 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeeking Into The Future For Contextual Biasing
Dec 19, 2025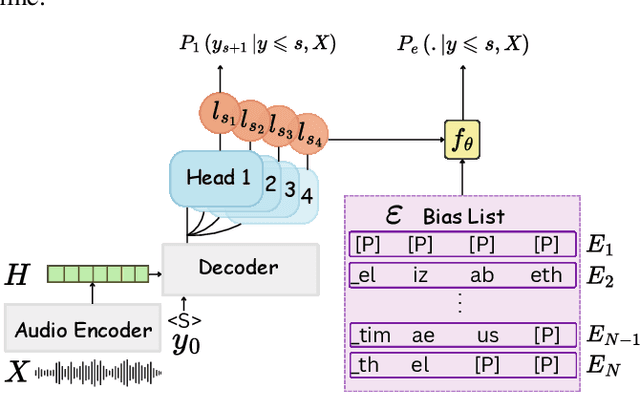
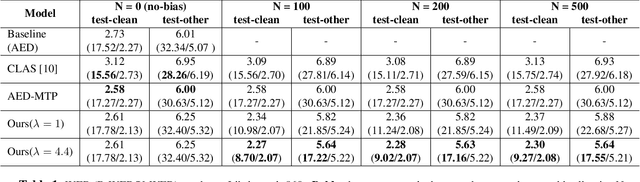
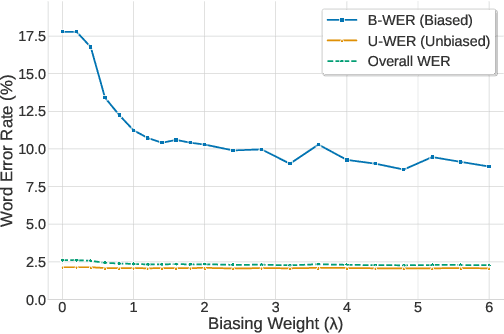
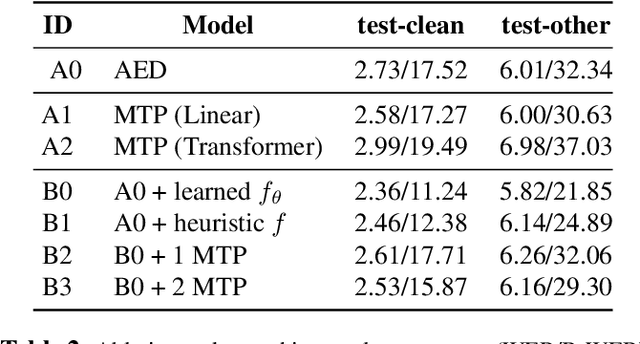
While end-to-end (E2E) automatic speech recognition (ASR) models excel at general transcription, they struggle to recognize rare or unseen named entities (e.g., contact names, locations), which are critical for downstream applications like virtual assistants. In this paper, we propose a contextual biasing method for attention based encoder decoder (AED) models using a list of candidate named entities. Instead of predicting only the next token, we simultaneously predict multiple future tokens, enabling the model to "peek into the future" and score potential candidate entities in the entity list. Moreover, our approach leverages the multi-token prediction logits directly without requiring additional entity encoders or cross-attention layers, significantly reducing architectural complexity. Experiments on Librispeech demonstrate that our approach achieves up to 50.34% relative improvement in named entity word error rate compared to the baseline AED model.
Chunk Based Speech Pre-training with High Resolution Finite Scalar Quantization
Sep 19, 2025Low latency speech human-machine communication is becoming increasingly necessary as speech technology advances quickly in the last decade. One of the primary factors behind the advancement of speech technology is self-supervised learning. Most self-supervised learning algorithms are designed with full utterance assumption and compromises have to made if partial utterances are presented, which are common in the streaming applications. In this work, we propose a chunk based self-supervised learning (Chunk SSL) algorithm as an unified solution for both streaming and offline speech pre-training. Chunk SSL is optimized with the masked prediction loss and an acoustic encoder is encouraged to restore indices of those masked speech frames with help from unmasked frames in the same chunk and preceding chunks. A copy and append data augmentation approach is proposed to conduct efficient chunk based pre-training. Chunk SSL utilizes a finite scalar quantization (FSQ) module to discretize input speech features and our study shows a high resolution FSQ codebook, i.e., a codebook with vocabulary size up to a few millions, is beneficial to transfer knowledge from the pre-training task to the downstream tasks. A group masked prediction loss is employed during pre-training to alleviate the high memory and computation cost introduced by the large codebook. The proposed approach is examined in two speech to text tasks, i.e., speech recognition and speech translation. Experimental results on the \textsc{Librispeech} and \textsc{Must-C} datasets show that the proposed method could achieve very competitive results for speech to text tasks at both streaming and offline modes.
Enhanced Hybrid Transducer and Attention Encoder Decoder with Text Data
Jun 23, 2025A joint speech and text optimization method is proposed for hybrid transducer and attention-based encoder decoder (TAED) modeling to leverage large amounts of text corpus and enhance ASR accuracy. The joint TAED (J-TAED) is trained with both speech and text input modalities together, while it only takes speech data as input during inference. The trained model can unify the internal representations from different modalities, and be further extended to text-based domain adaptation. It can effectively alleviate data scarcity for mismatch domain tasks since no speech data is required. Our experiments show J-TAED successfully integrates speech and linguistic information into one model, and reduce the WER by 5.8 ~12.8% on the Librispeech dataset. The model is also evaluated on two out-of-domain datasets: one is finance and another is named entity focused. The text-based domain adaptation brings 15.3% and 17.8% WER reduction on those two datasets respectively.
Building AI Service Repositories for On-Demand Service Orchestration in 6G AI-RAN
Apr 13, 2025



