurgLIME}, a parameter-efficient Vision-Language Pre-training (VLP) framework designed to learn reliable cross-modal alignments using noisy narratives. SurgLIME preserves foundational medical priors using a LoRA-adapted dual-encoder architecture and introduces an automated confidence estimation mechanism that dynamically down-weights uncertain text during contrastive alignment. Evaluations on the AutoLaparo and Cholec80 benchmarks show that SurgLIME achieves competitive zero-shot cross-modal alignment while preserving the robust linear probing performance of the visual foundation model. Dataset, code, and models are publicly available at \href{https://github.com/visurg-ai/SurgLIME}{https://github.com/visurg-ai/SurgLIME}.
TAMMs: Temporal-Aware Multimodal Model for Satellite Image Change Understanding and Forecasting
Jun 23, 2025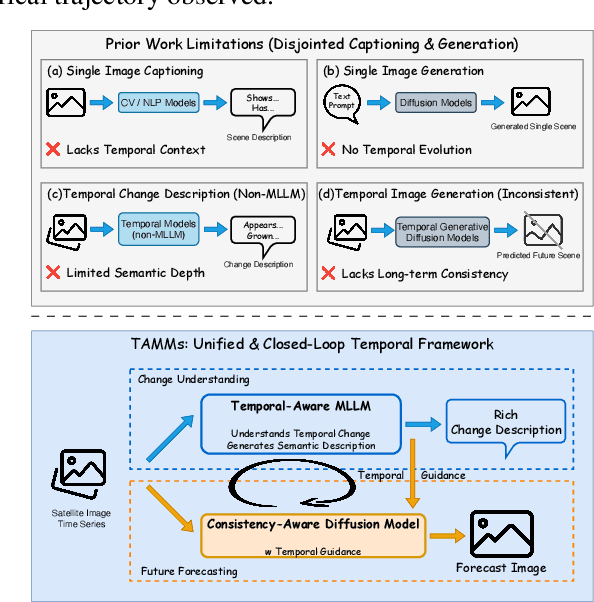
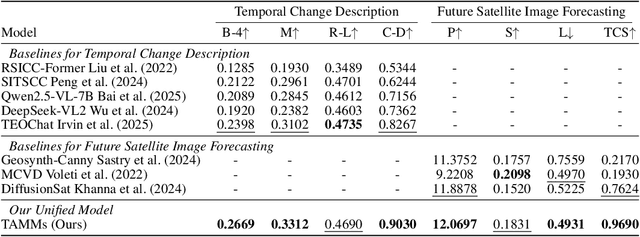
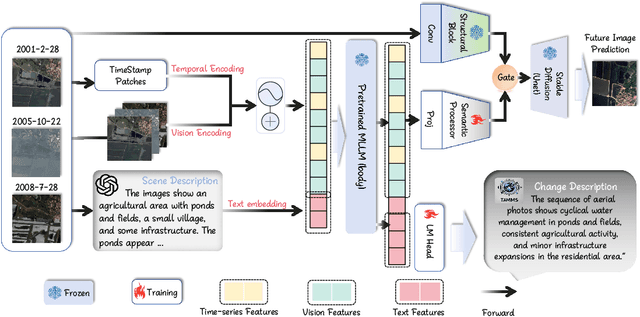
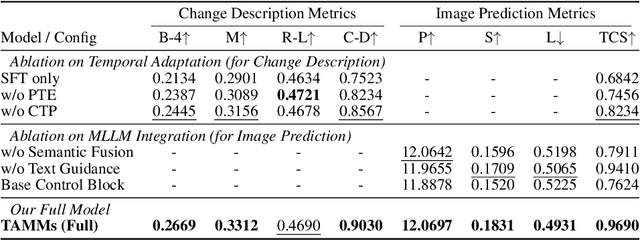
Satellite image time-series analysis demands fine-grained spatial-temporal reasoning, which remains a challenge for existing multimodal large language models (MLLMs). In this work, we study the capabilities of MLLMs on a novel task that jointly targets temporal change understanding and future scene generation, aiming to assess their potential for modeling complex multimodal dynamics over time. We propose TAMMs, a Temporal-Aware Multimodal Model for satellite image change understanding and forecasting, which enhances frozen MLLMs with lightweight temporal modules for structured sequence encoding and contextual prompting. To guide future image generation, TAMMs introduces a Semantic-Fused Control Injection (SFCI) mechanism that adaptively combines high-level semantic reasoning and structural priors within an enhanced ControlNet. This dual-path conditioning enables temporally consistent and semantically grounded image synthesis. Experiments demonstrate that TAMMs outperforms strong MLLM baselines in both temporal change understanding and future image forecasting tasks, highlighting how carefully designed temporal reasoning and semantic fusion can unlock the full potential of MLLMs for spatio-temporal understanding.
