 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo not be greedy, Think Twice: Sampling and Selection for Document-level Information Extraction
Jan 26, 2026Document-level Information Extraction (DocIE) aims to produce an output template with the entities and relations of interest occurring in the given document. Standard practices include prompting decoder-only LLMs using greedy decoding to avoid output variability. Rather than treating this variability as a limitation, we show that sampling can produce substantially better solutions than greedy decoding, especially when using reasoning models. We thus propose ThinkTwice, a sampling and selection framework in which the LLM generates multiple candidate templates for a given document, and a selection module chooses the most suitable one. We introduce both an unsupervised method that exploits agreement across generated outputs, and a supervised selection method using reward models trained on labeled DocIE data. To address the scarcity of golden reasoning trajectories for DocIE, we propose a rejection-sampling-based method to generate silver training data that pairs output templates with reasoning traces. Our experiments show the validity of unsupervised and supervised ThinkTwice, consistently outperforming greedy baselines and the state-of-the-art.
Automatic Essay Scoring and Feedback Generation in Basque Language Learning
Dec 09, 2025This paper introduces the first publicly available dataset for Automatic Essay Scoring (AES) and feedback generation in Basque, targeting the CEFR C1 proficiency level. The dataset comprises 3,200 essays from HABE, each annotated by expert evaluators with criterion specific scores covering correctness, richness, coherence, cohesion, and task alignment enriched with detailed feedback and error examples. We fine-tune open-source models, including RoBERTa-EusCrawl and Latxa 8B/70B, for both scoring and explanation generation. Our experiments show that encoder models remain highly reliable for AES, while supervised fine-tuning (SFT) of Latxa significantly enhances performance, surpassing state-of-the-art (SoTA) closed-source systems such as GPT-5 and Claude Sonnet 4.5 in scoring consistency and feedback quality. We also propose a novel evaluation methodology for assessing feedback generation, combining automatic consistency metrics with expert-based validation of extracted learner errors. Results demonstrate that the fine-tuned Latxa model produces criterion-aligned, pedagogically meaningful feedback and identifies a wider range of error types than proprietary models. This resource and benchmark establish a foundation for transparent, reproducible, and educationally grounded NLP research in low-resource languages such as Basque.
REMoH: A Reflective Evolution of Multi-objective Heuristics approach via Large Language Models
Jun 09, 2025



Multi-objective optimization is fundamental in complex decision-making tasks. Traditional algorithms, while effective, often demand extensive problem-specific modeling and struggle to adapt to nonlinear structures. Recent advances in Large Language Models (LLMs) offer enhanced explainability, adaptability, and reasoning. This work proposes Reflective Evolution of Multi-objective Heuristics (REMoH), a novel framework integrating NSGA-II with LLM-based heuristic generation. A key innovation is a reflection mechanism that uses clustering and search-space reflection to guide the creation of diverse, high-quality heuristics, improving convergence and maintaining solution diversity. The approach is evaluated on the Flexible Job Shop Scheduling Problem (FJSSP) in-depth benchmarking against state-of-the-art methods using three instance datasets: Dauzere, Barnes, and Brandimarte. Results demonstrate that REMoH achieves competitive results compared to state-of-the-art approaches with reduced modeling effort and enhanced adaptability. These findings underscore the potential of LLMs to augment traditional optimization, offering greater flexibility, interpretability, and robustness in multi-objective scenarios.
Vision-Language Models Struggle to Align Entities across Modalities
Mar 05, 2025Cross-modal entity linking refers to the ability to align entities and their attributes across different modalities. While cross-modal entity linking is a fundamental skill needed for real-world applications such as multimodal code generation, fake news detection, or scene understanding, it has not been thoroughly studied in the literature. In this paper, we introduce a new task and benchmark to address this gap. Our benchmark, MATE, consists of 5.5k evaluation instances featuring visual scenes aligned with their textual representations. To evaluate cross-modal entity linking performance, we design a question-answering task that involves retrieving one attribute of an object in one modality based on a unique attribute of that object in another modality. We evaluate state-of-the-art Vision-Language Models (VLMs) and humans on this task, and find that VLMs struggle significantly compared to humans, particularly as the number of objects in the scene increases. Our analysis also shows that, while chain-of-thought prompting can improve VLM performance, models remain far from achieving human-level proficiency. These findings highlight the need for further research in cross-modal entity linking and show that MATE is a strong benchmark to support that progress.