Efficient orchestration of AI services in 6G AI-RAN requires well-structured, ready-to-deploy AI service repositories combined with orchestration methods adaptive to diverse runtime contexts across radio access, edge, and cloud layers. Current literature lacks comprehensive frameworks for constructing such repositories and generally overlooks key practical orchestration factors. This paper systematically identifies and categorizes critical attributes influencing AI service orchestration in 6G networks and introduces an open-source, LLM-assisted toolchain that automates service packaging, deployment, and runtime profiling. We validate the proposed toolchain through the Cranfield AI Service repository case study, demonstrating significant automation benefits, reduced manual coding efforts, and the necessity of infrastructure-specific profiling, paving the way for more practical orchestration frameworks.
Contextualized Autonomous Drone Navigation using LLMs Deployed in Edge-Cloud Computing
Apr 01, 2025Autonomous navigation is usually trained offline in diverse scenarios and fine-tuned online subject to real-world experiences. However, the real world is dynamic and changeable, and many environmental encounters/effects are not accounted for in real-time due to difficulties in describing them within offline training data or hard to describe even in online scenarios. However, we know that the human operator can describe these dynamic environmental encounters through natural language, adding semantic context. The research is to deploy Large Language Models (LLMs) to perform real-time contextual code adjustment to autonomous navigation. The challenge not evaluated in literature is what LLMs are appropriate and where should these computationally heavy algorithms sit in the computation-communication edge-cloud computing architectures. In this paper, we evaluate how different LLMs can adjust both the navigation map parameters dynamically (e.g., contour map shaping) and also derive navigation task instruction sets. We then evaluate which LLMs are most suitable and where they should sit in future edge-cloud of 6G telecommunication architectures.
RAG-based User Profiling for Precision Planning in Mixed-precision Over-the-Air Federated Learning
Mar 19, 2025



Mixed-precision computing, a widely applied technique in AI, offers a larger trade-off space between accuracy and efficiency. The recent purposed Mixed-Precision Over-the-Air Federated Learning (MP-OTA-FL) enables clients to operate at appropriate precision levels based on their heterogeneous hardware, taking advantages of the larger trade-off space while covering the quantization overheads in the mixed-precision modulation scheme for the OTA aggregation process. A key to further exploring the potential of the MP-OTA-FL framework is the optimization of client precision levels. The choice of precision level hinges on multifaceted factors including hardware capability, potential client contribution, and user satisfaction, among which factors can be difficult to define or quantify. In this paper, we propose a RAG-based User Profiling for precision planning framework that integrates retrieval-augmented LLMs and dynamic client profiling to optimize satisfaction and contributions. This includes a hybrid interface for gathering device/user insights and an RAG database storing historical quantization decisions with feedback. Experiments show that our method boosts satisfaction, energy savings, and global model accuracy in MP-OTA-FL systems.
End-to-End Edge AI Service Provisioning Framework in 6G ORAN
Mar 15, 2025


