 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025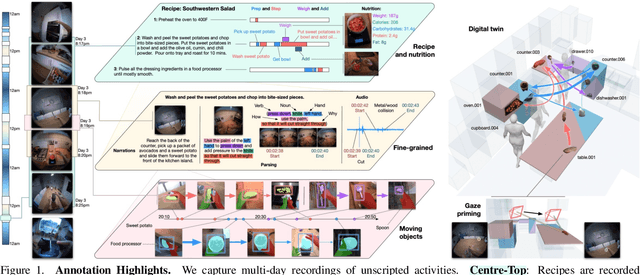
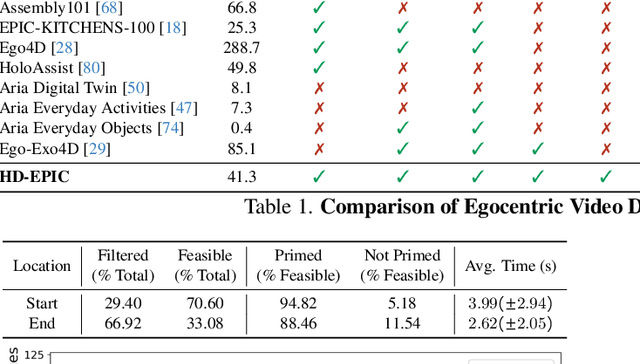

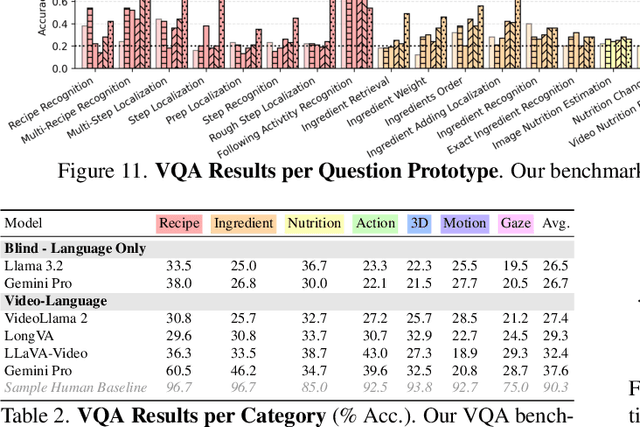
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Continual Learning Improves Zero-Shot Action Recognition
Oct 14, 2024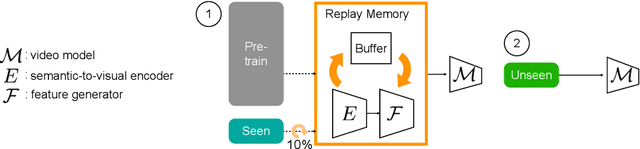
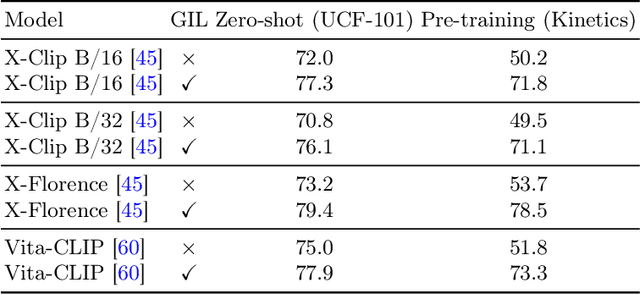

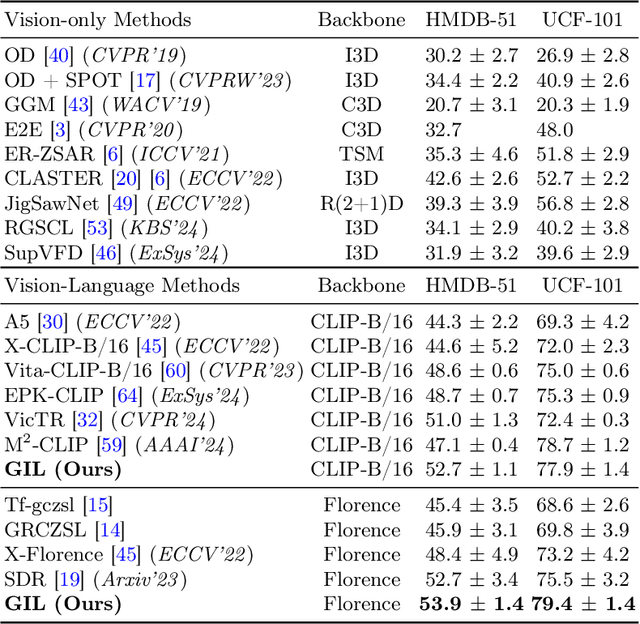
Zero-shot action recognition requires a strong ability to generalize from pre-training and seen classes to novel unseen classes. Similarly, continual learning aims to develop models that can generalize effectively and learn new tasks without forgetting the ones previously learned. The generalization goals of zero-shot and continual learning are closely aligned, however techniques from continual learning have not been applied to zero-shot action recognition. In this paper, we propose a novel method based on continual learning to address zero-shot action recognition. This model, which we call {\em Generative Iterative Learning} (GIL) uses a memory of synthesized features of past classes, and combines these synthetic features with real ones from novel classes. The memory is used to train a classification model, ensuring a balanced exposure to both old and new classes. Experiments demonstrate that {\em GIL} improves generalization in unseen classes, achieving a new state-of-the-art in zero-shot recognition across multiple benchmarks. Importantly, {\em GIL} also boosts performance in the more challenging generalized zero-shot setting, where models need to retain knowledge about classes seen before fine-tuning.
Coarse or Fine? Recognising Action End States without Labels
May 13, 2024We focus on the problem of recognising the end state of an action in an image, which is critical for understanding what action is performed and in which manner. We study this focusing on the task of predicting the coarseness of a cut, i.e., deciding whether an object was cut "coarsely" or "finely". No dataset with these annotated end states is available, so we propose an augmentation method to synthesise training data. We apply this method to cutting actions extracted from an existing action recognition