 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOUQuET: dataset, Benchmark and Open initiative for Universal Quality Evaluation in Translation
Feb 06, 2025



This paper presents BOUQuET, a multicentric and multi-register/domain dataset and benchmark, and its broader collaborative extension initiative. This dataset is handcrafted in non-English languages first, each of these source languages being represented among the 23 languages commonly used by half of the world's population and therefore having the potential to serve as pivot languages that will enable more accurate translations. The dataset is specially designed to avoid contamination and be multicentric, so as to enforce representation of multilingual language features. In addition, the dataset goes beyond the sentence level, as it is organized in paragraphs of various lengths. Compared with related machine translation (MT) datasets, we show that BOUQuET has a broader representation of domains while simplifying the translation task for non-experts. Therefore, BOUQuET is specially suitable for the open initiative and call for translation participation that we are launching to extend it to a multi-way parallel corpus to any written language.
LCFO: Long Context and Long Form Output Dataset and Benchmarking
Dec 12, 2024



This paper presents the Long Context and Form Output (LCFO) benchmark, a novel evaluation framework for assessing gradual summarization and summary expansion capabilities across diverse domains. LCFO consists of long input documents (5k words average length), each of which comes with three summaries of different lengths (20%, 10%, and 5% of the input text), as well as approximately 15 questions and answers (QA) related to the input content. Notably, LCFO also provides alignments between specific QA pairs and corresponding summaries in 7 domains. The primary motivation behind providing summaries of different lengths is to establish a controllable framework for generating long texts from shorter inputs, i.e. summary expansion. To establish an evaluation metric framework for summarization and summary expansion, we provide human evaluation scores for human-generated outputs, as well as results from various state-of-the-art large language models (LLMs). GPT-4o-mini achieves best human scores among automatic systems in both summarization and summary expansion tasks (~ +10% and +20%, respectively). It even surpasses human output quality in the case of short summaries (~ +7%). Overall automatic metrics achieve low correlations with human evaluation scores (~ 0.4) but moderate correlation on specific evaluation aspects such as fluency and attribution (~ 0.6). The LCFO benchmark offers a standardized platform for evaluating summarization and summary expansion performance, as well as corresponding automatic metrics, thereby providing an important evaluation framework to advance generative AI.
On the Role of Speech Data in Reducing Toxicity Detection Bias
Nov 12, 2024
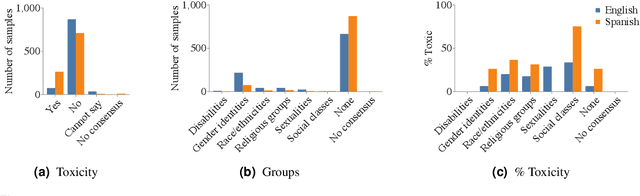
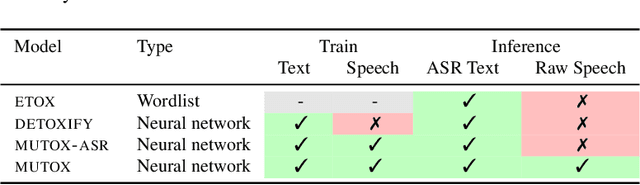
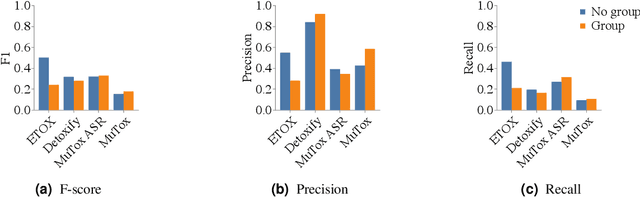
Text toxicity detection systems exhibit significant biases, producing disproportionate rates of false positives on samples mentioning demographic groups. But what about toxicity detection in speech? To investigate the extent to which text-based biases are mitigated by speech-based systems, we produce a set of high-quality group annotations for the multilingual MuTox dataset, and then leverage these annotations to systematically compare speech- and text-based toxicity classifiers. Our findings indicate that access to speech data during inference supports reduced bias against group mentions, particularly for ambiguous and disagreement-inducing samples. Our results also suggest that improving classifiers, rather than transcription pipelines, is more helpful for reducing group bias. We publicly release our annotations and provide recommendations for future toxicity dataset construction.
MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Jan 10, 2024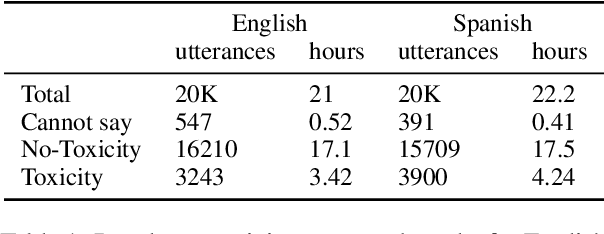
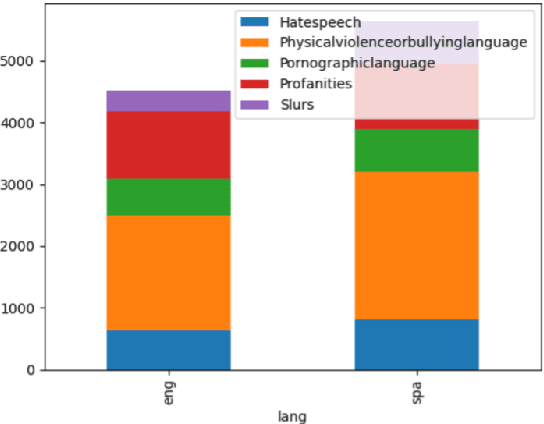
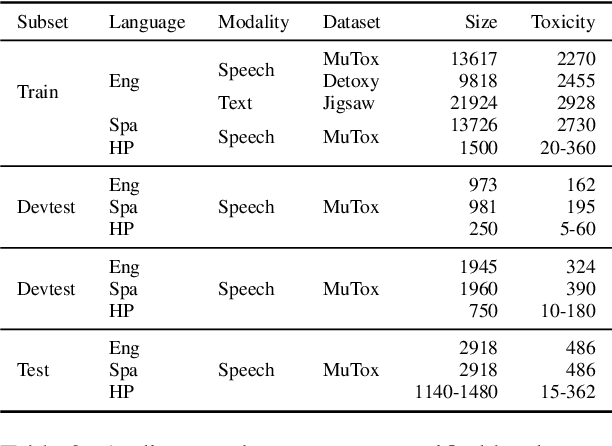
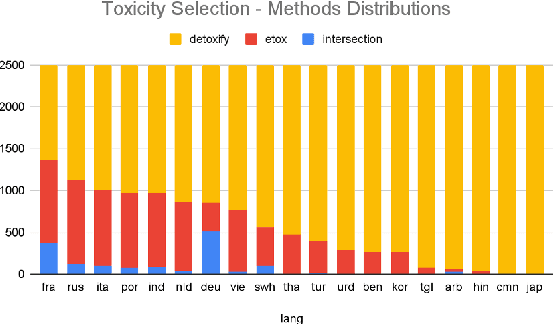
Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication