 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate, then Detect: Leveraging Machine Translation for Cross-Lingual Toxicity Classification
Sep 17, 2025



Multilingual toxicity detection remains a significant challenge due to the scarcity of training data and resources for many languages. While prior work has leveraged the translate-test paradigm to support cross-lingual transfer across a range of classification tasks, the utility of translation in supporting toxicity detection at scale remains unclear. In this work, we conduct a comprehensive comparison of translation-based and language-specific/multilingual classification pipelines. We find that translation-based pipelines consistently outperform out-of-distribution classifiers in 81.3% of cases (13 of 16 languages), with translation benefits strongly correlated with both the resource level of the target language and the quality of the machine translation (MT) system. Our analysis reveals that traditional classifiers outperform large language model (LLM) judges, with this advantage being particularly pronounced for low-resource languages, where translate-classify methods dominate translate-judge approaches in 6 out of 7 cases. We additionally show that MT-specific fine-tuning on LLMs yields lower refusal rates compared to standard instruction-tuned models, but it can negatively impact toxicity detection accuracy for low-resource languages. These findings offer actionable guidance for practitioners developing scalable multilingual content moderation systems.
Instructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025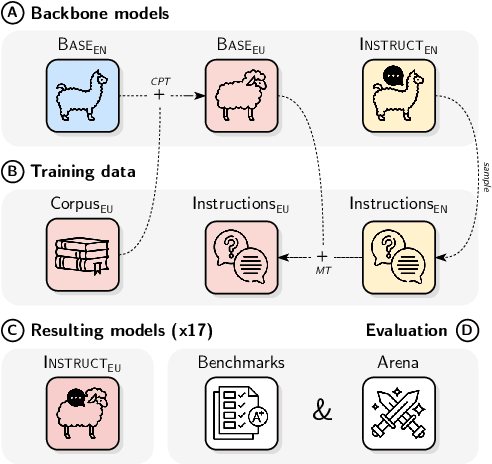
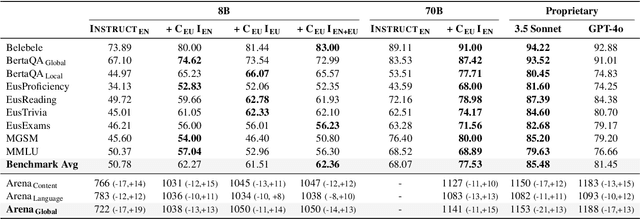
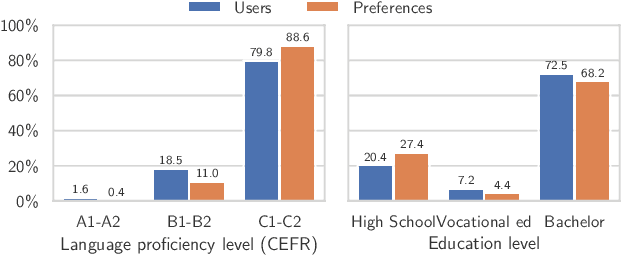

Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
WiCkeD: A Simple Method to Make Multiple Choice Benchmarks More Challenging
Feb 25, 2025We introduce WiCkeD, a simple method to increase the complexity of existing multiple-choice benchmarks by randomly replacing a choice with "None of the above", a method often used in educational tests. We show that WiCkeD can be automatically applied to any existing benchmark, making it more challenging. We apply WiCkeD to 6 popular benchmarks and use it to evaluate 18 open-weight LLMs. The performance of the models drops 12.1 points on average with respect to the original versions of the datasets. When using chain-of-thought on 3 MMLU datasets, the performance drop for the WiCkeD variant is similar to the one observed when using the LLMs directly, showing that WiCkeD is also challenging for models with enhanced reasoning abilities. WiCkeD also uncovers that some models are more sensitive to the extra reasoning required, providing additional information with respect to the original benchmarks. We relase our code and data at https://github.com/ahmedselhady/wicked-benchmarks.
BOUQuET: dataset, Benchmark and Open initiative for Universal Quality Evaluation in Translation
Feb 06, 2025



This paper presents BOUQuET, a multicentric and multi-register/domain dataset and benchmark, and its broader collaborative extension initiative. This dataset is handcrafted in non-English languages first, each of these source languages being represented among the 23 languages commonly used by half of the world's population and therefore having the potential to serve as pivot languages that will enable more accurate translations. The dataset is specially designed to avoid contamination and be multicentric, so as to enforce representation of multilingual language features. In addition, the dataset goes beyond the sentence level, as it is organized in paragraphs of various lengths. Compared with related machine translation (MT) datasets, we show that BOUQuET has a broader representation of domains while simplifying the translation task for non-experts. Therefore, BOUQuET is specially suitable for the open initiative and call for translation participation that we are launching to extend it to a multi-way parallel corpus to any written language.
