 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
DC-Spin: A Speaker-invariant Speech Tokenizer for Spoken Language Models
Oct 31, 2024Spoken language models (SLMs) have gained increasing attention with advancements in text-based, decoder-only language models. SLMs process text and speech, enabling simultaneous speech understanding and generation. This paper presents Double-Codebook Speaker-invariant Clustering (DC-Spin), which aims to improve speech tokenization by bridging audio signals and SLM tokens. DC-Spin extracts speaker-invariant tokens rich in phonetic information and resilient to input variations, enhancing zero-shot SLM tasks and speech resynthesis. We propose a chunk-wise approach to enable streamable DC-Spin without retraining and degradation. Comparisons of tokenization methods (self-supervised and neural audio codecs), model scalability, and downstream task proxies show that tokens easily modeled by an n-gram LM or aligned with phonemes offer strong performance, providing insights for designing speech tokenizers for SLMs.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
CoLLD: Contrastive Layer-to-layer Distillation for Compressing Multilingual Pre-trained Speech Encoders
Sep 14, 2023

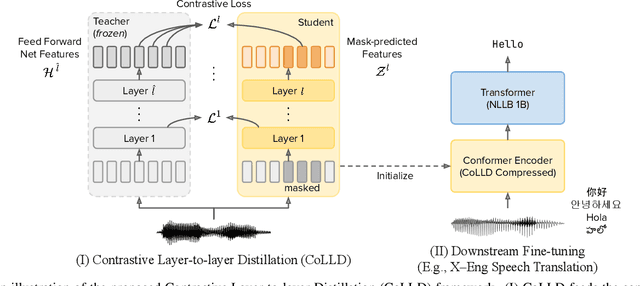

Large-scale self-supervised pre-trained speech encoders outperform conventional approaches in speech recognition and translation tasks. Due to the high cost of developing these large models, building new encoders for new tasks and deploying them to on-device applications are infeasible. Prior studies propose model compression methods to address this issue, but those works focus on smaller models and less realistic tasks. Thus, we propose Contrastive Layer-to-layer Distillation (CoLLD), a novel knowledge distillation method to compress pre-trained speech encoders by leveraging masked prediction and contrastive learning to train student models to copy the behavior of a large teacher model. CoLLD outperforms prior methods and closes the gap between small and large models on multilingual speech-to-text translation and recognition benchmarks.
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Dec 15, 2022Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022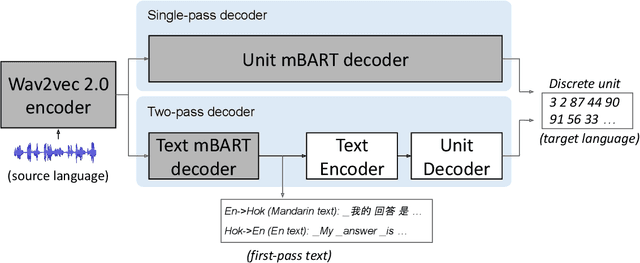