With the advent of 6G, Open Radio Access Network (O-RAN) architectures are evolving to support intelligent, adaptive, and automated network orchestration. This paper proposes a novel Edge AI and Network Service Orchestration framework that leverages Large Language Model (LLM) agents deployed as O-RAN rApps. The proposed LLM-agent-powered system enables interactive and intuitive orchestration by translating the user's use case description into deployable AI services and corresponding network configurations. The LLM agent automates multiple tasks, including AI model selection from repositories (e.g., Hugging Face), service deployment, network adaptation, and real-time monitoring via xApps. We implement a prototype using open-source O-RAN projects (OpenAirInterface and FlexRIC) to demonstrate the feasibility and functionality of our framework. Our demonstration showcases the end-to-end flow of AI service orchestration, from user interaction to network adaptation, ensuring Quality of Service (QoS) compliance. This work highlights the potential of integrating LLM-driven automation into 6G O-RAN ecosystems, paving the way for more accessible and efficient edge AI ecosystems.
Automatic Item Generation for Personality Situational Judgment Tests with Large Language Models
Dec 10, 2024Personality assessment, particularly through situational judgment tests (SJTs), is a vital tool for psychological research, talent selection, and educational evaluation. This study explores the potential of GPT-4, a state-of-the-art large language model (LLM), to automate the generation of personality situational judgment tests (PSJTs) in Chinese. Traditional SJT development is labor-intensive and prone to biases, while GPT-4 offers a scalable, efficient alternative. Two studies were conducted: Study 1 evaluated the impact of prompt design and temperature settings on content validity, finding that optimized prompts with a temperature of 1.0 produced creative and accurate items. Study 2 assessed the psychometric properties of GPT-4-generated PSJTs, revealing that they demonstrated satisfactory reliability and validity, surpassing the performance of manually developed tests in measuring the Big Five personality traits. This research highlights GPT-4's effectiveness in developing high-quality PSJTs, providing a scalable and innovative method for psychometric test development. These findings expand the possibilities of automatic item generation and the application of LLMs in psychology, and offer practical implications for streamlining test development processes in resource-limited settings.
Transducer Consistency Regularization for Speech to Text Applications
Oct 09, 2024



Consistency regularization is a commonly used practice to encourage the model to generate consistent representation from distorted input features and improve model generalization. It shows significant improvement on various speech applications that are optimized with cross entropy criterion. However, it is not straightforward to apply consistency regularization for the transducer-based approaches, which are widely adopted for speech applications due to the competitive performance and streaming characteristic. The main challenge is from the vast alignment space of the transducer optimization criterion and not all the alignments within the space contribute to the model optimization equally. In this study, we present Transducer Consistency Regularization (TCR), a consistency regularization method for transducer models. We apply distortions such as spec augmentation and dropout to create different data views and minimize the distribution difference. We utilize occupational probabilities to give different weights on transducer output distributions, thus only alignments close to oracle alignments would contribute to the model learning. Our experiments show the proposed method is superior to other consistency regularization implementations and could effectively reduce word error rate (WER) by 4.3\% relatively comparing with a strong baseline on the \textsc{Librispeech} dataset.
ProTIP: Probabilistic Robustness Verification on Text-to-Image Diffusion Models against Stochastic Perturbation
Feb 23, 2024



Text-to-Image (T2I) Diffusion Models (DMs) have shown impressive abilities in generating high-quality images based on simple text descriptions. However, as is common with many Deep Learning (DL) models, DMs are subject to a lack of robustness. While there are attempts to evaluate the robustness of T2I DMs as a binary or worst-case problem, they cannot answer how robust in general the model is whenever an adversarial example (AE) can be found. In this study, we first introduce a probabilistic notion of T2I DMs' robustness; and then establish an efficient framework, ProTIP, to evaluate it with statistical guarantees. The main challenges stem from: i) the high computational cost of the generation process; and ii) determining if a perturbed input is an AE involves comparing two output distributions, which is fundamentally harder compared to other DL tasks like classification where an AE is identified upon misprediction of labels. To tackle the challenges, we employ sequential analysis with efficacy and futility early stopping rules in the statistical testing for identifying AEs, and adaptive concentration inequalities to dynamically determine the "just-right" number of stochastic perturbations whenever the verification target is met. Empirical experiments validate the effectiveness and efficiency of ProTIP over common T2I DMs. Finally, we demonstrate an application of ProTIP to rank commonly used defence methods.