Linguini: A benchmark for language-agnostic linguistic reasoning
Sep 18, 2024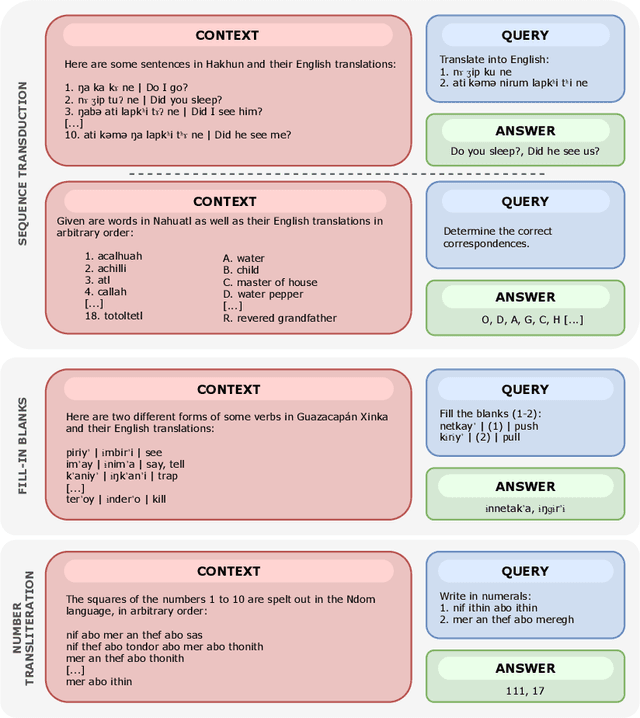
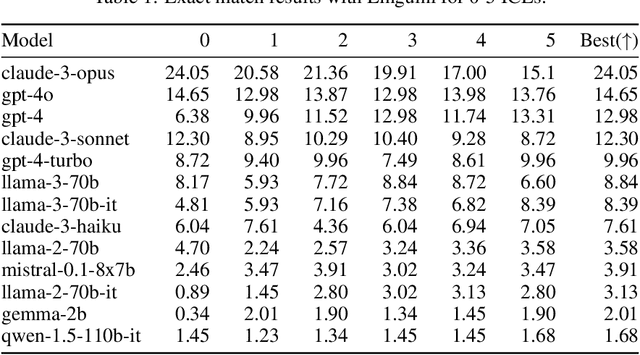

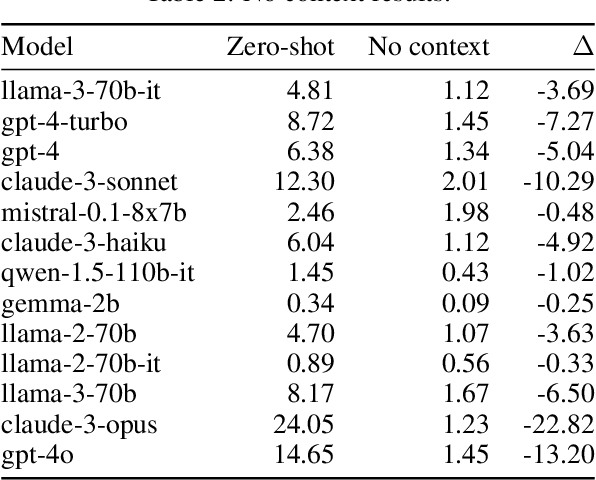
We propose a new benchmark to measure a language model's linguistic reasoning skills without relying on pre-existing language-specific knowledge. The test covers 894 questions grouped in 160 problems across 75 (mostly) extremely low-resource languages, extracted from the International Linguistic Olympiad corpus. To attain high accuracy on this benchmark, models don't need previous knowledge of the tested language, as all the information needed to solve the linguistic puzzle is presented in the context. We find that, while all analyzed models rank below 25% accuracy, there is a significant gap between open and closed models, with the best-performing proprietary model at 24.05% and the best-performing open model at 8.84%.
BertaQA: How Much Do Language Models Know About Local Culture?