BertaQA: How Much Do Language Models Know About Local Culture?
Jun 11, 2024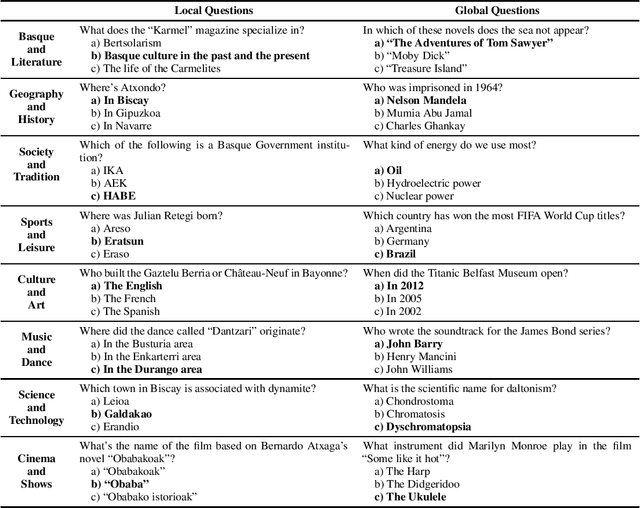
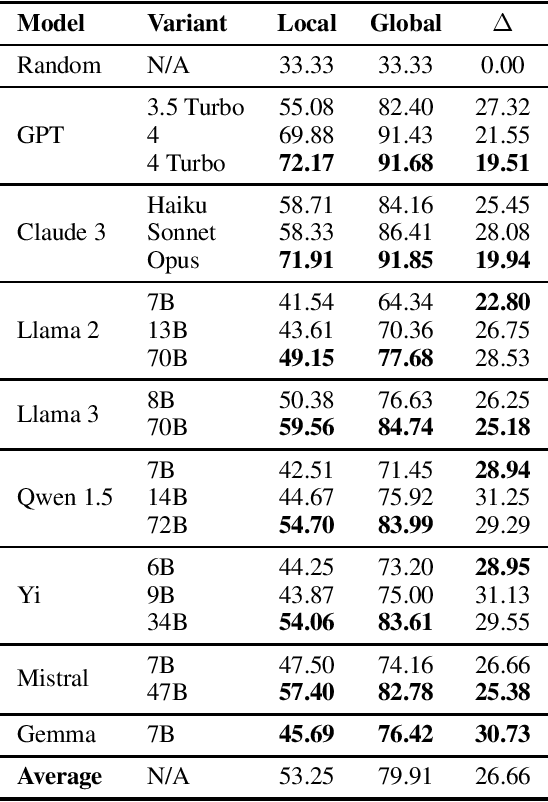
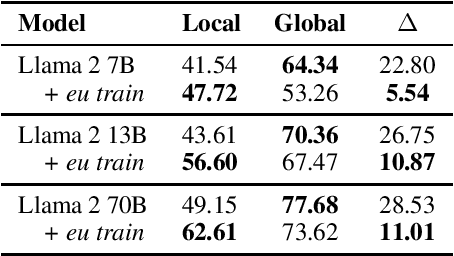
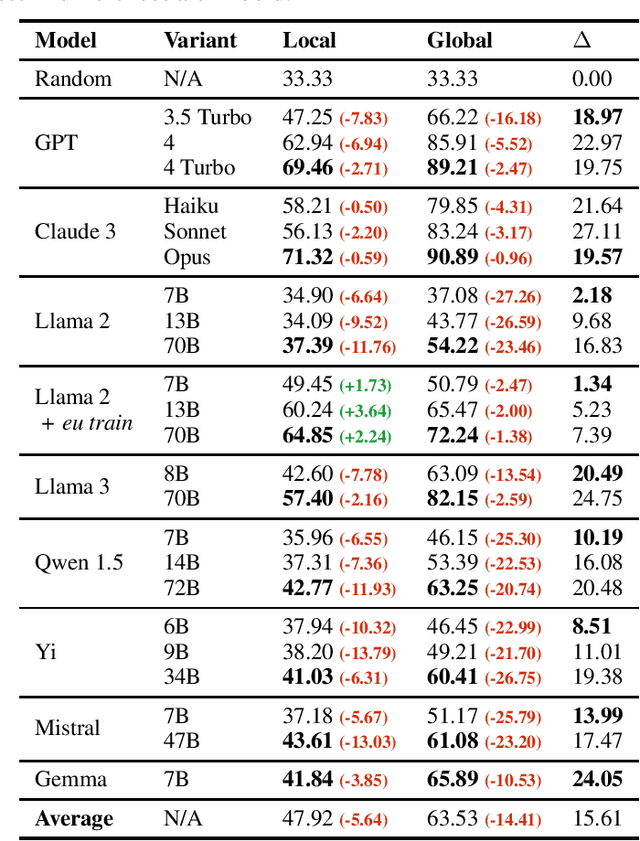
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models perform on topics relevant to other cultures, whose presence on the web is not that prominent. To address this gap, we introduce BertaQA, a multiple-choice trivia dataset that is parallel in English and Basque. The dataset consists of a local subset with questions pertinent to the Basque culture, and a global subset with questions of broader interest. We find that state-of-the-art LLMs struggle with local cultural knowledge, even as they excel on global topics. However, we show that continued pre-training in Basque significantly improves the models' performance on Basque culture, even when queried in English. To our knowledge, this is the first solid evidence of knowledge transfer from a low-resource to a high-resource language. Our analysis sheds light on the complex interplay between language and knowledge, and reveals that some prior findings do not fully hold when reassessed on local topics. Our dataset and evaluation code are available under open licenses at https://github.com/juletx/BertaQA.
Event Extraction in Basque: Typologically motivated Cross-Lingual Transfer-Learning Analysis
Apr 09, 2024Cross-lingual transfer-learning is widely used in Event Extraction for low-resource languages and involves a Multilingual Language Model that is trained in a source language and applied to the target language. This paper studies whether the typological similarity between source and target languages impacts the performance of cross-lingual transfer, an under-explored topic. We first focus on Basque as the target language, which is an ideal target language because it is typologically different from surrounding languages. Our experiments on three Event Extraction tasks show that the shared linguistic characteristic between source and target languages does have an impact on transfer quality. Further analysis of 72 language pairs reveals that for tasks that involve token classification such as entity and event trigger identification, common writing script and morphological features produce higher quality cross-lingual transfer. In contrast, for tasks involving structural prediction like argument extraction, common word order is the most relevant feature. In addition, we show that when increasing the training size, not all the languages scale in the same way in the cross-lingual setting. To perform the experiments we introduce EusIE, an event extraction dataset for Basque, which follows the Multilingual Event Extraction dataset (MEE). The dataset and code are publicly available.
