 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment of Untruth: Dealing with Negative Queries in Video Moment Retrieval
Feb 12, 2025Video Moment Retrieval is a common task to evaluate the performance of visual-language models - it involves localising start and end times of moments in videos from query sentences. The current task formulation assumes that the queried moment is present in the video, resulting in false positive moment predictions when irrelevant query sentences are provided. In this paper we propose the task of Negative-Aware Video Moment Retrieval (NA-VMR), which considers both moment retrieval accuracy and negative query rejection accuracy. We make the distinction between In-Domain and Out-of-Domain negative queries and provide new evaluation benchmarks for two popular video moment retrieval datasets: QVHighlights and Charades-STA. We analyse the ability of current SOTA video moment retrieval approaches to adapt to Negative-Aware Video Moment Retrieval and propose UniVTG-NA, an adaptation of UniVTG designed to tackle NA-VMR. UniVTG-NA achieves high negative rejection accuracy (avg. $98.4\%$) scores while retaining moment retrieval scores to within $3.87\%$ Recall@1. Dataset splits and code are available at https://github.com/keflanagan/MomentofUntruth
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025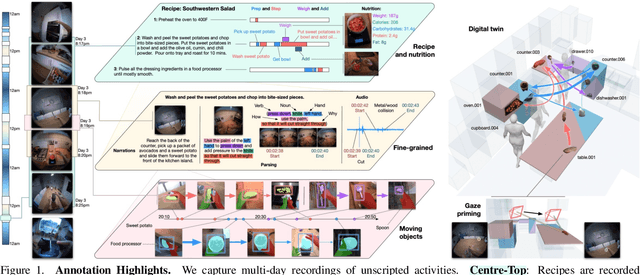
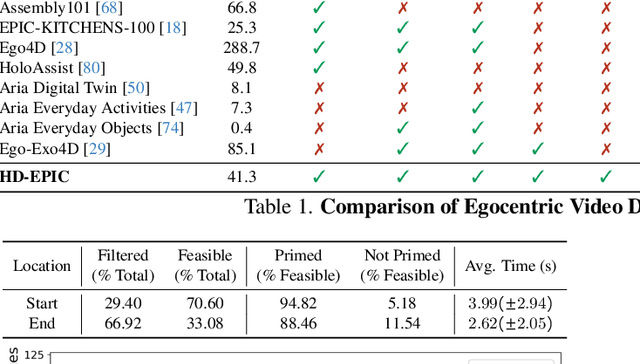

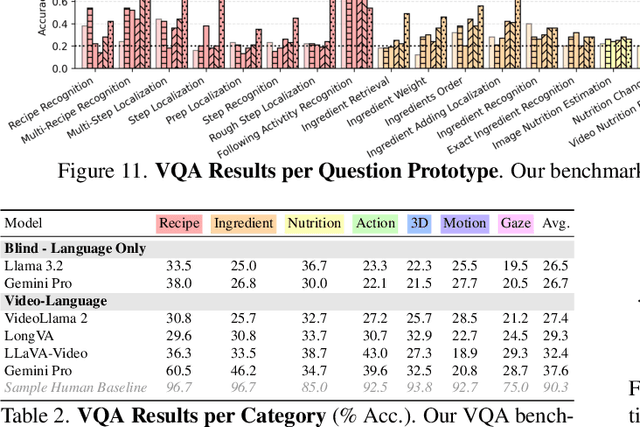
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Video Editing for Video Retrieval
Feb 04, 2024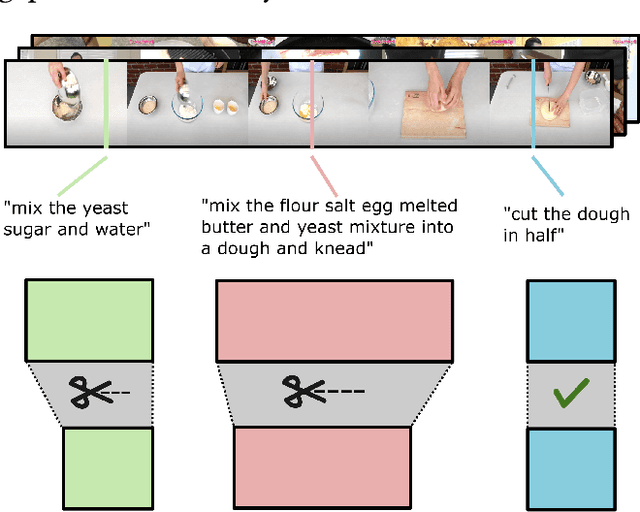
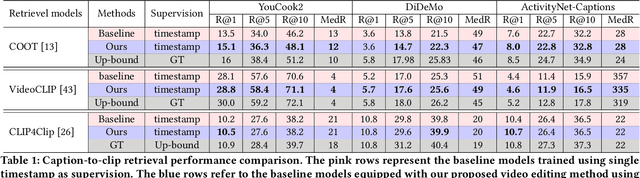
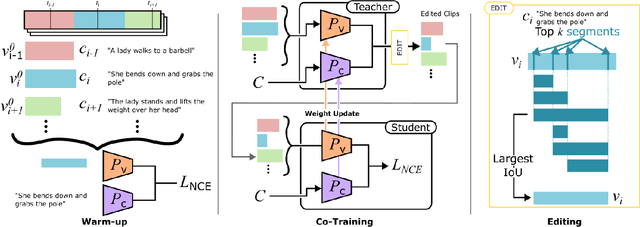
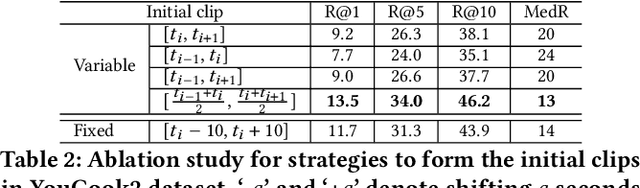