Jun 11, 2024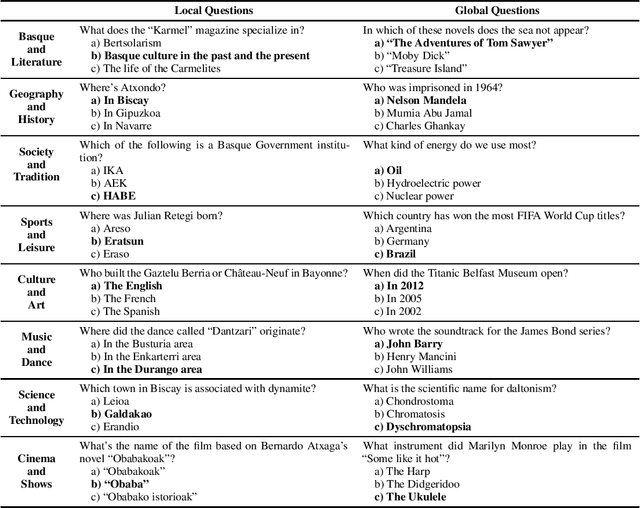
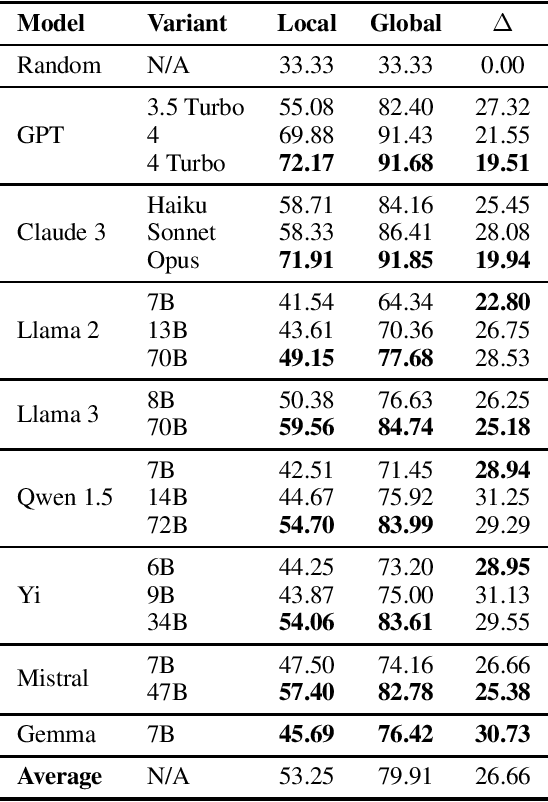
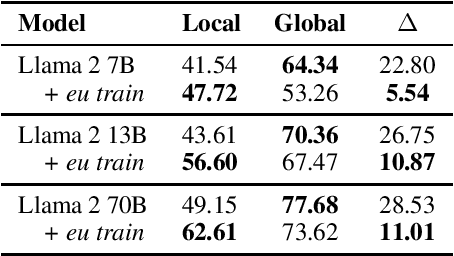
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models perform on topics relevant to other cultures, whose presence on the web is not that prominent. To address this gap, we introduce BertaQA, a multiple-choice trivia dataset that is parallel in English and Basque. The dataset consists of a local subset with questions pertinent to the Basque culture, and a global subset with questions of broader interest. We find that state-of-the-art LLMs struggle with local cultural knowledge, even as they excel on global topics. However, we show that continued pre-training in Basque significantly improves the models' performance on Basque culture, even when queried in English. To our knowledge, this is the first solid evidence of knowledge transfer from a low-resource to a high-resource language. Our analysis sheds light on the complex interplay between language and knowledge, and reveals that some prior findings do not fully hold when reassessed on local topics. Our dataset and evaluation code are available under open licenses at https://github.com/juletx/BertaQA.
Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
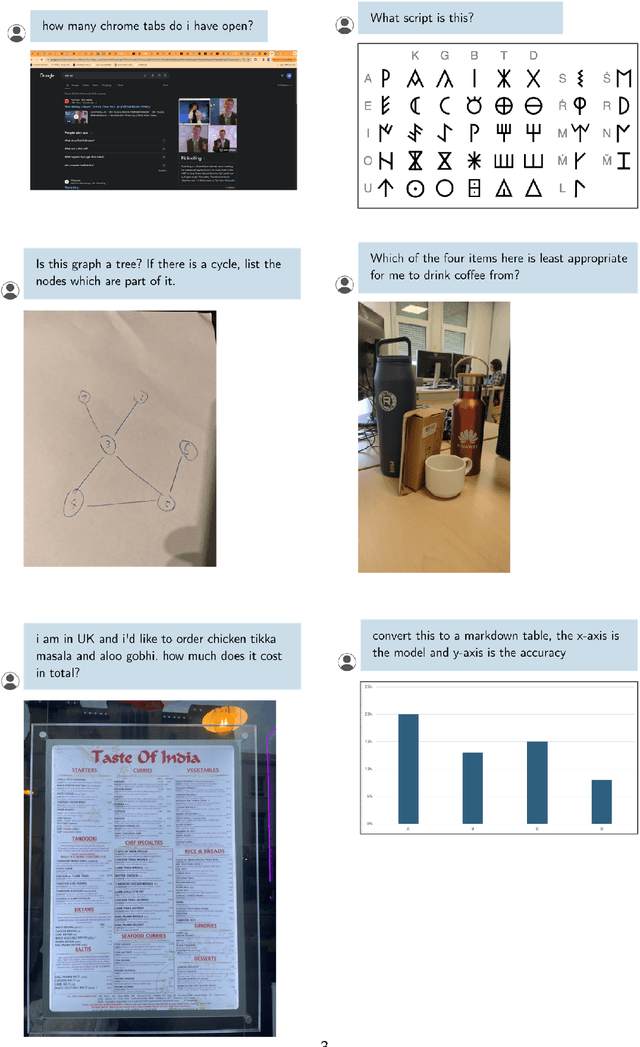
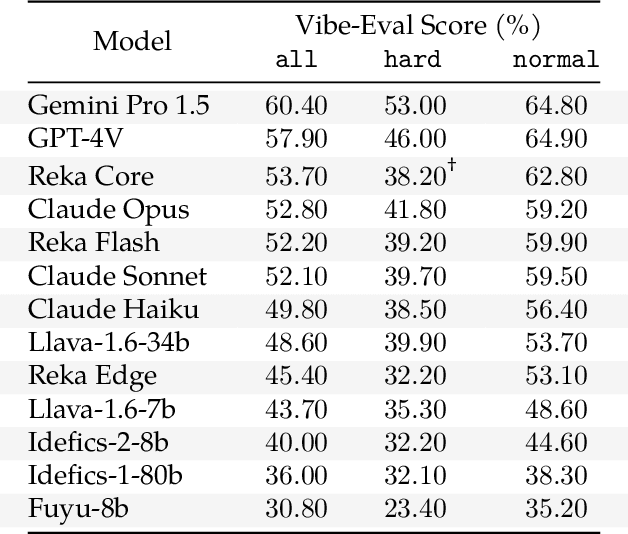
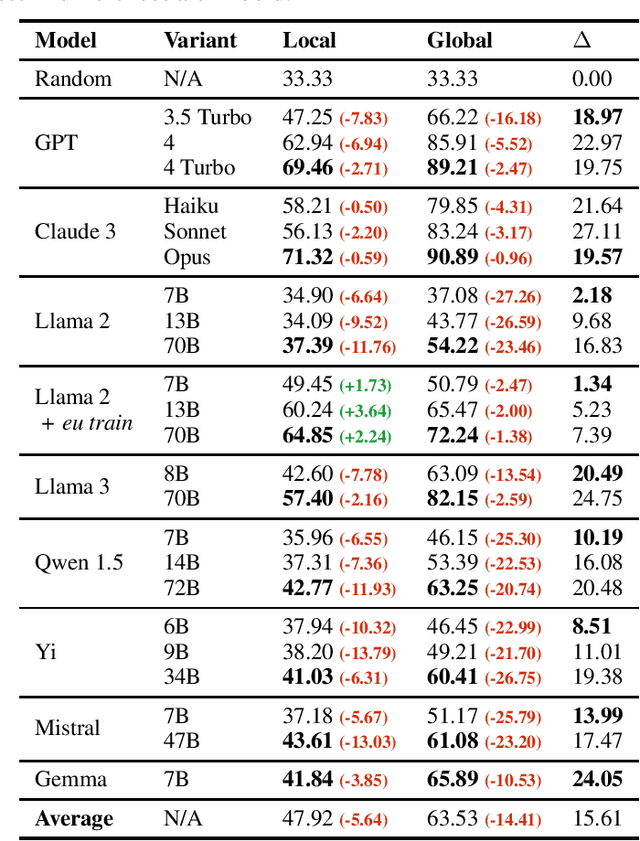
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024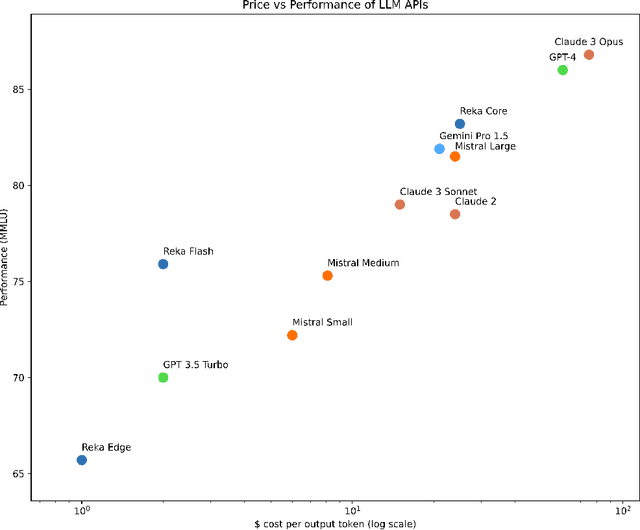


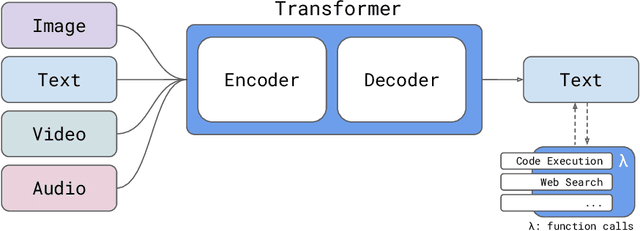
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Latxa: An Open Language Model and Evaluation Suite for Basque
Mar 29, 2024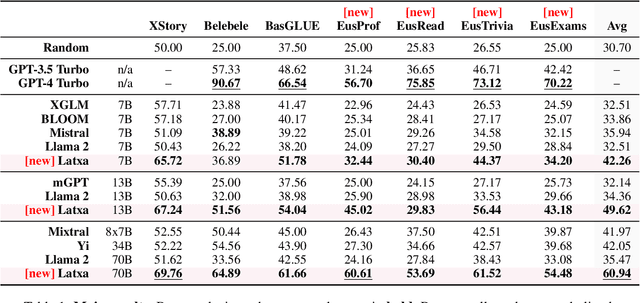
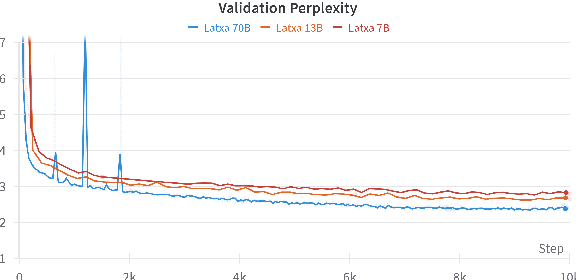
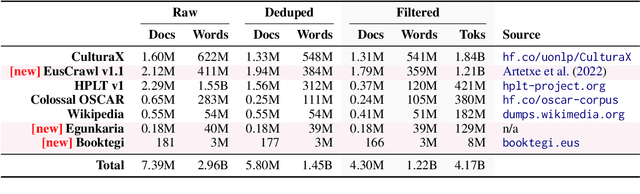
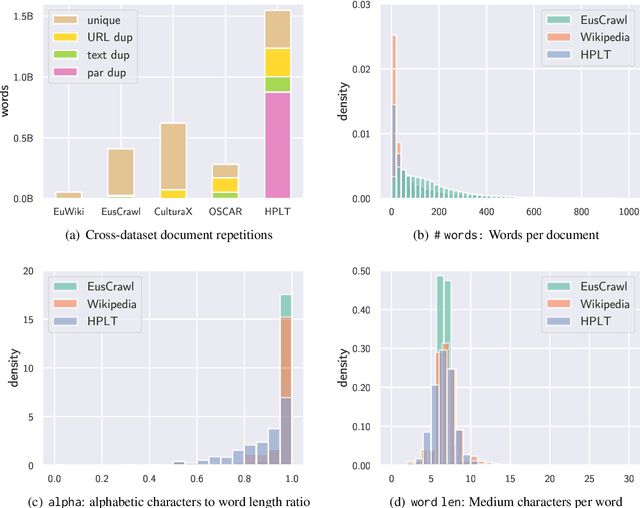
We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