dataset. Our method is object agnostic, i.e., it presupposes the location of the object but not its identity. Starting from less than a hundred images of a whole object, we can generate several thousands images simulating visually diverse cuts of different coarseness. We use our synthetic data to train a model based on UNet and test it on real images showing coarsely/finely cut objects. Results demonstrate that the model successfully recognises the end state of the cutting action despite the domain gap between training and testing, and that the model generalises well to unseen objects.
Efficient Pre-training for Localized Instruction Generation of Videos
Nov 27, 2023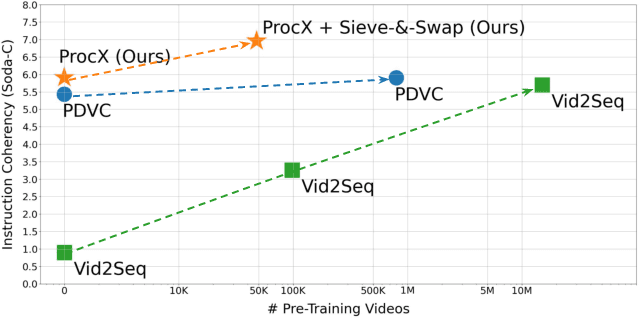


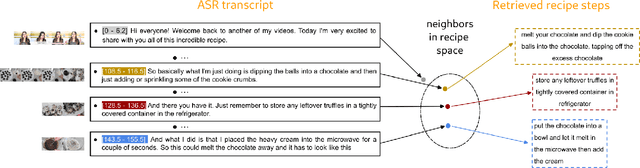
Procedural videos show step-by-step demonstrations of tasks like recipe preparation. Understanding such videos is challenging, involving the precise localization of steps and the generation of textual instructions. Manually annotating steps and writing instructions is costly, which limits the size of current datasets and hinders effective learning. Leveraging large but noisy video-transcript datasets for pre-training can boost performance, but demands significant computational resources. Furthermore, transcripts contain irrelevant content and exhibit style variation compared to instructions written by human annotators. To mitigate both issues, we propose a technique, Sieve-&-Swap, to automatically curate a smaller dataset: (i) Sieve filters irrelevant transcripts and (ii) Swap enhances the quality of the text instruction by automatically replacing the transcripts with human-written instructions from a text-only recipe dataset. The curated dataset, three orders of magnitude smaller than current web-scale datasets, enables efficient training of large-scale models with competitive performance. We complement our Sieve-\&-Swap approach with a Procedure Transformer (ProcX) for end-to-end step localization and instruction generation for procedural videos. When this model is pre-trained on our curated dataset, it achieves state-of-the-art performance in zero-shot and finetuning settings on YouCook2 and Tasty, while using a fraction of the computational resources.