MeetMap: Real-Time Collaborative Dialogue Mapping with LLMs in Online Meetings
Feb 03, 2025



Video meeting platforms display conversations linearly through transcripts or summaries. However, ideas during a meeting do not emerge linearly. We leverage LLMs to create dialogue maps in real time to help people visually structure and connect ideas. Balancing the need to reduce the cognitive load on users during the conversation while giving them sufficient control when using AI, we explore two system variants that encompass different levels of AI assistance. In Human-Map, AI generates summaries of conversations as nodes, and users create dialogue maps with the nodes. In AI-Map, AI produces dialogue maps where users can make edits. We ran a within-subject experiment with ten pairs of users, comparing the two MeetMap variants and a baseline. Users preferred MeetMap over traditional methods for taking notes, which aligned better with their mental models of conversations. Users liked the ease of use for AI-Map due to the low effort demands and appreciated the hands-on opportunity in Human-Map for sense-making.
Enhancing Generalized Few-Shot Semantic Segmentation via Effective Knowledge Transfer
Dec 20, 2024
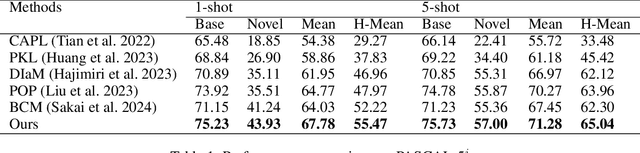


Generalized few-shot semantic segmentation (GFSS) aims to segment objects of both base and novel classes, using sufficient samples of base classes and few samples of novel classes. Representative GFSS approaches typically employ a two-phase training scheme, involving base class pre-training followed by novel class fine-tuning, to learn the classifiers for base and novel classes respectively. Nevertheless, distribution gap exists between base and novel classes in this process. To narrow this gap, we exploit effective knowledge transfer from base to novel classes. First, a novel prototype modulation module is designed to modulate novel class prototypes by exploiting the correlations between base and novel classes. Second, a novel classifier calibration module is proposed to calibrate the weight distribution of the novel classifier according to that of the base classifier. Furthermore, existing GFSS approaches suffer from a lack of contextual information for novel classes due to their limited samples, we thereby introduce a context consistency learning scheme to transfer the contextual knowledge from base to novel classes. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate that our approach significantly enhances the state of the art in the GFSS setting. The code is available at: https://github.com/HHHHedy/GFSS-EKT.
Bridging Gaps: Federated Multi-View Clustering in Heterogeneous Hybrid Views
Oct 12, 2024



Recently, federated multi-view clustering (FedMVC) has emerged to explore cluster structures in multi-view data distributed on multiple clients. Existing approaches often assume that clients are isomorphic and all of them belong to either single-view clients or multi-view clients. Despite their success, these methods also present limitations when dealing with practical FedMVC scenarios involving heterogeneous hybrid views, where a mixture of both single-view and multi-view clients exhibit varying degrees of heterogeneity. In this paper, we propose a novel FedMVC framework, which concurrently addresses two challenges associated with heterogeneous hybrid views, i.e., client gap and view gap. To address the client gap, we design a local-synergistic contrastive learning approach that helps single-view clients and multi-view clients achieve consistency for mitigating heterogeneity among all clients. To address the view gap, we develop a global-specific weighting aggregation method, which encourages global models to learn complementary features from hybrid views. The interplay between local-synergistic contrastive learning and global-specific weighting aggregation mutually enhances the exploration of the data cluster structures distributed on multiple clients. Theoretical analysis and extensive experiments demonstrate that our method can handle the heterogeneous hybrid views in FedMVC and outperforms state-of-the-art methods. The code is available at \url{https://github.com/5Martina5/FMCSC}.
