 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Correctly Make Mistakes: A Framework for Constructing and Benchmarking Mistake Aware Egocentric Procedural Videos
Apr 16, 2026Reliable procedural monitoring in video requires exposure to naturally occurring human errors and the recoveries that follow. In egocentric recordings, mistakes are often partially occluded by hands and revealed through subtle object state changes, while existing procedural datasets provide limited and inconsistent mistake and correction traces. We present PIE-V (Psychologically Inspired Error injection for Videos), a framework for constructing and benchmarking mistake-aware egocentric procedural videos by augmenting clean keystep procedures with controlled, human-plausible deviations. PIE-V combines a psychology-informed error planner conditioned on procedure phase and semantic step load, a correction planner that models recovery behavior, an LLM writer that performs cascade-consistent rewrites, and an LLM judge that validates procedural coherence and repairs failures. For video segment edits, PIE-V synthesizes replacement clips with text-guided video generation and stitches them into the episode to preserve visual plausibility. Applied to 17 tasks and 50 Ego-Exo4D scenarios, PIE-V injects 102 mistakes and generates 27 recovery corrections. For benchmarking, we introduce a unified taxonomy and a human rubric with nine metrics that cover step-level and procedure-level quality, including plausibility, procedure logic with annotator confidence, state change coherence, and grounding between text and video. Using this protocol, we audit several existing resources and compare PIE-V against a freeform LLM generation baseline under the same criteria. Together, the framework and rubric support post-completion verification for egocentric procedural mistake detection and correction.
MIXAR: Scaling Autoregressive Pixel-based Language Models to Multiple Languages and Scripts
Apr 13, 2026Pixel-based language models are gaining momentum as alternatives to traditional token-based approaches, promising to circumvent tokenization challenges. However, the inherent perceptual diversity across languages poses a significant hurdle for multilingual generalization in pixel space. This paper introduces MIXAR, the first generative pixel-based language model trained on eight different languages utilizing a range of different scripts. We empirically evaluate MIXAR against previous pixel-based models as well as comparable tokenizer-based models, demonstrating substantial performance improvement on discriminative and generative multilingual tasks. Additionally, we show how MIXAR is robust to languages never seen during the training. These results are further strengthened when scaling the model to 0.5B parameters which not only improves its capabilities in generative tasks like LAMBADA but also its robustness when challenged with input perturbations such as orthographic attacks.
Think Before you Write: QA-Guided Reasoning for Character Descriptions in Books
Apr 13, 2026Character description generation is an important capability for narrative-focused applications such as summarization, story analysis, and character-driven simulations. However, generating accurate character descriptions from long-form narratives (e.g., novels) is challenging: models must track evolving attributes (e.g., relationships and events), integrate evidence scattered across the text, and infer implicit details. Despite the success of reasoning-enabled LLMs on many benchmarks, we find that for character description generation their performance improves when built-in reasoning is disabled (i.e., an empty reasoning trace). Motivated by this, we propose a training framework that decouples reasoning from generation. Our approach, which can be applied on top of long-context LLMs or chunk-based methods, consists of a reasoning model that produces a structured QA reasoning trace and a generation model that conditions on this trace to produce the final character description. Experiments on two datasets (BookWorm and CroSS) show that QA-guided reasoning improves faithfulness, informativeness, and grounding over strong long-context baselines.
Contrastive Learning with Narrative Twins for Modeling Story Salience
Jan 12, 2026Understanding narratives requires identifying which events are most salient for a story's progression. We present a contrastive learning framework for modeling narrative salience that learns story embeddings from narrative twins: stories that share the same plot but differ in surface form. Our model is trained to distinguish a story from both its narrative twin and a distractor with similar surface features but different plot. Using the resulting embeddings, we evaluate four narratologically motivated operations for inferring salience (deletion, shifting, disruption, and summarization). Experiments on short narratives from the ROCStories corpus and longer Wikipedia plot summaries show that contrastively learned story embeddings outperform a masked-language-model baseline, and that summarization is the most reliable operation for identifying salient sentences. If narrative twins are not available, random dropout can be used to generate the twins from a single story. Effective distractors can be obtained either by prompting LLMs or, in long-form narratives, by using different parts of the same story.
Predicting Implicit Arguments in Procedural Video Instructions
May 27, 2025Procedural texts help AI enhance reasoning about context and action sequences. Transforming these into Semantic Role Labeling (SRL) improves understanding of individual steps by identifying predicate-argument structure like {verb,what,where/with}. Procedural instructions are highly elliptic, for instance, (i) add cucumber to the bowl and (ii) add sliced tomatoes, the second step's where argument is inferred from the context, referring to where the cucumber was placed. Prior SRL benchmarks often miss implicit arguments, leading to incomplete understanding. To address this, we introduce Implicit-VidSRL, a dataset that necessitates inferring implicit and explicit arguments from contextual information in multimodal cooking procedures. Our proposed dataset benchmarks multimodal models' contextual reasoning, requiring entity tracking through visual changes in recipes. We study recent multimodal LLMs and reveal that they struggle to predict implicit arguments of what and where/with from multi-modal procedural data given the verb. Lastly, we propose iSRL-Qwen2-VL, which achieves a 17% relative improvement in F1-score for what-implicit and a 14.7% for where/with-implicit semantic roles over GPT-4o.