Learning Action Changes by Measuring Verb-Adverb Textual Relationships
Mar 27, 2023



The goal of this work is to understand the way actions are performed in videos. That is, given a video, we aim to predict an adverb indicating a modification applied to the action (e.g. cut "finely"). We cast this problem as a regression task. We measure textual relationships between verbs and adverbs to generate a regression target representing the action change we aim to learn. We test our approach on a range of datasets and achieve state-of-the-art results on both adverb prediction and antonym classification. Furthermore, we outperform previous work when we lift two commonly assumed conditions: the availability of action labels during testing and the pairing of adverbs as antonyms. Existing datasets for adverb recognition are either noisy, which makes learning difficult, or contain actions whose appearance is not influenced by adverbs, which makes evaluation less reliable. To address this, we collect a new high quality dataset: Adverbs in Recipes (AIR). We focus on instructional recipes videos, curating a set of actions that exhibit meaningful visual changes when performed differently. Videos in AIR are more tightly trimmed and were manually reviewed by multiple annotators to ensure high labelling quality. Results show that models learn better from AIR given its cleaner videos. At the same time, adverb prediction on AIR is challenging, demonstrating that there is considerable room for improvement.
An Action Is Worth Multiple Words: Handling Ambiguity in Action Recognition
Oct 10, 2022



Precisely naming the action depicted in a video can be a challenging and oftentimes ambiguous task. In contrast to object instances represented as nouns (e.g. dog, cat, chair, etc.), in the case of actions, human annotators typically lack a consensus as to what constitutes a specific action (e.g. jogging versus running). In practice, a given video can contain multiple valid positive annotations for the same action. As a result, video datasets often contain significant levels of label noise and overlap between the atomic action classes. In this work, we address the challenge of training multi-label action recognition models from only single positive training labels. We propose two approaches that are based on generating pseudo training examples sampled from similar instances within the train set. Unlike other approaches that use model-derived pseudo-labels, our pseudo-labels come from human annotations and are selected based on feature similarity. To validate our approaches, we create a new evaluation benchmark by manually annotating a subset of EPIC-Kitchens-100's validation set with multiple verb labels. We present results on this new test set along with additional results on a new version of HMDB-51, called Confusing-HMDB-102, where we outperform existing methods in both cases. Data and code are available at https://github.com/kiyoon/verb_ambiguity
BRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
Jul 22, 2022



Generative models for audio-conditioned dance motion synthesis map music features to dance movements. Models are trained to associate motion patterns to audio patterns, usually without an explicit knowledge of the human body. This approach relies on a few assumptions: strong music-dance correlation, controlled motion data and relatively simple poses and movements. These characteristics are found in all existing datasets for dance motion synthesis, and indeed recent methods can achieve good results.We introduce a new dataset aiming to challenge these common assumptions, compiling a set of dynamic dance sequences displaying complex human poses. We focus on breakdancing which features acrobatic moves and tangled postures. We source our data from the Red Bull BC One competition videos. Estimating human keypoints from these videos is difficult due to the complexity of the dance, as well as the multiple moving cameras recording setup. We adopt a hybrid labelling pipeline leveraging deep estimation models as well as manual annotations to obtain good quality keypoint sequences at a reduced cost. Our efforts produced the BRACE dataset, which contains over 3 hours and 30 minutes of densely annotated poses. We test state-of-the-art methods on BRACE, showing their limitations when evaluated on complex sequences. Our dataset can readily foster advance in dance motion synthesis. With intricate poses and swift movements, models are forced to go beyond learning a mapping between modalities and reason more effectively about body structure and movements.