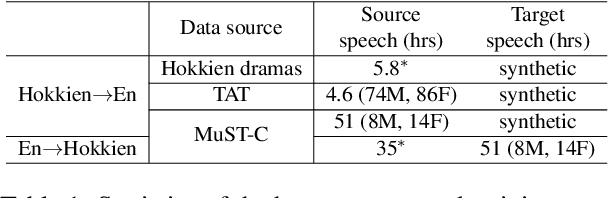
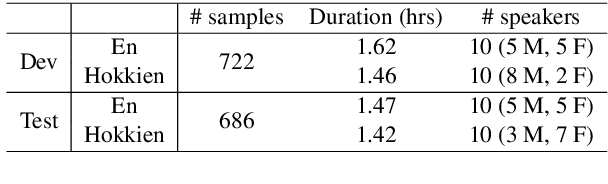
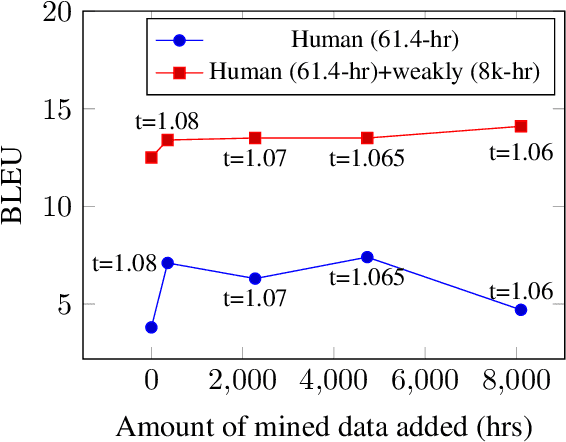
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
SSAST: Self-Supervised Audio Spectrogram Transformer
Oct 19, 2021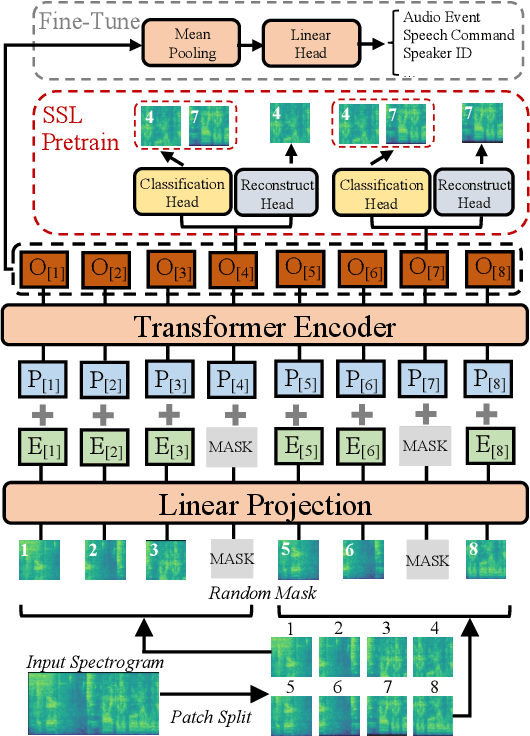
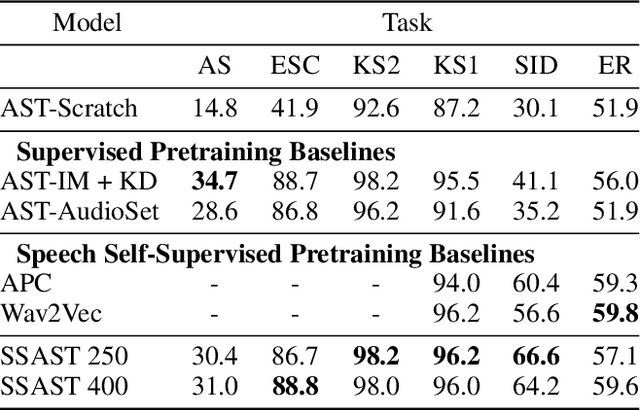
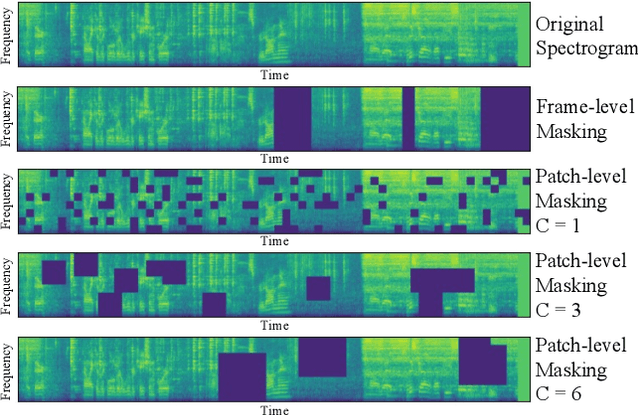
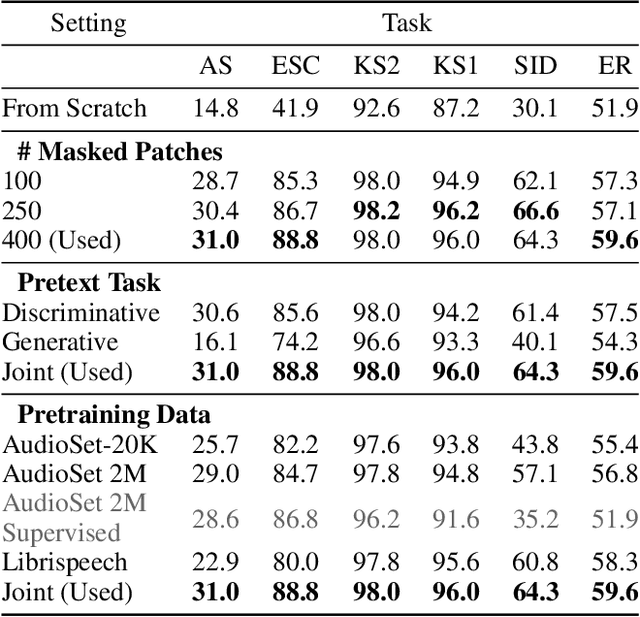
Recently, neural networks based purely on self-attention, such as the Vision Transformer (ViT), have been shown to outperform deep learning models constructed with convolutional neural networks (CNNs) on various vision tasks, thus extending the success of Transformers, which were originally developed for language processing, to the vision domain. A recent study showed that a similar methodology can also be applied to the audio domain. Specifically, the Audio Spectrogram Transformer (AST) achieves state-of-the-art results on various audio classification benchmarks. However, pure Transformer models tend to require more training data compared to CNNs, and the success of the AST relies on supervised pretraining that requires a large amount of labeled data and a complex training pipeline, thus limiting the practical usage of AST. This paper focuses on audio and speech classification, and aims to alleviate the data requirement issues with the AST by leveraging self-supervised learning using unlabeled data. Specifically, we propose to pretrain the AST model with joint discriminative and generative masked spectrogram patch modeling (MSPM) using unlabeled audio from AudioSet and Librispeech. We evaluate our pretrained models on both audio and speech classification tasks including audio event classification, keyword spotting, emotion recognition, and speaker identification. The proposed self-supervised framework significantly boosts AST performance on all tasks, with an average improvement of 60.9%, leading to similar or even better results than a supervised pretrained AST. To the best of our knowledge, it is the first patch-based self-supervised learning framework in the audio and speech domain, and also the first self-supervised learning framework for AST.