PosterSum: A Multimodal Benchmark for Scientific Poster Summarization
Feb 24, 2025Generating accurate and concise textual summaries from multimodal documents is challenging, especially when dealing with visually complex content like scientific posters. We introduce PosterSum, a novel benchmark to advance the development of vision-language models that can understand and summarize scientific posters into research paper abstracts. Our dataset contains 16,305 conference posters paired with their corresponding abstracts as summaries. Each poster is provided in image format and presents diverse visual understanding challenges, such as complex layouts, dense text regions, tables, and figures. We benchmark state-of-the-art Multimodal Large Language Models (MLLMs) on PosterSum and demonstrate that they struggle to accurately interpret and summarize scientific posters. We propose Segment & Summarize, a hierarchical method that outperforms current MLLMs on automated metrics, achieving a 3.14% gain in ROUGE-L. This will serve as a starting point for future research on poster summarization.
End-to-End Long Document Summarization using Gradient Caching
Jan 03, 2025



Training transformer-based encoder-decoder models for long document summarization poses a significant challenge due to the quadratic memory consumption during training. Several approaches have been proposed to extend the input length at test time, but training with these approaches is still difficult, requiring truncation of input documents and causing a mismatch between training and test conditions. In this work, we propose CachED (Gradient $\textbf{Cach}$ing for $\textbf{E}$ncoder-$\textbf{D}$ecoder models), an approach that enables end-to-end training of existing transformer-based encoder-decoder models, using the entire document without truncation. Specifically, we apply non-overlapping sliding windows to input documents, followed by fusion in decoder. During backpropagation, the gradients are cached at the decoder and are passed through the encoder in chunks by re-computing the hidden vectors, similar to gradient checkpointing. In the experiments on long document summarization, we extend BART to CachED BART, processing more than 500K tokens during training and achieving superior performance without using any additional parameters.
Plancraft: an evaluation dataset for planning with LLM agents
Dec 30, 2024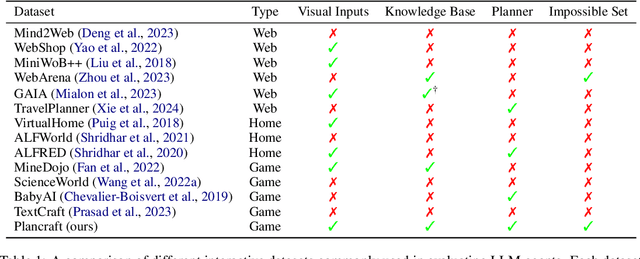


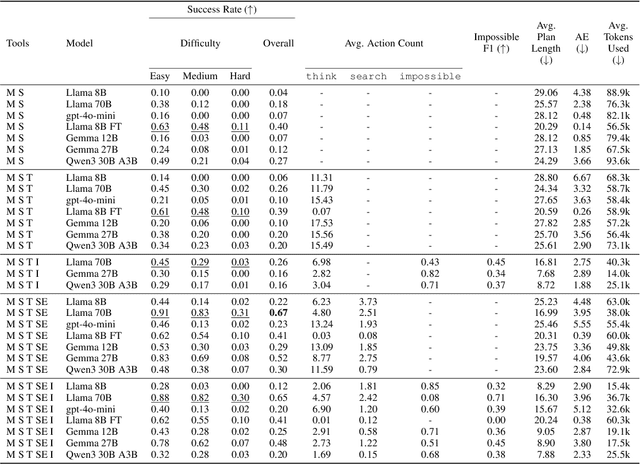
We present Plancraft, a multi-modal evaluation dataset for LLM agents. Plancraft has both a text-only and multi-modal interface, based on the Minecraft crafting GUI. We include the Minecraft Wiki to evaluate tool use and Retrieval Augmented Generation (RAG), as well as an oracle planner and oracle RAG information extractor, to ablate the different components of a modern agent architecture. To evaluate decision-making, Plancraft also includes a subset of examples that are intentionally unsolvable, providing a realistic challenge that requires the agent not only to complete tasks but also to decide whether they are solvable at all. We benchmark both open-source and closed-source LLMs and strategies on our task and compare their performance to a handcrafted planner. We find that LLMs and VLMs struggle with the planning problems that Plancraft introduces, and we offer suggestions on how to improve their capabilities.
BookWorm: A Dataset for Character Description and Analysis
Oct 14, 2024Characters are at the heart of every story, driving the plot and engaging readers. In this study, we explore the understanding of characters in full-length books, which contain complex narratives and numerous interacting characters. We define two tasks: character description, which generates a brief factual profile, and character analysis, which offers an in-depth interpretation, including character development, personality, and social context. We introduce the BookWorm dataset, pairing books from the Gutenberg Project with human-written descriptions and analyses. Using this dataset, we evaluate state-of-the-art long-context models in zero-shot and fine-tuning settings, utilizing both retrieval-based and hierarchical processing for book-length inputs. Our findings show that retrieval-based approaches outperform hierarchical ones in both tasks. Additionally, fine-tuned models using coreference-based retrieval produce the most factual descriptions, as measured by fact- and entailment-based metrics. We hope our dataset, experiments, and analysis will inspire further research in character-based narrative understanding.
MovieSum: An Abstractive Summarization Dataset for Movie Screenplays
Aug 12, 2024Movie screenplay summarization is challenging, as it requires an understanding of long input contexts and various elements unique to movies. Large language models have shown significant advancements in document summarization, but they often struggle with processing long input contexts. Furthermore, while television transcripts have received attention in recent studies, movie screenplay summarization remains underexplored. To stimulate research in this area, we present a new dataset, MovieSum, for abstractive summarization of movie screenplays. This dataset comprises 2200 movie screenplays accompanied by their Wikipedia plot summaries. We manually formatted the movie screenplays to represent their structural elements. Compared to existing datasets, MovieSum possesses several distinctive features: (1) It includes movie screenplays, which are longer than scripts of TV episodes. (2) It is twice the size of previous movie screenplay datasets. (3) It provides metadata with IMDb IDs to facilitate access to additional external knowledge. We also show the results of recently released large language models applied to summarization on our dataset to provide a detailed baseline.