Rescaling Egocentric Vision
Jun 23, 2020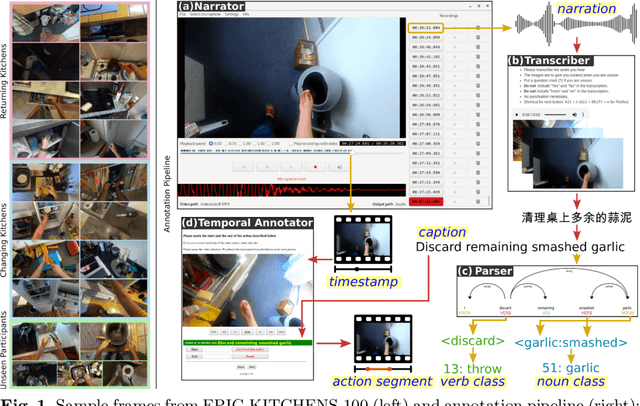
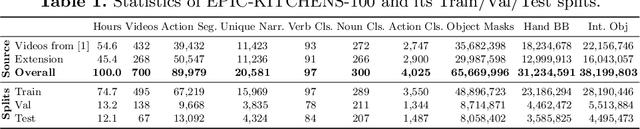
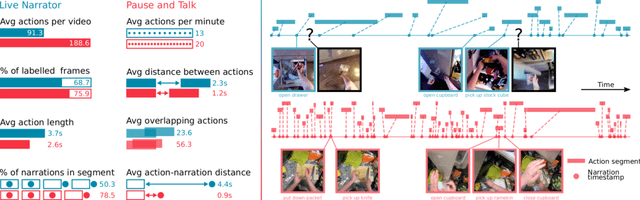
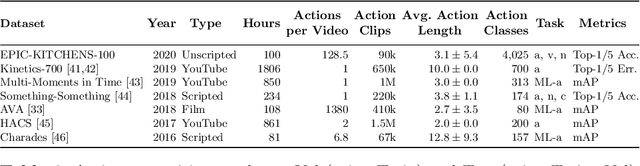
This paper introduces EPIC-KITCHENS-100, the largest annotated egocentric dataset - 100 hrs, 20M frames, 90K actions - of wearable videos capturing long-term unscripted activities in 45 environments. This extends our previous dataset (EPIC-KITCHENS-55), released in 2018, resulting in more action segments (+128%), environments (+41%) and hours (+84%), using a novel annotation pipeline that allows denser and more complete annotations of fine-grained actions (54% more actions per minute). We evaluate the "test of time" - i.e. whether models trained on data collected in 2018 can generalise to new footage collected under the same hypotheses albeit "two years on". The dataset is aligned with 6 challenges: action recognition (full and weak supervision), detection, anticipation, retrieval (from captions), as well as unsupervised domain adaptation for action recognition. For each challenge, we define the task, provide baselines and evaluation metrics. Our dataset and challenge leaderboards will be made publicly available.