Gender-specific Machine Translation with Large Language Models
Sep 06, 2023

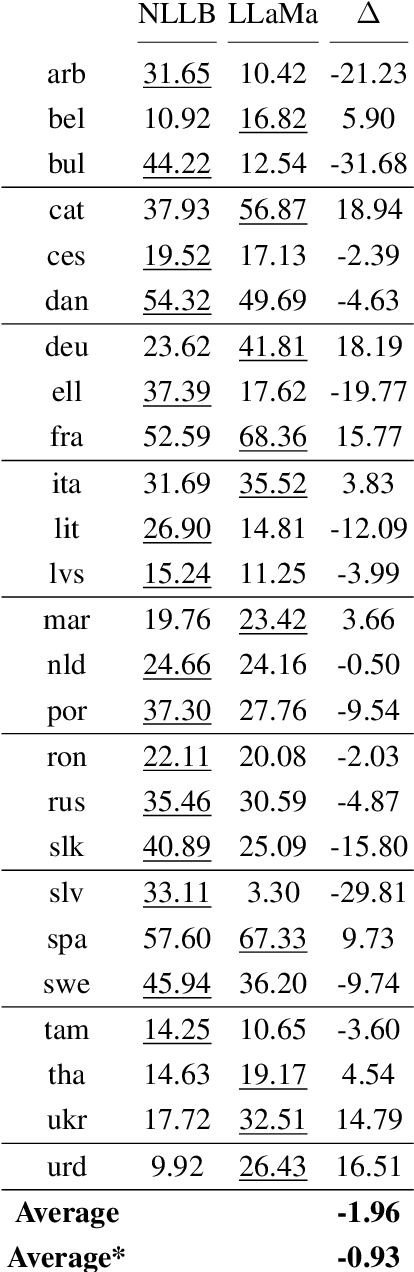
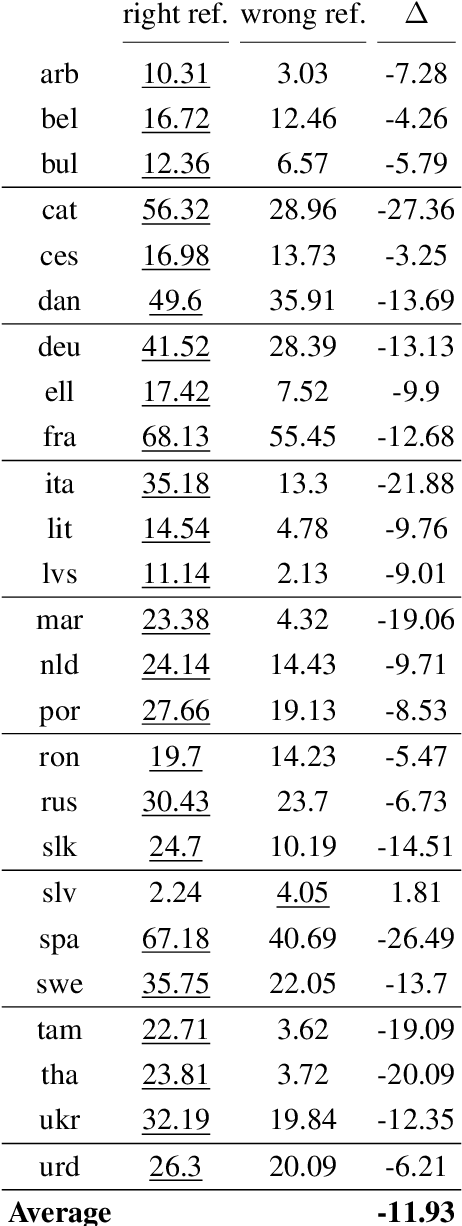
Decoder-only Large Language Models (LLMs) have demonstrated potential in machine translation (MT), albeit with performance slightly lagging behind traditional encoder-decoder Neural Machine Translation (NMT) systems. However, LLMs offer a unique advantage: the ability to control the properties of the output through prompts. In this study, we harness this flexibility to explore LLaMa's capability to produce gender-specific translations for languages with grammatical gender. Our results indicate that LLaMa can generate gender-specific translations with competitive accuracy and gender bias mitigation when compared to NLLB, a state-of-the-art multilingual NMT system. Furthermore, our experiments reveal that LLaMa's translations are robust, showing significant performance drops when evaluated against opposite-gender references in gender-ambiguous datasets but maintaining consistency in less ambiguous contexts. This research provides insights into the potential and challenges of using LLMs for gender-specific translations and highlights the importance of in-context learning to elicit new tasks in LLMs.