 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoBabyVLM: Benchmarking Cross-Modal Learning from Naturalistic Egocentric Video Data
May 18, 2026Children acquire language grounding with remarkable robustness from limited visuo-linguistic input in ways that surpass today's best large multimodal models. Recent research suggests current vision-language models (VLMs) trained on curated web data fail to generalize to the sparse, weakly-aligned egocentric streams produced by wearable devices, embodied agents, and infant head-cams -- and no fixed evaluation pipeline exists for measuring progress on this regime. We train VLMs on datasets with varying degrees of semantic alignment between visual and linguistic inputs, including naturalistic infant and adult egocentric videos, and evaluate them with a comprehensive suite spanning multimodal language grounding and unimodal vision and language tasks. At the core of this suite is Machine-DevBench, a corpus-grounded benchmark of lexical and grammatical competence, automatically generated from the model's training vocabulary across logarithmic frequency bins to eliminate the train/eval mismatch and low statistical power of prior developmental benchmarks. Our results show that current VLM paradigms hinge on the tight semantic alignment of curated data and fail to exploit the weakly-aligned signal that dominates naturalistic egocentric input -- the very regime in which humans thrive. To motivate progress, we introduce the EgoBabyVLM Challenge to drive the development of models capable of grounded language learning from the kind of naturalistic data that human infants experience.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025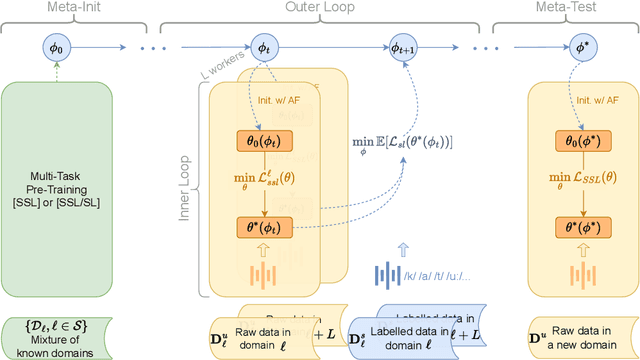

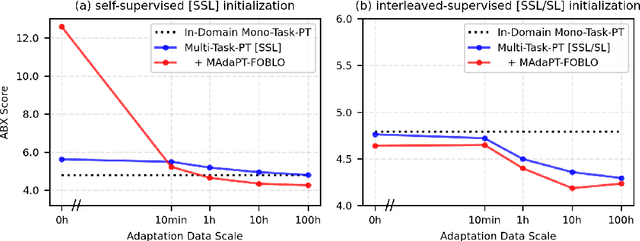
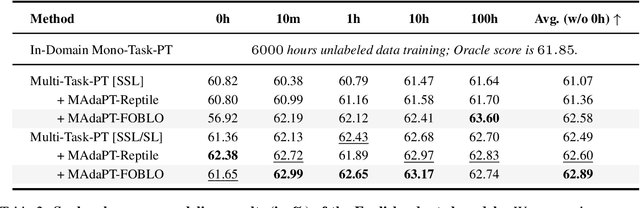
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
LongTail-Swap: benchmarking language models' abilities on rare words
Oct 05, 2025Children learn to speak with a low amount of data and can be taught new words on a few-shot basis, making them particularly data-efficient learners. The BabyLM challenge aims at exploring language model (LM) training in the low-data regime but uses metrics that concentrate on the head of the word distribution. Here, we introduce LongTail-Swap (LT-Swap), a benchmark that focuses on the tail of the distribution, i.e., measures the ability of LMs to learn new words with very little exposure, like infants do. LT-Swap is a pretraining corpus-specific test set of acceptable versus unacceptable sentence pairs that isolate semantic and syntactic usage of rare words. Models are evaluated in a zero-shot fashion by computing the average log probabilities over the two members of each pair. We built two such test sets associated with the 10M words and 100M words BabyLM training sets, respectively, and evaluated 16 models from the BabyLM leaderboard. Our results not only highlight the poor performance of language models on rare words but also reveal that performance differences across LM architectures are much more pronounced in the long tail than in the head. This offers new insights into which architectures are better at handling rare word generalization. We've also made the code publicly avail
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
Mar 21, 2024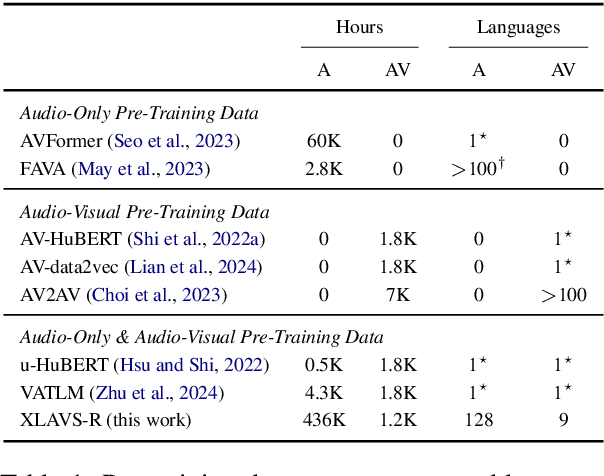
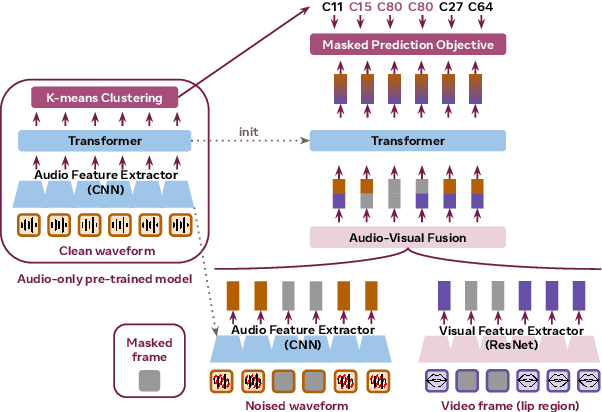
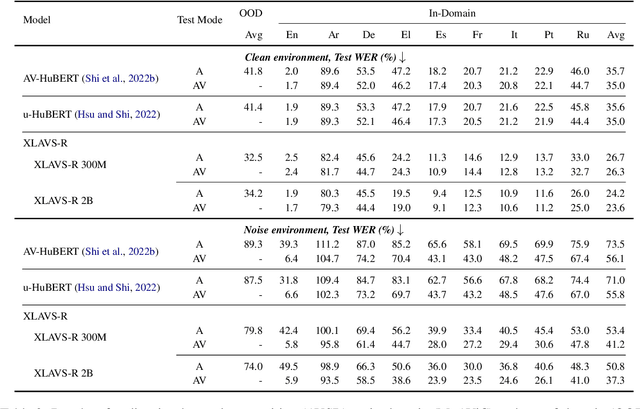
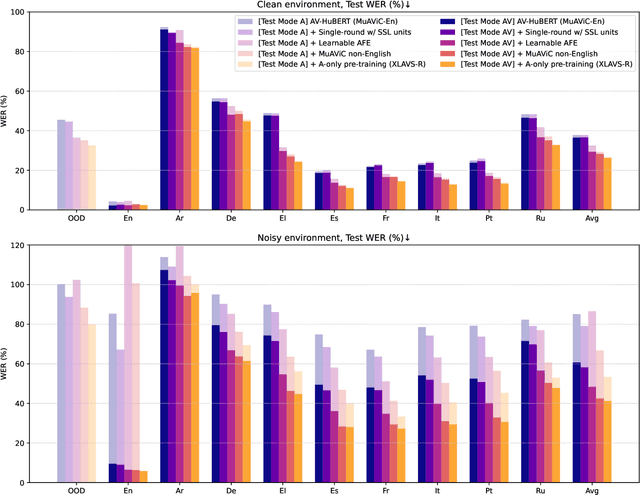
Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
SpiRit-LM: Interleaved Spoken and Written Language Model
Feb 08, 2024We introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Multilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023

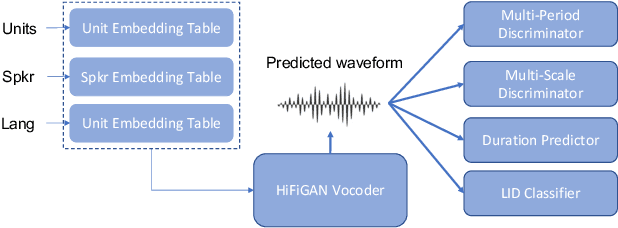

Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.