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Apr 29, 2020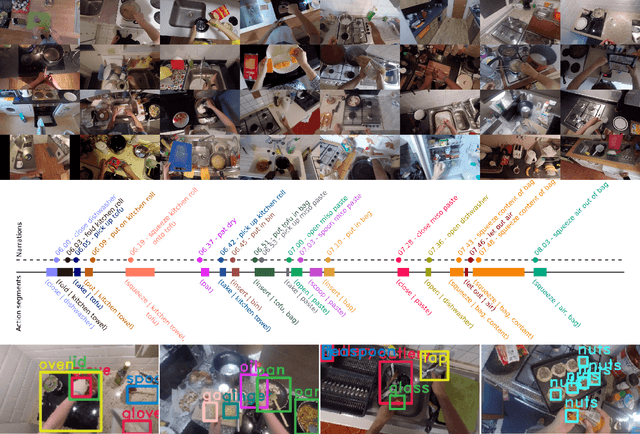
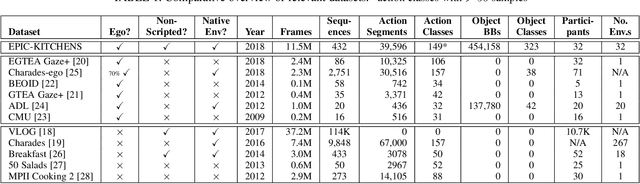

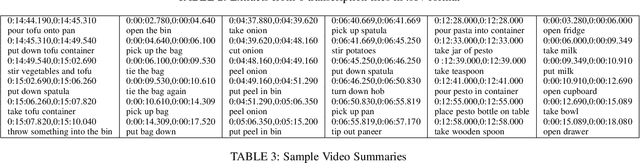
Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.
Action Recognition from Single Timestamp Supervision in Untrimmed Videos
Apr 09, 2019
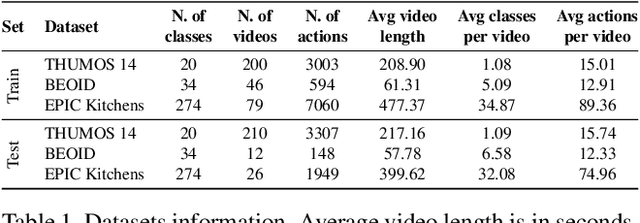

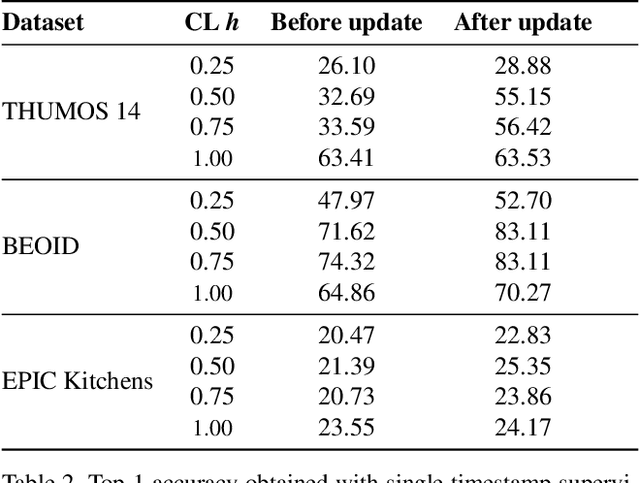
Recognising actions in videos relies on labelled supervision during training, typically the start and end times of each action instance. This supervision is not only subjective, but also expensive to acquire. Weak video-level supervision has been successfully exploited for recognition in untrimmed videos, however it is challenged when the number of different actions in training videos increases. We propose a method that is supervised by single timestamps located around each action instance, in untrimmed videos. We replace expensive action bounds with sampling distributions initialised from these timestamps. We then use the classifier's response to iteratively update the sampling distributions. We demonstrate that these distributions converge to the location and extent of discriminative action segments. We evaluate our method on three datasets for fine-grained recognition, with increasing number of different actions per video, and show that single timestamps offer a reasonable compromise between recognition performance and labelling effort, performing comparably to full temporal supervision. Our update method improves top-1 test accuracy by up to 5.4%. across the evaluated datasets.