Memory-guided Network with Uncertainty-based Feature Augmentation for Few-shot Semantic Segmentation
Jun 01, 2024

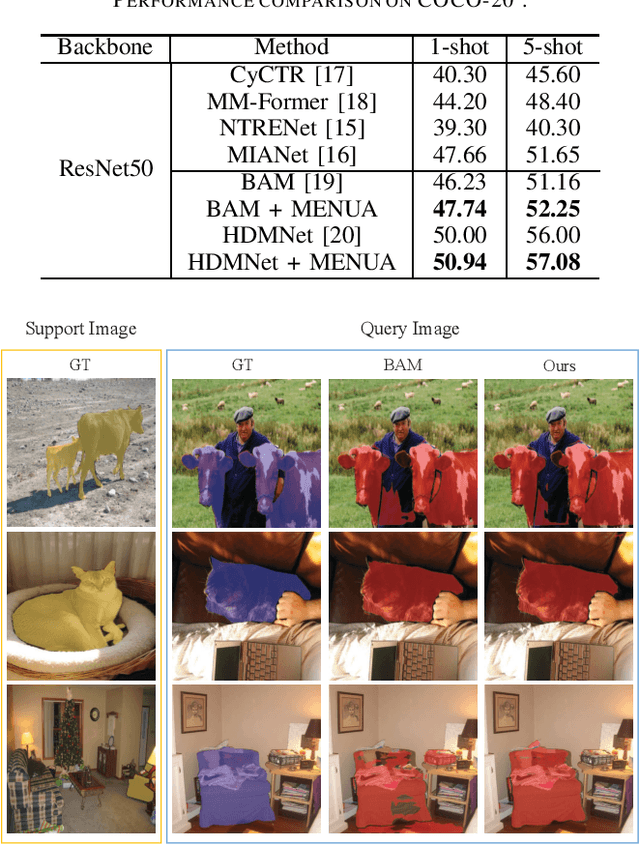

The performance of supervised semantic segmentation methods highly relies on the availability of large-scale training data. To alleviate this dependence, few-shot semantic segmentation (FSS) is introduced to leverage the model trained on base classes with sufficient data into the segmentation of novel classes with few data. FSS methods face the challenge of model generalization on novel classes due to the distribution shift between base and novel classes. To overcome this issue, we propose a class-shared memory (CSM) module consisting of a set of learnable memory vectors. These memory vectors learn elemental object patterns from base classes during training whilst re-encoding query features during both training and inference, thereby improving the distribution alignment between base and novel classes. Furthermore, to cope with the performance degradation resulting from the intra-class variance across images, we introduce an uncertainty-based feature augmentation (UFA) module to produce diverse query features during training for improving the model's robustness. We integrate CSM and UFA into representative FSS works, with experimental results on the widely-used PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrating the superior performance of ours over state of the art.
HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
Feb 01, 2024
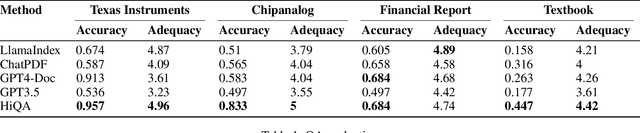
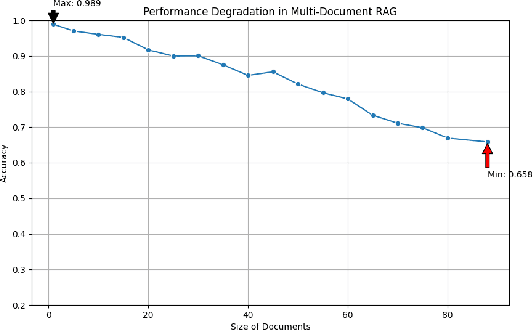
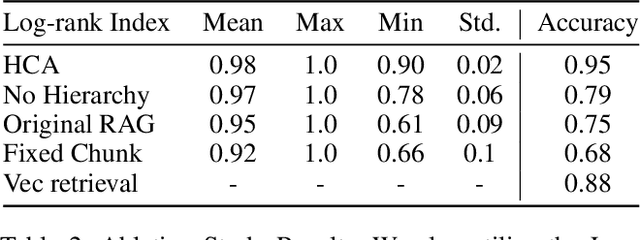
As language model agents leveraging external tools rapidly evolve, significant progress has been made in question-answering(QA) methodologies utilizing supplementary documents and the Retrieval-Augmented Generation (RAG) approach. This advancement has improved the response quality of language models and alleviates the appearance of hallucination. However, these methods exhibit limited retrieval accuracy when faced with massive indistinguishable documents, presenting notable challenges in their practical application. In response to these emerging challenges, we present HiQA, an advanced framework for multi-document question-answering (MDQA) that integrates cascading metadata into content as well as a multi-route retrieval mechanism. We also release a benchmark called MasQA to evaluate and research in MDQA. Finally, HiQA demonstrates the state-of-the-art performance in multi-document environments.