Though pre-training vision-language models have demonstrated significant benefits in boosting video-text retrieval performance from large-scale web videos, fine-tuning still plays a critical role with manually annotated clips with start and end times, which requires considerable human effort. To address this issue, we explore an alternative cheaper source of annotations, single timestamps, for video-text retrieval. We initialise clips from timestamps in a heuristic way to warm up a retrieval model. Then a video clip editing method is proposed to refine the initial rough boundaries to improve retrieval performance. A student-teacher network is introduced for video clip editing. The teacher model is employed to edit the clips in the training set whereas the student model trains on the edited clips. The teacher weights are updated from the student's after the student's performance increases. Our method is model agnostic and applicable to any retrieval models. We conduct experiments based on three state-of-the-art retrieval models, COOT, VideoCLIP and CLIP4Clip. Experiments conducted on three video retrieval datasets, YouCook2, DiDeMo and ActivityNet-Captions show that our edited clips consistently improve retrieval performance over initial clips across all the three retrieval models.
Learning Temporal Sentence Grounding From Narrated EgoVideos
Oct 26, 2023
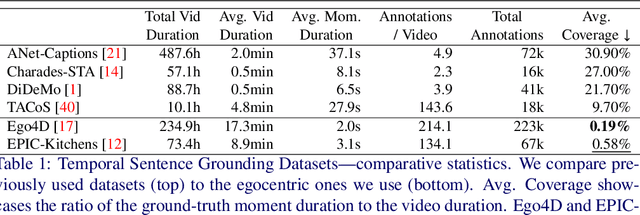
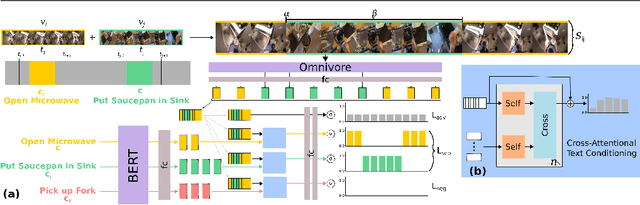

The onset of long-form egocentric datasets such as Ego4D and EPIC-Kitchens presents a new challenge for the task of Temporal Sentence Grounding (TSG). Compared to traditional benchmarks on which this task is evaluated, these datasets offer finer-grained sentences to ground in notably longer videos. In this paper, we develop an approach for learning to ground sentences in these datasets using only narrations and their corresponding rough narration timestamps. We propose to artificially merge clips to train for temporal grounding in a contrastive manner using text-conditioning attention. This Clip Merging (CliMer) approach is shown to be effective when compared with a high performing TSG method -- e.g. mean R@1 improves from 3.9 to 5.7 on Ego4D and from 10.7 to 13.0 on EPIC-Kitchens. Code and data splits available from: https://github.com/keflanagan/CliMer