Improving Explicit Spatial Relationships in Text-to-Image Generation through an Automatically Derived Dataset
Mar 01, 2024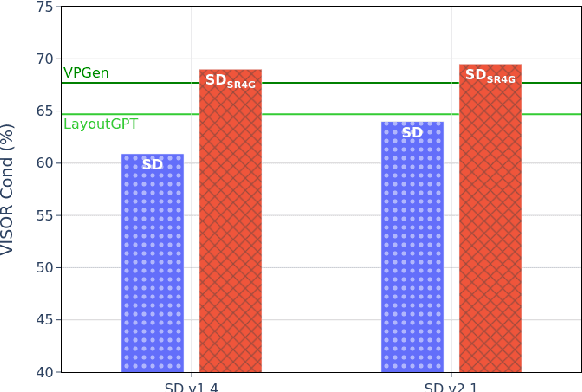
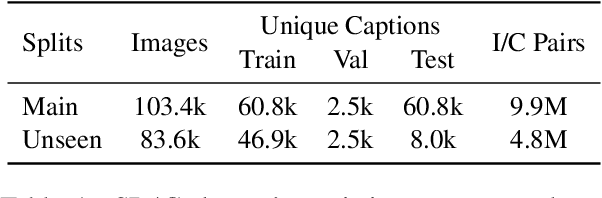

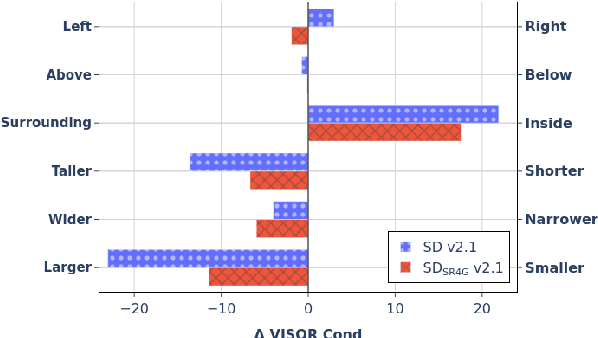
Existing work has observed that current text-to-image systems do not accurately reflect explicit spatial relations between objects such as 'left of' or 'below'. We hypothesize that this is because explicit spatial relations rarely appear in the image captions used to train these models. We propose an automatic method that, given existing images, generates synthetic captions that contain 14 explicit spatial relations. We introduce the Spatial Relation for Generation (SR4G) dataset, which contains 9.9 millions image-caption pairs for training, and more than 60 thousand captions for evaluation. In order to test generalization we also provide an 'unseen' split, where the set of objects in the train and test captions are disjoint. SR4G is the first dataset that can be used to spatially fine-tune text-to-image systems. We show that fine-tuning two different Stable Diffusion models (denoted as SD$_{SR4G}$) yields up to 9 points improvements in the VISOR metric. The improvement holds in the 'unseen' split, showing that SD$_{SR4G}$ is able to generalize to unseen objects. SD$_{SR4G}$ improves the state-of-the-art with fewer parameters, and avoids complex architectures. Our analysis shows that improvement is consistent for all relations. The dataset and the code will be publicly available.
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Oct 27, 2023In this position paper, we argue that the classical evaluation on Natural Language Processing (NLP) tasks using annotated benchmarks is in trouble. The worst kind of data contamination happens when a Large Language Model (LLM) is trained on the test split of a benchmark, and then evaluated in the same benchmark. The extent of the problem is unknown, as it is not straightforward to measure. Contamination causes an overestimation of the performance of a contaminated model in a target benchmark and associated task with respect to their non-contaminated counterparts. The consequences can be very harmful, with wrong scientific conclusions being published while other correct ones are discarded. This position paper defines different levels of data contamination and argues for a community effort, including the development of automatic and semi-automatic measures to detect when data from a benchmark was exposed to a model, and suggestions for flagging papers with conclusions that are compromised by data contamination.
GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction
Oct 06, 2023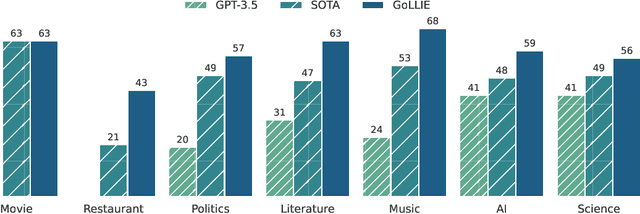
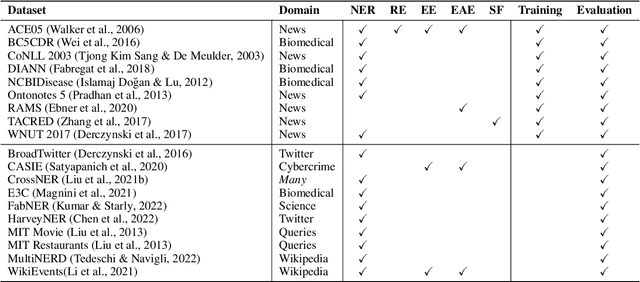

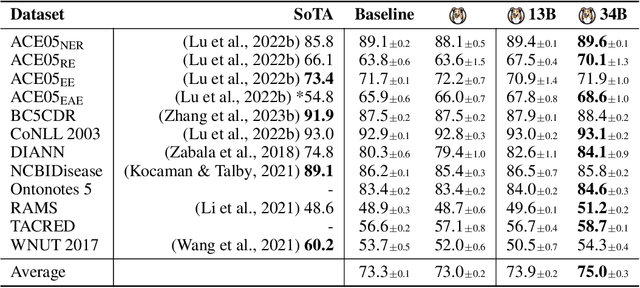
Large Language Models (LLMs) combined with instruction tuning have made significant progress when generalizing to unseen tasks. However, they have been less successful in Information Extraction (IE), lagging behind task-specific models. Typically, IE tasks are characterized by complex annotation guidelines which describe the task and give examples to humans. Previous attempts to leverage such information have failed, even with the largest models, as they are not able to follow the guidelines out-of-the-box. In this paper we propose GoLLIE (Guideline-following Large Language Model for IE), a model able to improve zero-shot results on unseen IE tasks by virtue of being fine-tuned to comply with annotation guidelines. Comprehensive evaluation empirically demonstrates that GoLLIE is able to generalize to and follow unseen guidelines, outperforming previous attempts at zero-shot information extraction. The ablation study shows that detailed guidelines is key for good results.
Do Multilingual Language Models Think Better in English?
Aug 02, 2023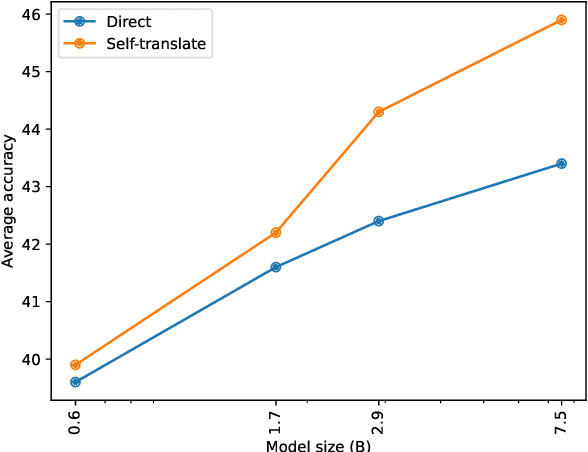

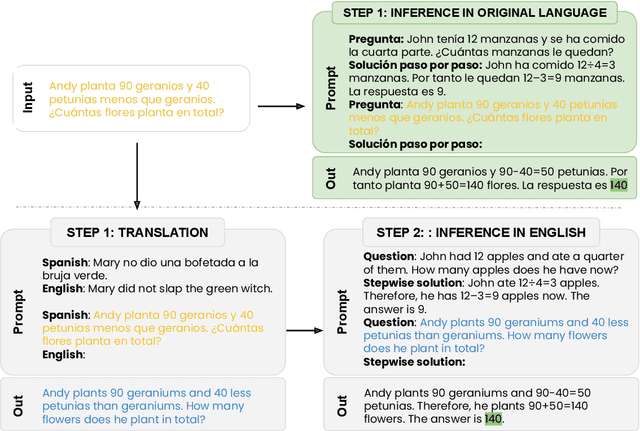

Translate-test is a popular technique to improve the performance of multilingual language models. This approach works by translating the input into English using an external machine translation system, and running inference over the translated input. However, these improvements can be attributed to the use of a separate translation system, which is typically trained on large amounts of parallel data not seen by the language model. In this work, we introduce a new approach called self-translate, which overcomes the need of an external translation system by leveraging the few-shot translation capabilities of multilingual language models. Experiments over 5 tasks show that self-translate consistently outperforms direct inference, demonstrating that language models are unable to leverage their full multilingual potential when prompted in non-English languages. Our code is available at https://github.com/juletx/self-translate.