Federated Deep Multi-View Clustering with Global Self-Supervision
Sep 24, 2023
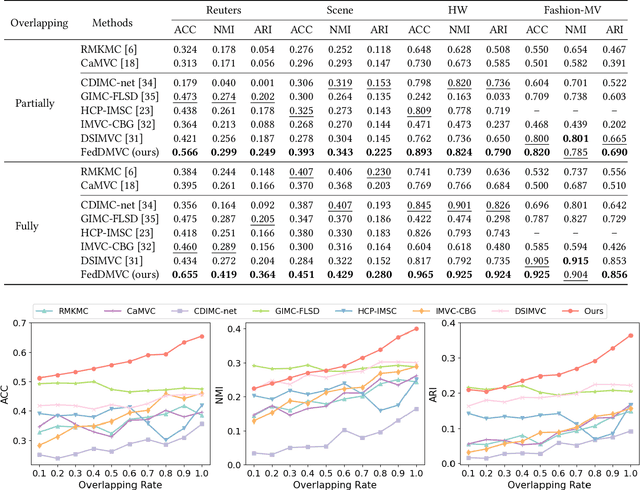
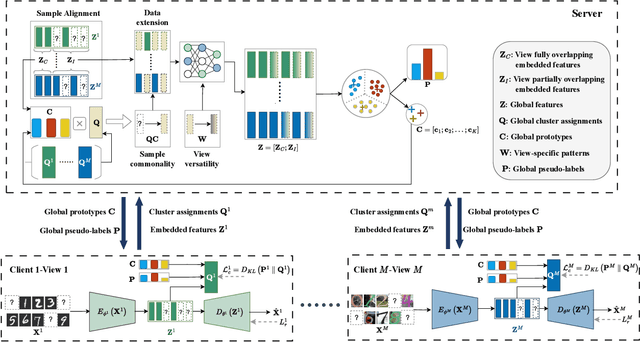

Federated multi-view clustering has the potential to learn a global clustering model from data distributed across multiple devices. In this setting, label information is unknown and data privacy must be preserved, leading to two major challenges. First, views on different clients often have feature heterogeneity, and mining their complementary cluster information is not trivial. Second, the storage and usage of data from multiple clients in a distributed environment can lead to incompleteness of multi-view data. To address these challenges, we propose a novel federated deep multi-view clustering method that can mine complementary cluster structures from multiple clients, while dealing with data incompleteness and privacy concerns. Specifically, in the server environment, we propose sample alignment and data extension techniques to explore the complementary cluster structures of multiple views. The server then distributes global prototypes and global pseudo-labels to each client as global self-supervised information. In the client environment, multiple clients use the global self-supervised information and deep autoencoders to learn view-specific cluster assignments and embedded features, which are then uploaded to the server for refining the global self-supervised information. Finally, the results of our extensive experiments demonstrate that our proposed method exhibits superior performance in addressing the challenges of incomplete multi-view data in distributed environments.
VisualGPTScore: Visio-Linguistic Reasoning with Multimodal Generative Pre-Training Scores
Jun 02, 2023
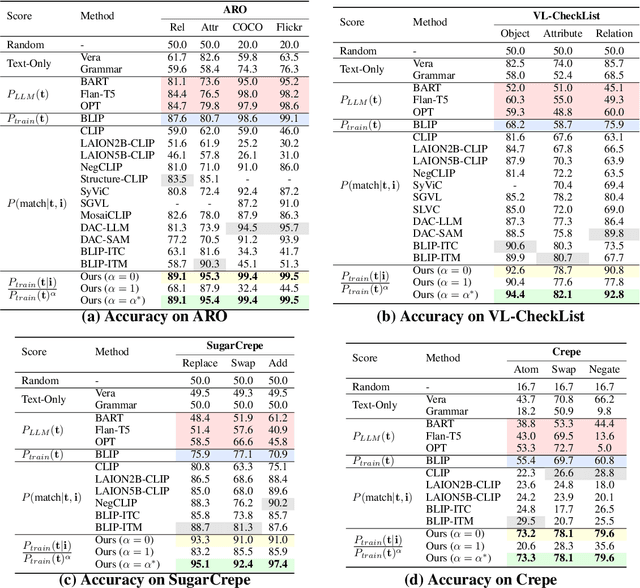
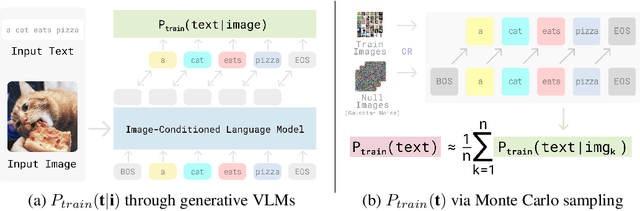
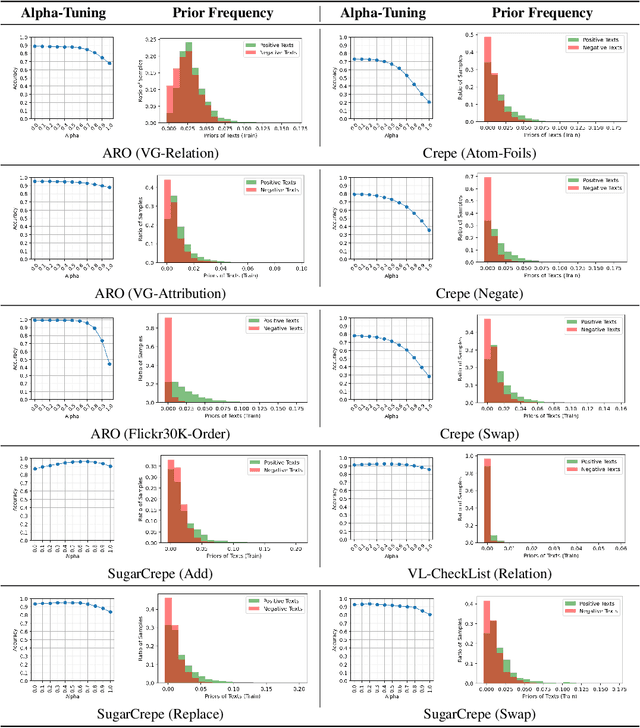
Vision-language models (VLMs) discriminatively pre-trained with contrastive image-text matching losses such as $P(\text{match}|\text{text}, \text{image})$ have been criticized for lacking compositional understanding. This means they might output similar scores even if the original caption is rearranged into a different semantic statement. To address this, we propose to use the ${\bf V}$isual ${\bf G}$enerative ${\bf P}$re-${\bf T}$raining Score (${\bf VisualGPTScore}$) of $P(\text{text}|\text{image})$, a $\textit{multimodal generative}$ score that captures the likelihood of a text caption conditioned on an image using an image-conditioned language model. Contrary to the belief that VLMs are mere bag-of-words models, our off-the-shelf VisualGPTScore demonstrates top-tier performance on recently proposed image-text retrieval benchmarks like ARO and Crepe that assess compositional reasoning. Furthermore, we factorize VisualGPTScore into a product of the $\textit{marginal}$ P(text) and the $\textit{Pointwise Mutual Information}$ (PMI). This helps to (a) diagnose datasets with strong language bias, and (b) debias results on other benchmarks like Winoground using an information-theoretic framework. VisualGPTScore provides valuable insights and serves as a strong baseline for future evaluation of visio-linguistic compositionality.